CNNS:基于AlexNet的分类任务
- 数据集介绍
- 1. pokeman数据集介绍
- 2. flower数据集介绍
- 超参数对模型的影响
- 1. 激活函数对模型的影响
- (1) 使用`Sigmoid`进行训练
- (2) 使用`tanh`进行训练
- (3) 使用`ReLU`进行训练
- 2. `学习率`对模型的影响
- 3. `batch size`对模型的影响
- 补充
数据集介绍
由于硬件的限制和网络模型的复杂度不是很高,目前我们应用与分类任务验证的数据集用到了pokeman和flower两个数据集,这两个数据集都比较小,相关介绍请参考具体内容。
关于为什么会选择两个数据集?
我们想要通过数据集的大小去验证数据集对模型训练的影响。当然,我们也可以对已有的数据集进行数据集增强,我们在后续的实验过程中将对两个不同的数据集都进行数据集大小不同对模型训练影响进行验证。
pokenman数据集百度网盘下载:
https://pan.baidu.com/s/1Yro67aY4PF4qoaUM2Zu5fQ?pwd=jjjj
提取码:jjjj
flower数据集百度网盘下载:
链接:https://pan.baidu.com/s/1EW-VMHbDDQTTA83sigtEpQ?pwd=jjjj
提取码:jjjj
1. pokeman数据集介绍
pokeman数据集有五类,分别是bulbasaur、charmander、mewtwo、pikachu、和squirtle。其中每一类大约是235左右张图片,图片的格式为.png和jpg。

2. flower数据集介绍
flower数据集有五类,分别是daisy、dandelion、roses、sunflowers、和tulips。其中每一类包含的图片640张以上,图片的格式为jpg。

超参数对模型的影响
1. 激活函数对模型的影响
在AlexNet之前,激活函数一般都是用Sigmoid函数以及tanh函数。接下来我们将对激活函数Sigmoid、tanh和ReLU进行简单分析(关于其他的激活函数,待我们在具体使用的模型中进行探讨)。
(1) Sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x) = \frac{1}{1+e^{-x}}
σ(x)=1+e−x1
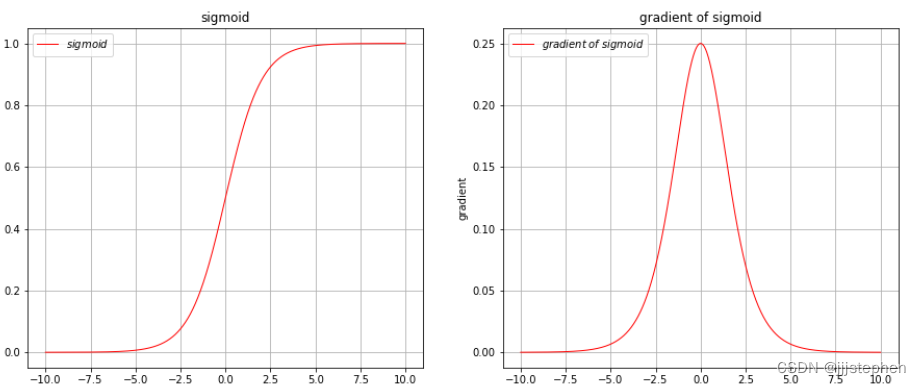
Sigmoid函数优点:
- 它是一个光滑的函数,导数可计算,且具有单调可微性。
Sigmoid函数的输出值在0到1之间,可以看作是概率值,适合进行分类任务。
Sigmoid函数缺点:
Sigmoid函数的导数在函数值接近饱和区时会变得非常小,这意味着梯度下降的步长也会变得非常小,从而导致训练过程缓慢。Sigmoid函数的输出并不是以0为中心的,这会导致在反向传播时梯度的传递存在问题,从而影响模型的训练效果。- 当输入很大或很小时,Sigmoid函数的输出接近于0或1,这种情况被称为饱和,这会导致梯度消失或梯度爆炸的问题,进而影响模型的训练效果。
(2) tanh函数
t
a
n
h
(
x
)
=
s
i
n
h
(
x
)
c
o
s
h
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
tanh(x)=\frac{sinh(x)}{cosh(x)}=\frac{e^x-e^{-x}}{e^x+e^{-x}}
tanh(x)=cosh(x)sinh(x)=ex+e−xex−e−x
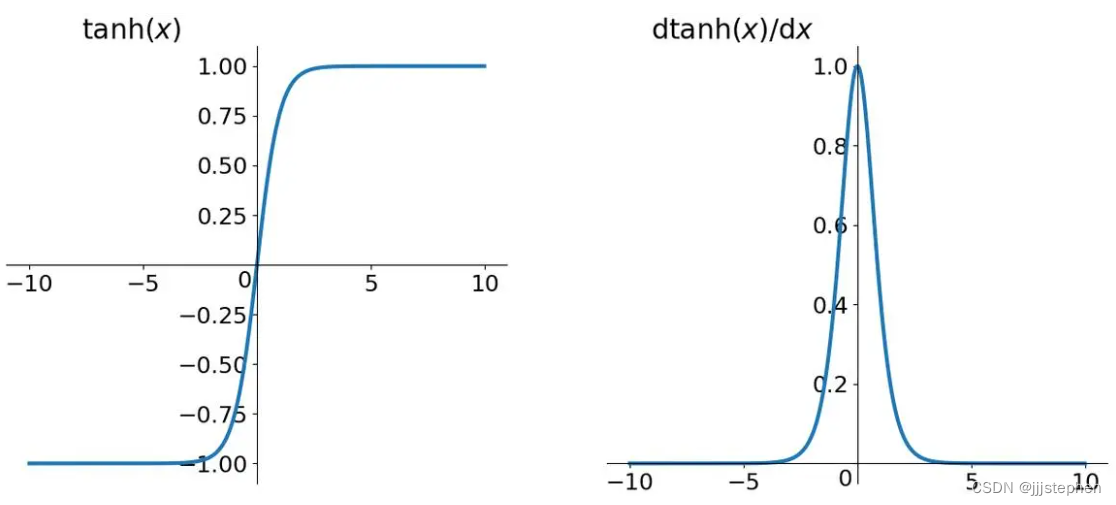
Tanh作为一种激活函数,与Sigmoid类似,也是一种S型函数。Tanh相比于Sigmoid有以下优缺点:
Tanh优点:
Tanh的输出范围是[-1,1],相比于Sigmoid的[0,1],中心化更明显,因此Tanh可以在数据正负对称的情况下有更好的表现。Tanh在输入为负数的情况下会输出负数,可以更好的表达负数的影响,而Sigmoid在输入为负数时输出接近0,不够敏感。Tanh的导数比Sigmoid的更加陡峭,更加容易在梯度下降时达到收敛。
Tanh缺点:
- 与
Sigmoid类似,Tanh也存在梯度消失的问题。当输入的值过大或过小时,其梯度值会趋近于0,导致神经网络难以进行优化。 Tanh的计算量比Sigmoid稍大,因此在计算速度要求高的场景下,可能不太适合使用。
综上所述,Tanh相比于Sigmoid在梯度下降时更容易达到收敛,并且可以在数据正负对称的情况下表现更好,但仍然存在梯度消失和计算量较大的问题。在实际应用中,需要根据具体情况选择适合的激活函数。
(3) ReLU函数
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x) = max(0, x)
f(x)=max(0,x)
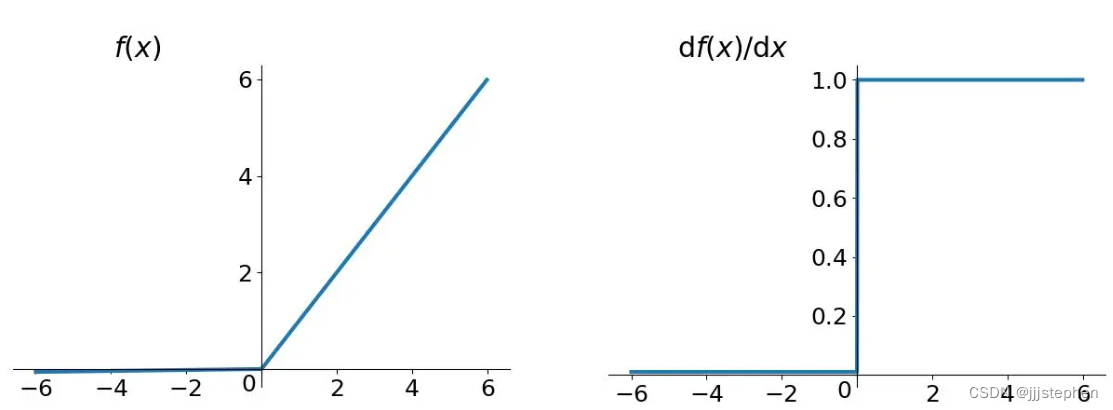
ReLU优点:
- 加速模型收敛速度:
ReLU在x>0时的导数为常数1,而在x<0时的导数为0,这使得神经网络训练时误差反向传播时的计算量大大降低,加速了模型收敛速度。 - 稀疏性:由于
ReLU在负数部分输出为0,因此可以使得一部分神经元的输出为0,产生稀疏性,减少参数的计算量和存储量,避免过拟合。 - 有效解决梯度消失问题:由于
ReLU在x>0时梯度为常数1,因此能够很好地缓解梯度消失的问题。
ReLU缺点:
- 死亡
ReLU问题:由于ReLU在x<0时输出为0,因此当某个神经元输出一直为负数时,就会导致梯度一直为0,这个神经元就不再对输入数据产生响应,称为“死亡ReLU”,这会影响模型的表达能力。 - 输出不是零中心:
ReLU在负数部分的输出为0,因此其输出不是以0为中心的,这会影响模型的训练效果,导致某些神经元可能无法收敛。 - 对噪声敏感:
ReLU在x<0时输出为0,因此对于输入数据中的噪声,会产生很大的影响,使得噪声被强制映射到0处。
实验中,数据集使用了pokeman,训练集和测试集的占比分别为80%和20%。epoch为100,learning rate = 0.01(此时,我们标记为策略1)。
lr = 0.01
epochs = 150
batch_size = 8
(1) 使用Sigmoid进行训练

使用Sigmoid激活函数,可以看到模型在训练过程中error收敛比较理想,但是训练集和测试集的效果都不好,出现了欠拟合现象。
(2) 使用tanh进行训练
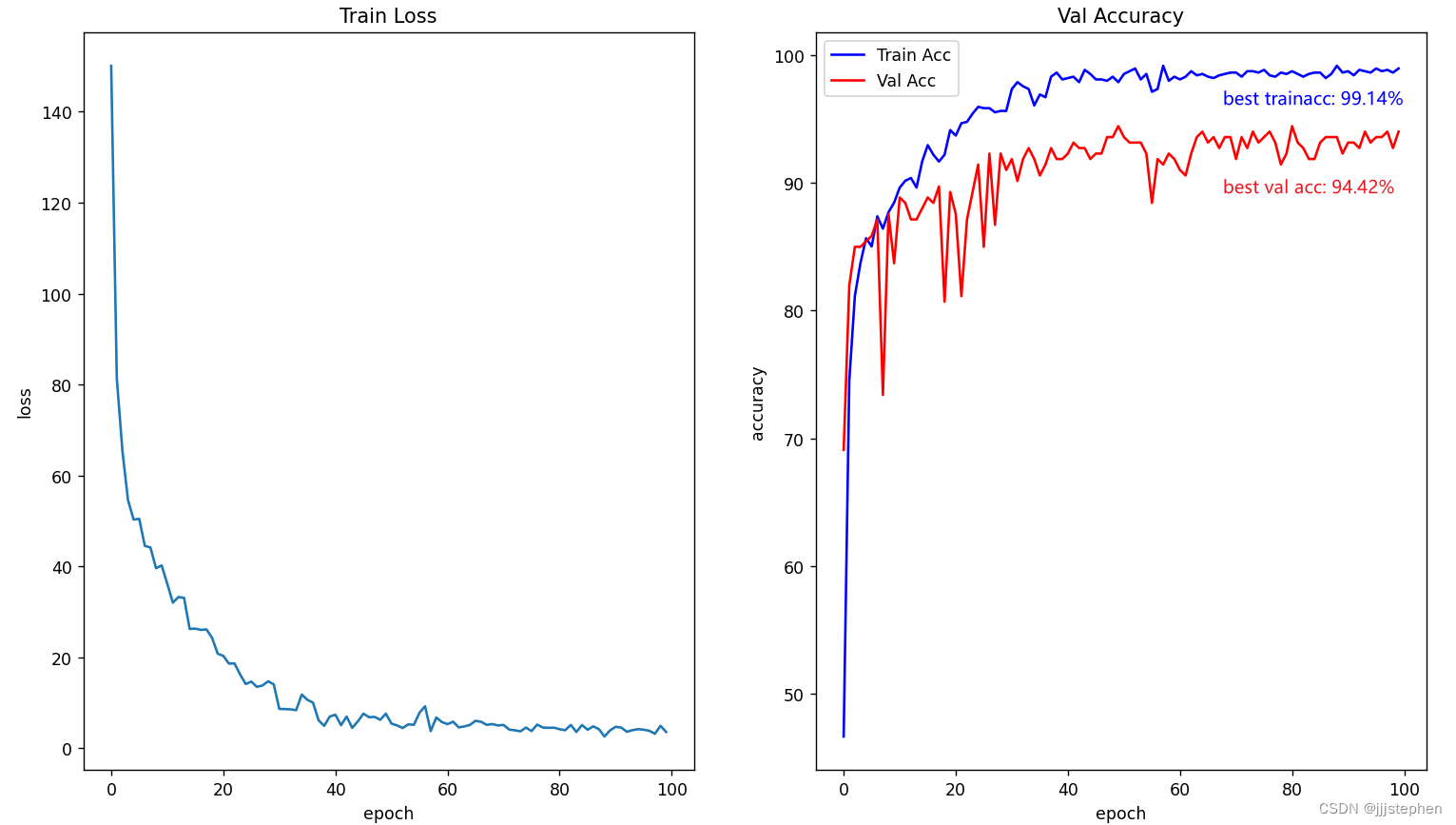
(3) 使用ReLU进行训练
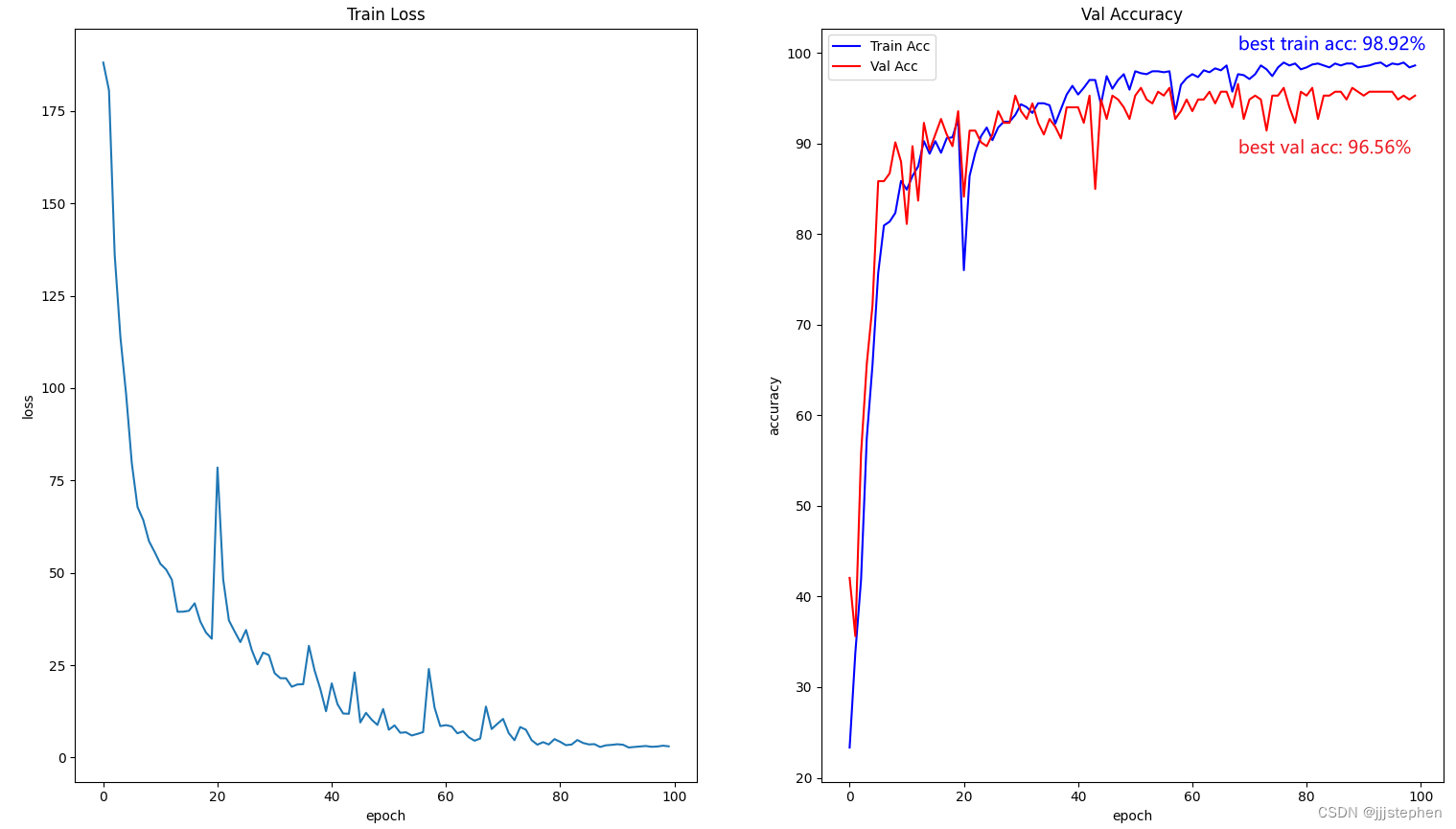
综上,使用激活函数tanh时,模型的error相对ReLU来说收敛较好(其他参数不变的情况下),激活函数Sigmoid 使用很不乐观。对于训练精度和测试精度来说,使用激活函数ReLU比tanh相对较好。但是激活函数ReLU在模型中使用,error收敛过程并不理想,我们可以通过调整学习率learning rate进行调整。
声明:我们现有的实验结果精度并不算高,这其中之一的原因是因为数据集太少(测试集和训练集)。
2. 学习率对模型的影响
学习率是深度学习中一个重要的超参数,它决定了参数在每一次更新中的变化程度。学习率的大小直接影响着模型的训练效果,如果学习率过大或者过小都会对训练过程产生负面影响。
当学习率过大时,会导致参数的更新过于剧烈,可能会错过局部最优解,而且可能导致损失函数震荡甚至爆炸,使得模型无法收敛。这种情况下可以采用学习率衰减等策略来降低学习率,使得参数更新的幅度逐渐减小。
当学习率过小时,会导致参数更新的速度变慢,训练时间会变得很长,而且可能会陷入到局部最优解中无法跳出。这种情况下可以采用增大学习率或使用自适应学习率的方法。
一般来说,学习率的选取需要根据具体的问题进行调整,常用的方法有手动调节、学习率衰减、自适应学习率等。在实践中需要结合具体情况进行选择,不断地调整学习率以获得最好的训练效果。
本节,我们将针对策略1得出的结论,使用激活函数ReLU进行调整参数学习率。我们可以看到当lr=0.01时,error收敛在epoch在20左右并不好,首先我们对lr的调整策略(策略2)为:
epoch <= 18, lr = 0.01
epoch > 18, lr = 0.005
epochs = 150
batch_size = 8
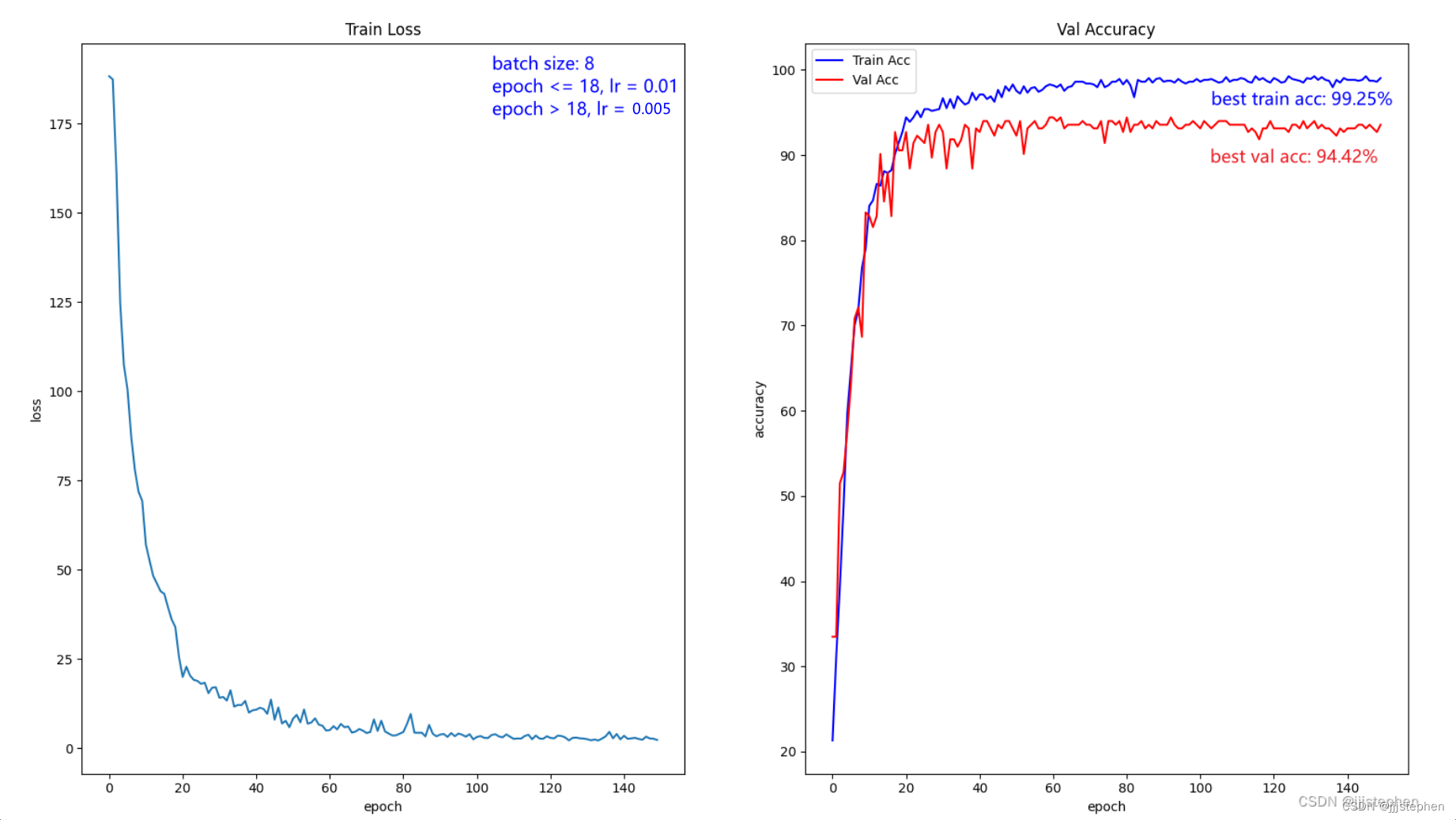
我们针对策略2,损失error收敛过程中,在epoch为20以后,仍有小幅度的震荡,因此再一步进行调整(策略3):
epoch <= 18, lr = 0.01
epoch > 18, lr = 0.003
epochs = 150
batch_size = 8

由实验结果可以看到,此时(策略2)的效果已经达到了我们的预期(策略3的效果也比较好)。当然,我们也探索了其相反的方向,即在epoch大于16时,lr取0.8,其损失error收敛效果相较于策略1更差。
3. batch size对模型的影响
batch size 的大小会影响深度学习模型的训练精度。具体来说,batch size 的大小会影响以下几个方面:
- 训练速度:
batch size 越大,每个 epoch中需要的迭代次数就越少,从而训练速度就越快。但是,如果 batch size 超过了 GPU 或 CPU 的内存容量,就会导致程序崩溃或训练速度变慢。 - 模型泛化能力:
batch size 越大,模型的泛化能力通常会越好,因为每个 batch 中的样本更加多样化,可以更好地表示整个数据集的特征。但是,如果 batch size 过大,就可能会导致模型过拟合,因为模型只学习到了局部的特征而没有充分学习整个数据集的特征。 - 训练精度:
batch size 的大小也会影响训练精度。一般来说,较小的 batch size 可以帮助模型更好地学习数据集的细节特征,从而提高训练精度。但是,如果 batch size 太小,就可能会导致模型无法充分利用 GPU 或 CPU 的计算资源,从而训练速度变慢,甚至无法收敛。
因此,在选择 batch size 大小时,需要综合考虑以上几个方面,根据具体的情况选择合适的 batch size 大小。
较小的 batch size 可以帮助模型更好地学习数据集的细节特征,这是因为:
- 较小的
batch size 使得模型在训练时可以看到更多的样本,每个样本都被独立处理,可以更好地掌握数据集的细节特征,如图像中的纹理、边缘等。相比之下,较大的 batch size 可能包含大量相似的样本,导致模型只学习到一些共性的特征,而忽略了一些细节信息。 - 较小的
batch size 也可以增加模型的随机性,这有助于模型避免陷入局部最优解。因为每个 batch 中的样本都是随机抽样的,所以不同的 batch 中包含的样本是不同的,这可以使得模型更全面地学习数据集的特征,而不是陷入到某个局部最优解中。
由本章第二节内容可知,我们在实验过程中我们采用策略2比较好,所以,基于策略2的基础上,我们进行探索batch size对模型的影响。
首先,我们的超参数为(此时,我们标记为策略4):
epoch <= 18, lr = 0.01
epoch > 18, lr = 0.005
epochs = 150
batch_size = 16
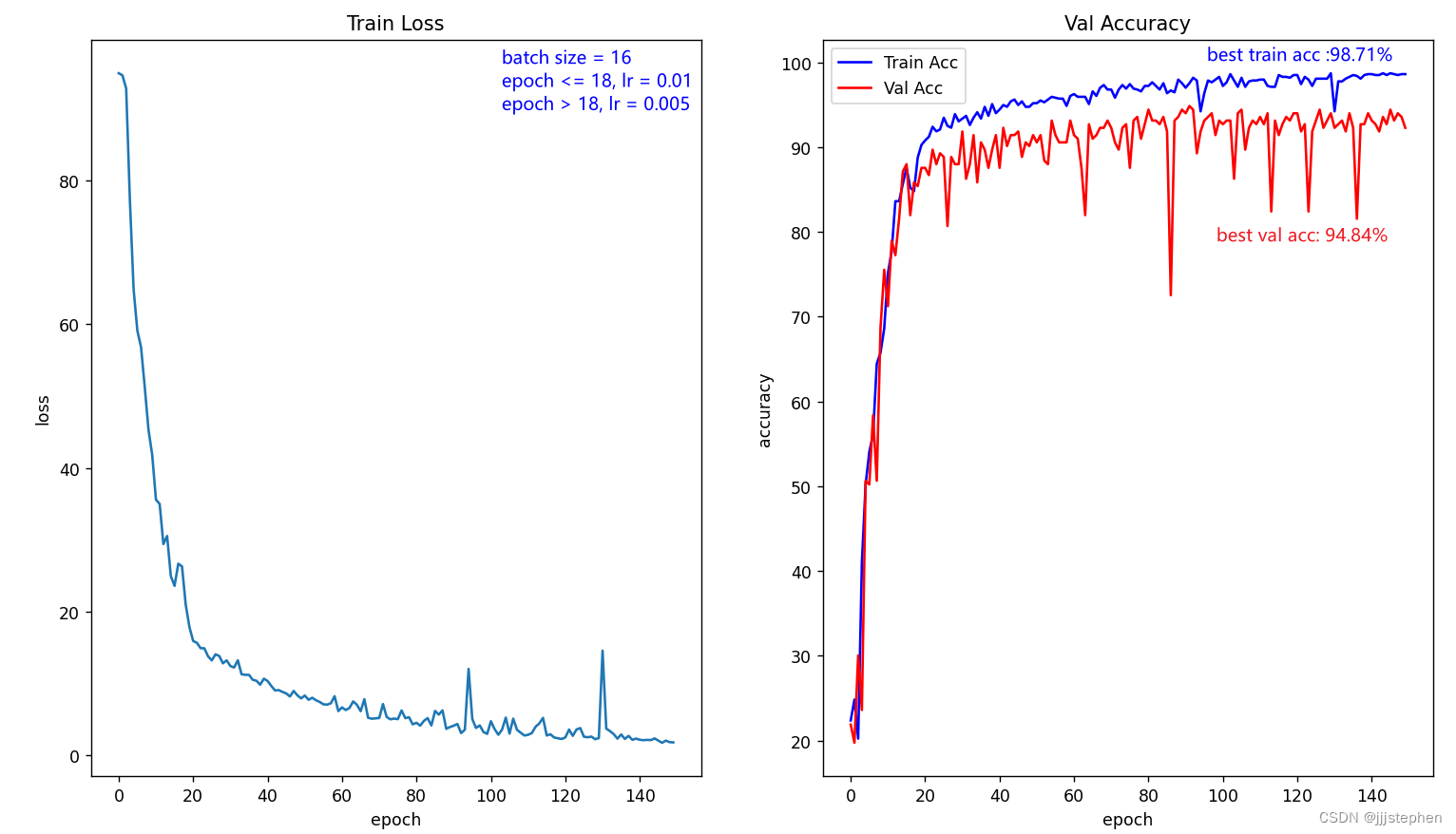
通过实验发现,在在epoch大于50时,损失error出现了震荡。针对以上做进一步调整:
epoch <= 18, lr = 0.01
epoch > 18 ,lr = 0.003
epochs = 150
batch_size = 16

由实验发现,此时损失error没有达到收敛,所以我们调整超参数epoch:
epoch <= 18, lr = 0.01
epoch > 18 ,lr = 0.003
epochs = 200
batch_size = 16
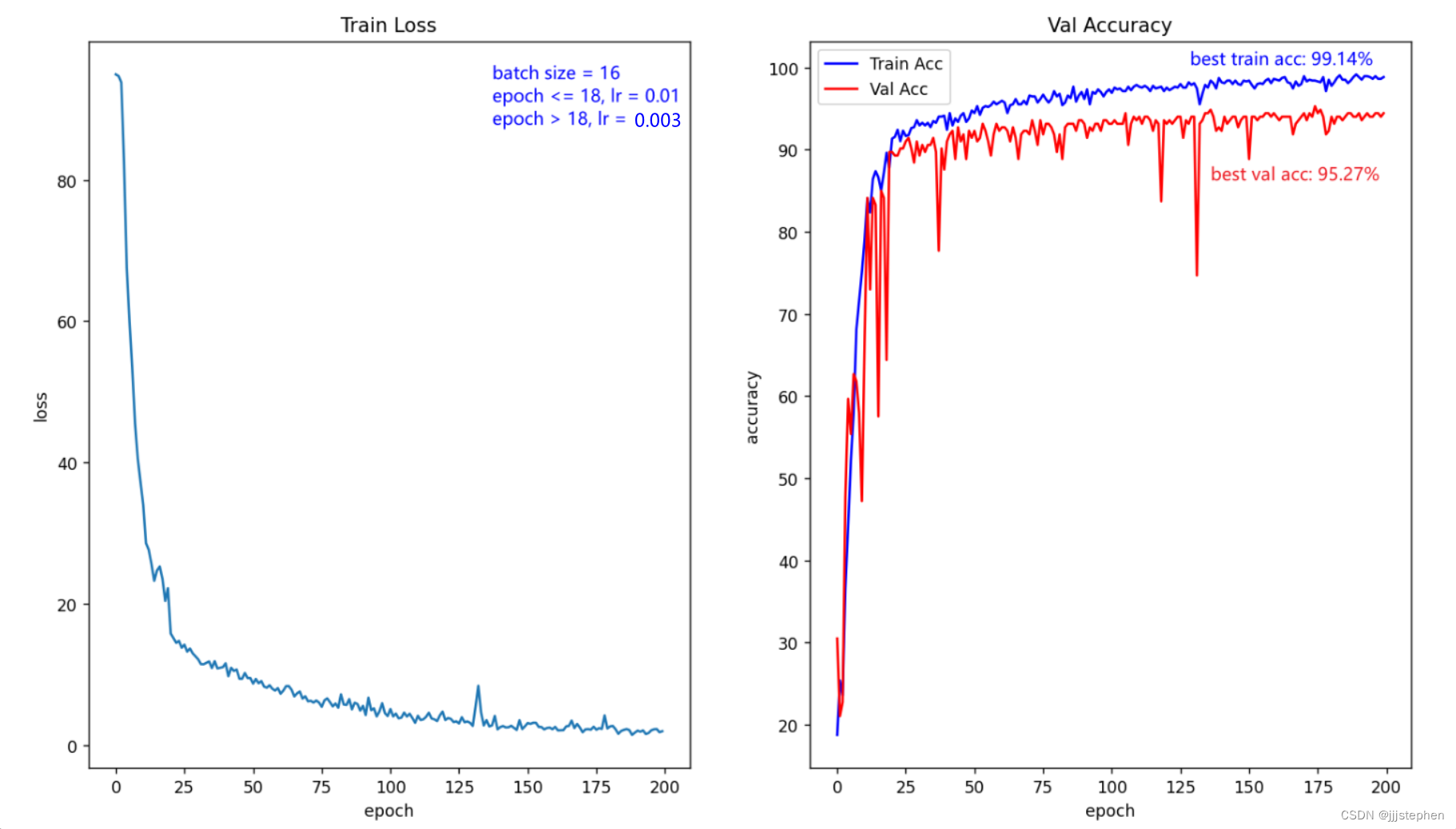
由实验可以看到,随着batch size的增大,测试精度有所改善,即验证了合理batch size可以提高模型的泛化能力。但是这里我们需要注意,不是batch size越大越好,这需要结合具体数据集、模型以及各种超参数等因素综合考虑。
同时,由实验数据可以看到,batch size为16时,验证集的精度不一定稳定(当然,我们可以进一步去调整在epoch在100以后的学习率进一步进行调整)。
在实验中,我们使用了batch size = 32进行实验,其他参数一定的情况下,验证集的精度更加不稳定且其验证集的精度低于batch size = 16的验证集的精度。
综上,我们经过调整参数lr和batch size以及激活函数等我们最终认为基于现有的数据集pokeman和AlexNet数据集,其超参数较好的是:
epoch <= 18, lr = 0.01
epoch > 18 ,lr = 0.003
epochs = 150
batch_size = 16
补充
我们在整个实验过程中,没有关注一个很重要的参数时间,这是因为现在的过程并没有去探索在不降低精度的同时优化模型,而是通过调整各个参数去验证模型的能力。
更多请关注微信公众号【Hope Hut】:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)