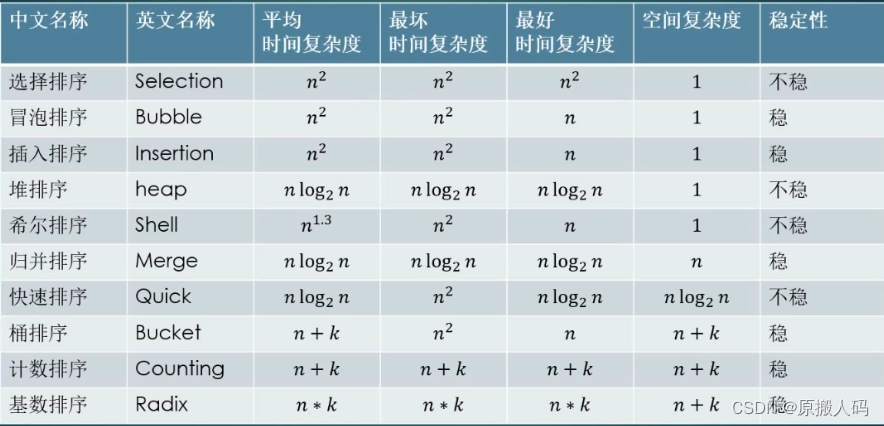
排序算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cTwqfjEg-1652773993433)(D:\Desktop\Java\imag\排序.png)]](https://img-blog.csdnimg.cn/26391f48669a4be79782a1c84062f8a1.png)
常见排序列表:
1.冒泡排序(Bubble Sorting)
package queue;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class Demo3 {
public static void main(String[] args) {
int[] arr = new int[80000];
for(int i=0;i < 80000;i++) {
arr[i] = (int)(Math.random()*80000);
}
Date time1 = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String timePre = sdf.format(time1);
System.out.println("排序前的时间是:"+timePre);
bubbleSort(arr);
Date time2 = new Date();
String timeNex = sdf.format(time2);
System.out.println("排序后的时间是:"+timeNex);
}
public static int[] bubbleSort(int[] num) {
boolean flag = true;
int temp=0;
for(int i=0;i < num.length-1;i++) {
for(int j=0;j < num.length-i-1;j++) {
if(num[j] > num[j+1]) {
flag = false;
temp = num[j];
num[j] = num[j+1];
num[j+1] = temp;
}
}
if(flag) {
break;
}else {
flag = true;
}
}
return num;
}
}
2.选择排序(select sorting)
思路:每次从后面选择最小的放在当前区间的前面
第一次从arr[0]~arr[n-1]中选取最小值,与arr[0]交换, 第二次从arr[1]~arr[n-1]中选取最小值,与arr[1]交换, 第三次从arr[2] arr[n-1]中选取最小值,与arr[2]交换, .,第i次从arr[i-1]' arr[n-1]中选取最小值,与arr[i-1]交换,..第n-1次从arr[n-2]^ arr[n-1]中选取最小值,与arr[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列。
代码演示:
package dataStructure;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class SelectSorting {
public static void main(String[] args) {
int[] arr = new int[80000];
for(int i=0;i < 80000;i++) {
arr[i] = (int)Math.random()*80000;
}
Date time1 = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("测试前时间:"+sdf.format(time1));
selectSort(arr);
Date time2 = new Date();
System.out.println("测试后时间:"+sdf.format(time2));
}
public static void selectSort(int[] arr) {
for(int i=0;i < arr.length-1;i++) {
int index = i;
int min = arr[i];
for(int j=i+1;j < arr.length;j++) {
if(arr[i] > arr[j]) {
index = j;
min = arr[j];
}
}
if(index != i) {
arr[index] = arr[i];
arr[i] = min;
}
}
}
}
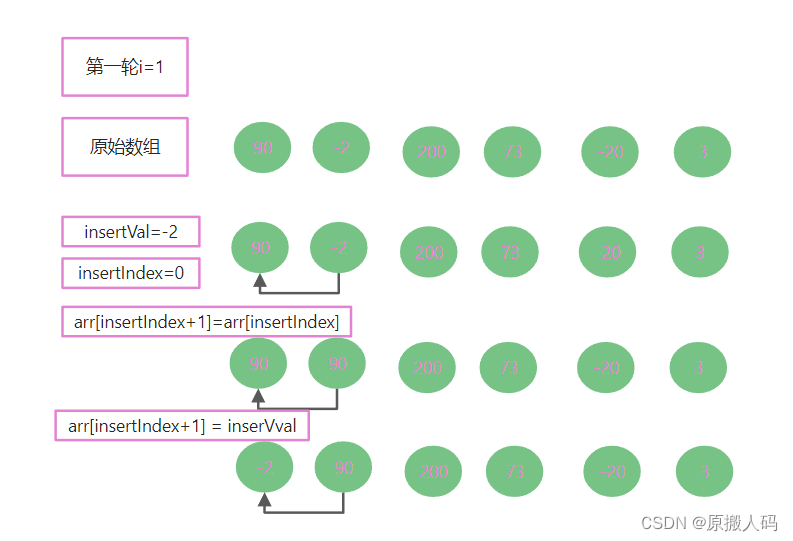
*3.插入排序(insert sorting)
以插入一个元素为例:
package dataStructure;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class InsertSorting {
public static void main(String[] args) {
int[] arr = new int[80000];
for(int i=0;i < 80000;i++) {
arr[i] = (int)Math.random()*80000;
}
Date time1 = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:ms");
System.out.println("测试前时间:"+sdf.format(time1));
insertSort(arr);
Date time2 = new Date();
System.out.println("测试后时间:"+sdf.format(time2));
}
public static void insertSort(int[] arr) {
for(int i=1;i < arr.length;i++) {
int insertVal = arr[i];
int insertIndex = i-1;
while(insertIndex >= 0 && arr[insertIndex] > insertVal) {
arr[insertIndex+1] = arr[insertIndex];
insertIndex--;
}
if(insertIndex+1 != i) {
arr[insertIndex+1] = insertVal;
}
}
}
}
插入排序存在的问题:
当需要对arr = {2,3,4,5,6,1};这样一个数组进行排序时。可以知道需要插入的数据是1,这个过程是:
{2,3,4,5,6,6}
{2,3,4,5,5,6}
{2,3,4,4,5,6}
{2,3,3,4,5,6}
{2,2,3,4,5,6}
{1,2,3,4,5,6}
这样后移的次数明显增多,对效率有影响
为了解决这一问题,提高排序效率。引入希尔排序
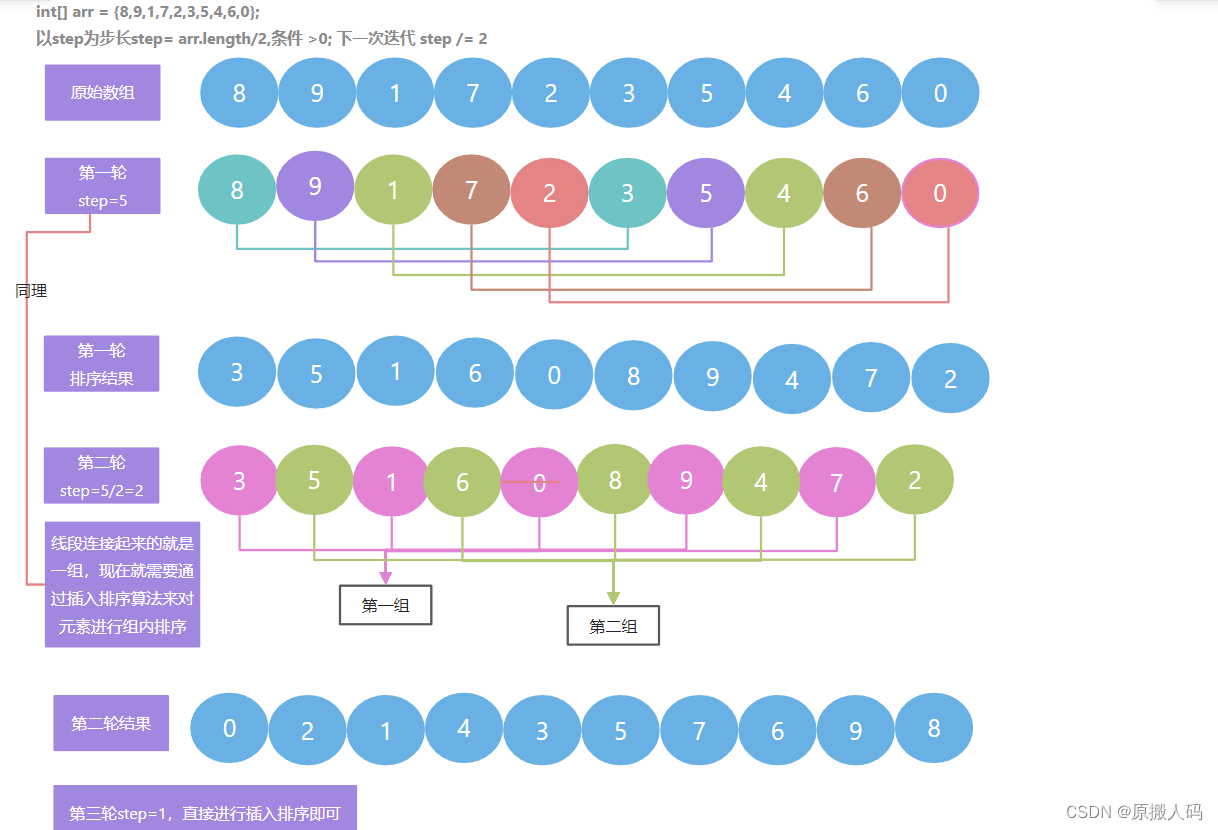
4.希尔排序(Donald Shell)
希尔排序也是一种插入排序,他是简单插入排序改进之后的一个更高效的版本,也称为缩小增量排序
package dataStructure;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class ShallSorting {
public static void main(String[] args) {
int[] arr = new int[80000];
for(int i=0;i < 80000;i++) {
arr[i] = (int)Math.random()*80000;
}
Date time1 = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:ms");
System.out.println("测试前时间:"+sdf.format(time1));
shellSort2(arr);
Date time2 = new Date();
System.out.println("测试后时间:"+sdf.format(time2));
}
public static void shellSort1(int[] arr) {
int temp=0;
for(int step = arr.length/2; step > 0;step /= 2) {
for(int i=step;i < arr.length;i++) {
for(int j=i-step;j >= 0;j -= step) {
if(arr[j] > arr[j+step]) {
temp = arr[j];
arr[j] = arr[j+step];
arr[j+step] = temp;
}
}
}
}
}
public static void shellSort2(int[] arr) {
for(int step = arr.length/2;step > 0;step /=2) {
for(int i=step;i < arr.length;i++) {
int j = i;
int temp = arr[j];
if(arr[j] < arr[j-step]) {
while(j-step >= 0 && temp < arr[j-step]) {
arr[j] = arr[j-step];
j -= step;
}
arr[j] = temp;
}
}
}
}
}
图形分析:
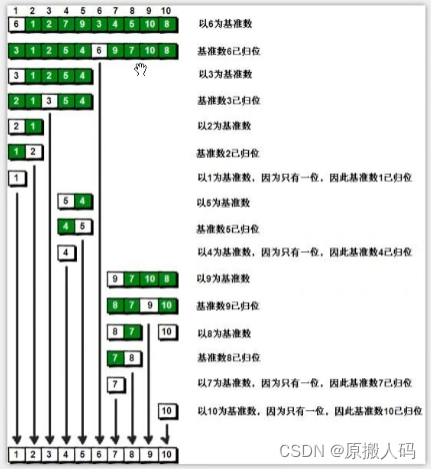
*5.快速排序(Quick Sorting)
快排就是冒泡排序的升级版本
package dataStructure;
import java.util.Arrays;
import java.util.Random;
public class QuickSorting {
public static void main(String[] args) {
int[] arr = new int[100000];
Random r = new Random();
for(int i=0;i<arr.length;i++) {
int num = r.nextInt();
arr[i] = num;
}
long start = System.currentTimeMillis();
quickSortEasy(arr,0,arr.length - 1);
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)+"ms");
}
public static void quickSort(int[] arr,int left,int right) {
int l = left;
int r = right;
int pivot = arr[(left+right)/2];
int temp=0;
while(l < r) {
while(arr[l] < pivot) {
l += 1;
}
while(arr[r] > pivot) {
r -= 1;
}
if(l >= r) break;
temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
if(arr[l] == pivot) r -= 1;
if(arr[r] == pivot) l += 1;
}
if(l == r) {
l += 1;
r -= 1;
}
if(left < r) {
quickSort(arr,left,r);
}
if(right > l) {
quickSort(arr,l,right);
}
}
public static void quickSortEasy(int[] arr,int left,int right) {
if(left > right) {
return;
}
int base = arr[left];
int l = left;
int r = right;
while(l != r) {
while(arr[r] >= base && l < r) {
r--;
}
while(arr[l] <= base && l < r) {
l++;
}
int temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
}
arr[left] = arr[l];
arr[l] = base;
quickSortEasy(arr,left,l - 1);
quickSortEasy(arr,r + 1,right);
}
}
图片演示例子:
*6.归并排序(Merge Sort)
算法思想:分治
package dataStructure;
import java.util.Arrays;
import java.util.Random;
public class MergeSorting {
public static void main(String[] args) {
int[] arr = new int[100000];
Random r = new Random();
for(int i=0;i<arr.length;i++) {
int num = r.nextInt();
arr[i] = num;
}
long start = System.currentTimeMillis();
merge(arr,0,arr.length-1);
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start)+"ms");
}
public static void merge(int[] arr,int left,int right) {
if(left >= right) {
return;
}
int mid = (left+right)>>>1;
merge(arr,left,mid);
merge(arr,mid+1,right);
megerSort(arr,left,mid,right);
}
public static void megerSort(int[] arr,int left,int mid,int right) {
int s1 = left;
int s2 = mid+1;
int[] temp = new int[right-left+1];
int k = 0;
while(s1 <= mid && s2 <= right) {
if(arr[s1] <= arr[s2]) {
temp[k++] = arr[s1++];
}else {
temp[k++] = arr[s2++];
}
}
while(s1 <= mid) {
temp[k++] = arr[s1++];
}
while(s2 <= right) {
temp[k++] = arr[s2++];
}
for(int i = 0;i < temp.length;i++) {
arr[i+left] = temp[i];
}
}
}
7.基数排序
又称桶排序,是一种稳定的排序算法.使用内存换时间的经典算法,它对空间的要求比较高,
基本思想:
将所有待比较数值统一为同样的数位长度, 数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直 到最高位排序完成以后,数列就变成一个有序序列。
图文说明:

代码块:
package dataStructure.sort;
import java.util.Arrays;
public class BucketSorting {
public static void main(String[] args) {
int[] arr = {53,3,5424,888,126,90};
radixSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void radixSort(int[] arr) {
int max = arr[0];
for(int i=1;i < arr.length;i++) {
if(arr[i] > max) {
max = arr[i];
}
}
int len = (max + "").length();
for(int i=0,n=1;i < len;i++,n *= 10) {
int[][] bucket = new int[10][arr.length];
int[] bucketElementCounts = new int[10];
for(int j=0;j < arr.length;j++) {
int digitOfElement = arr[j] / n % 10;
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
int index = 0;
for(int k=0;k < bucketElementCounts.length;k++) {
if(bucketElementCounts[k] != 0) {
for(int l=0;l < bucketElementCounts[k];l++) {
arr[index++] = bucket[k][l];
}
}
}
}
}
}
*8.堆排序——树结构的应用
堆在结构上就是一棵完全二叉树。只是在完全二叉树的基础上有些要求:
大顶堆:每一个树结点的值都大于等于其左右子结点的值,没有规定左右子结点大小规则。(每一棵子树中最大值都是根结点)
小顶堆:每一个树结点的值都小于等于其左右子结点的值。
堆排序一般升序采用大顶堆,降序采用小顶堆
思路:
1.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2.将堆顶元素与末尾元素交换,将最大元素“沉”到数组末端
3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序
代码演示:图文演示:https://www.yuque.com/dubucahaojiusandianban/dfiuh9/qz5fd8/edit,“堆排序”
public class HeapSort {
public static void main(String[] args) {
int[] arr = {20,8,25,10,6,9,30,50,11,80};
heapSort(arr);
}
public static void heapSort(int[] arr) {
int temp = 0;
for(int i=arr.length/2-1;i >= 0;i--) {
adjustHeap(arr,i,arr.length);
}
for(int j=arr.length-1;j > 0;j--) {
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr,0,j);
}
System.out.println(Arrays.toString(arr));
}
public static void adjustHeap(int[] arr,int i,int length) {
int temp = arr[i];
for(int n = i*2+1;n < length;n = n*2+1) {
if(n+1 < length && arr[n] < arr[n+1]) {
n++;
}
if(arr[n] > temp) {
arr[i] = arr[n];
i = n;
}else {
break;
}
}
arr[i] = temp;
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)