上文介绍了ARM的数据传送指令,本文将主要介绍ARM中的移位、序转和位操作等数据处理指令。
【移位指令】
移位包括逻辑移位和算术移位,所谓“逻辑”就是将寄存器中存放的内容仅仅视为一串bits,移位的时候只需要将这些bits直接左移(LSL - Logical Shift Left)或右移(LSR - Logical Shift Righ)即可,因为寄存器的位宽是固定的,因而有一些bits会被移出寄存器。




如果用上ROR(Rotate Right)这种循环形式的逻辑移位指令,则从LSB移出的bits又会依次进入MSB。既然LSR都有对应的LSL,那ROR是不是也有对应的ROL(Rotate Left)呢?没有,以32位系统为例,循环左移n个bits跟循环右移32-n个bits的效果其实是一样的。


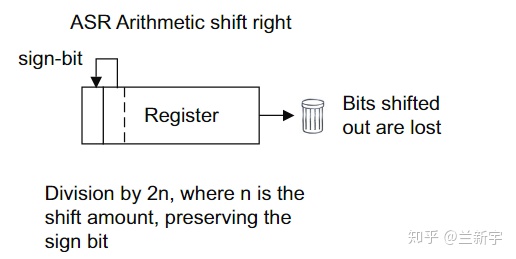
而“算术”则是将寄存器中存放的内容视作一个数值,移位的时候就需要考虑数值的正负问题。在ARM中,只有算术右移(ASR - Arithmetic shift right)指令,没有算术左移指令。在算术右移中,MSB端空出的bit将被代表符号的MSB补齐,每右移一位的结果相当于除以2。

【数据序转指令】
“数据序转”是指将寄存器中的bits或bytes进行部分交换,交换的形式有很多种,包括反转所有bits的RBIT指令,反转所有bytes的REV指令,在两个16位的half word中分别反转bytes的REV16指令。

其中REV指令应该是用的最多的,因为它可以用于网络传输中Little-Endian(LE)和Big-Endian(BE)之间的转换。在ARMv8中,数据访问(data access)根据系统控制寄存器SCTLR的设定可以是LE或者BE,但取指(instruction fetch)则永远是LE。

在64位系统中,还增加了一个在两个32位的word中分别反转bytes的REV32指令:

【比特的手术刀】
像AND, ORR这样的传统的位操作指令使用频率高,浅显易懂,但如果要实现一些更为复杂的位操作,就需要一些更为专业的指令,比如将一个寄存器的部分bits插入另一个寄存器的指定部分的BFI(Bit Field Insert)指令,或者将这些bits直接提取出来的BFX(Bit Field Extract)指令,还有将指定部分的bits清零的BFC(Bit Field Clear)指令。
比如"BFI W0, W1, #9, #6"就是将W1寄存器LSB端的6个bits插入到W0寄存器从bit 9到bit 14的位置。

写到这里我想起了基因编辑,推荐大家看看王立铭老师的《上帝的手术刀》。
下文将介绍ARM中的无条件跳转指令和有条件跳转指令。
原创文章,转载请注明出处。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)