混洗过程:Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle(混洗过程)。
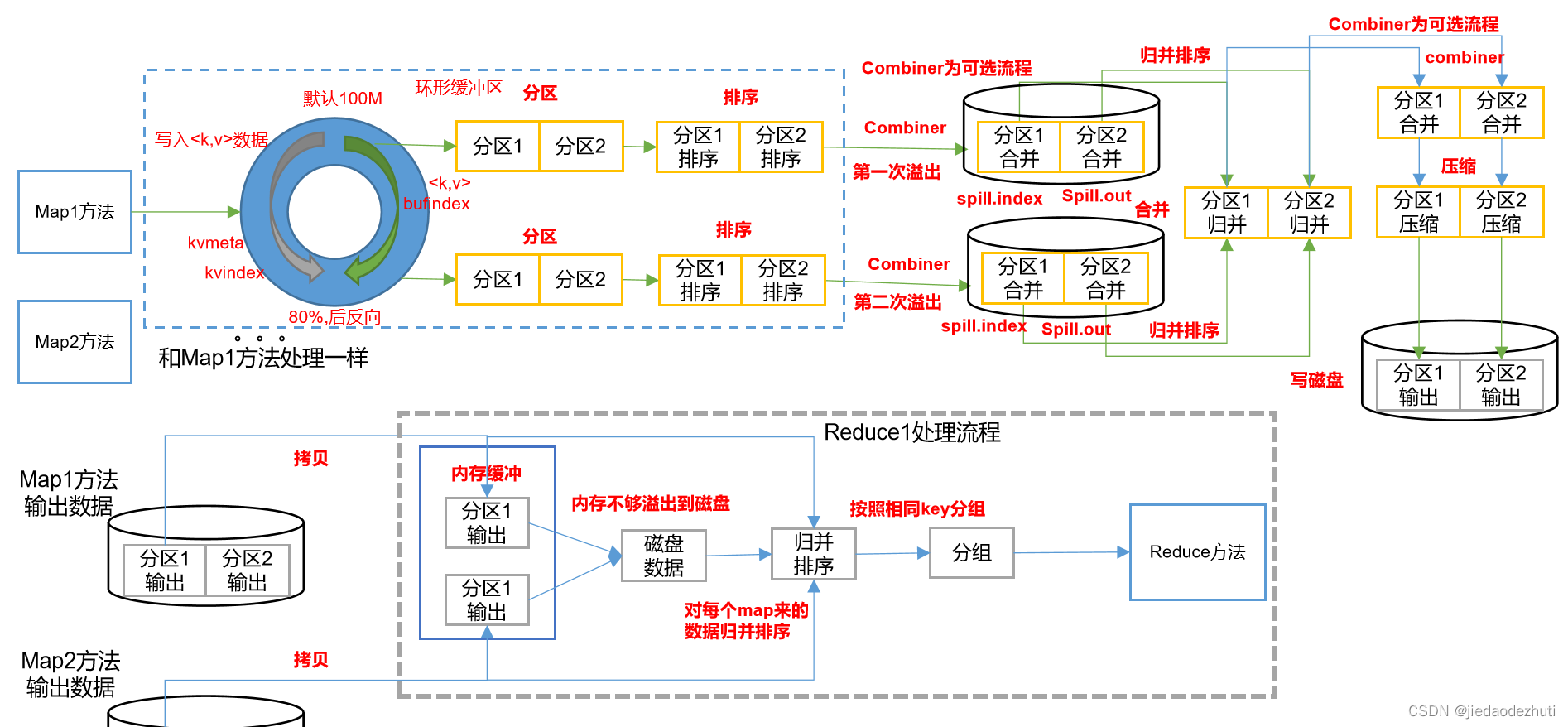
map方法之后,首先进入getpartition方法,标记数据属于那个分区,并打上分区编号,因为后续的数据都是按分区处理。
不同分区数据会进入不同的reduce里面,然后进入环形缓冲区(默然100M),左侧存索引,右侧存数据,当到达80%的时候进行反向溢写,原因是留给溢写时间,不至于等待,让环形缓冲区高效运转,利用率更高。在溢写之前,对数据进行一次排序,排序的手段为快排,是对key的索引按照字典顺序,快排完后进行第一次溢写,溢写文件有两个,一个是spill.index和一个真正落地的文件spill.out。其中,combiner为可选流程,在聚合的场景下是可以使用的,传输到reduce端的数据量减少了。第二次溢写。。。第n次溢写。然后对数据进行归并排序,归并排序后还可以选combiner流程,之后还可以设置它相应的压缩,可减少网络传输内容,传输效率提高(一种优化手段)。之后数据按分区写入磁盘,然后等待reduce端来拉取。
reduce拉取数据之后,先尝试放入内存缓冲,若内存不够,会溢写到磁盘上。最后进行一次大排序,即对每个map来的数据归并排序,还可以按照相同的key分组,相同的key进入reduce方法。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)