这里写目录标题
- 一、任务概述
- 二、实现
- 2.1 ocr识别
-
- 2.2 图形文字精确提取
- 2.3 png转svg
- 2.4 svg转ttf
一、任务概述

任务要求:需要将上述生僻字png图片批量自动转成ttf字体文件,该字体对应的unicode码为图中下半部分对应的16进制值。
整个任务分成几个部分实现:
- OCR识别:识别出图片下半部分对应的16进制数值;
- 图形文字精确提取:提取出图片上半部分精确的文字图形区域;
- png图片转svg: 通过图像处理算法提取上半部分图片的字形轮廓,将其转成svg文件;
- svg转ttf:通过FontForge提供的Python工具实现批量转换;
二、实现
2.1 ocr识别
综合考虑识别精度和CPU推理速度要求,本文使用PaddleOCR实现。
2.1.1 安装环境
python -m pip install paddlepaddle==2.3.0 -i https://mirror.baidu.com/pypi/simple
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
2.1.2 实现脚本
import cv2
import os
import paddlehub as hub
from tools import sim_code
def main():
'''
主函数
'''
img_list = list()
img_dir = './screenshot/25A2C_2625F'
target_width, target_height = 363, 269
for file in os.listdir(img_dir):
if os.path.splitext(file)[1].lower() in '.png|.jpg':
img_list.append(file)
print('当前总图片数量: %d' % len(img_list))
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
index = 0
error_index = 0
for img_path in img_list:
img = cv2.imread(os.path.join(img_dir,img_path),cv2.IMREAD_COLOR)
h, w, _=img.shape
if h != target_height or w != target_width:
img = cv2.resize(img, dsize=(target_width, target_height))
ocrimg = img[170:259,40:310,:]
h,w,_= ocrimg.shape
ocrimg = cv2.copyMakeBorder(ocrimg,2*h,2*h,2*w,2*w, cv2.BORDER_CONSTANT,value=[255,255,255])
result = ocr.recognize_text([ocrimg])
code = result[0]['data']
if len(code)==0:
error_index+=1
cv2.imwrite('error/%d.png' % error_index, img)
continue
code = code[0]["text"].strip()
code = sim_code(code)
if len(code)!=5:
error_index+=1
cv2.imwrite('error/%d.png' % error_index, img)
continue
try:
a = int(code,16)
except Exception as e:
error_index+=1
cv2.imwrite('error/%d.png' % error_index, img)
continue
index += 1
print(img_path+' 识读结果:'+code)
save_path = 'ocr/%s.png' % code
if os.path.exists(save_path):
error_index+=1
cv2.imwrite('error/%d_repeat.png' % error_index, img)
continue
textimg = img
cv2.imwrite(save_path, textimg)
if __name__ == "__main__":
'''
程序入口
'''
main()
其中sim_code函数定义如下:
def sim_code(code):
code = code.strip()
code = code.upper()
code = code.replace("G", "")
code = code.replace("H", "")
code = code.replace("I", "1")
code = code.replace("J", "")
code = code.replace("K", "")
code = code.replace("L", "")
code = code.replace("M", "")
code = code.replace("N", "")
code = code.replace("O", "0")
code = code.replace("P", "")
code = code.replace("Q", "")
code = code.replace("R", "")
code = code.replace("S", "")
code = code.replace("T", "")
code = code.replace("U", "")
code = code.replace("V", "")
code = code.replace("W", "")
code = code.replace("X", "")
code = code.replace("Y", "")
code = code.replace("Z", "")
code = code.replace("0", "0")
return code
识读结果如下图所示:
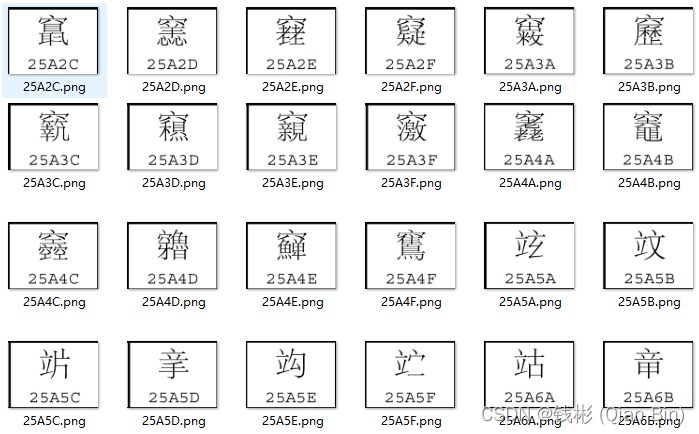
2.2 图形文字精确提取
完整代码如下:
import cv2
import os
import numpy as np
def main():
'''
主函数
'''
img_list = list()
img_dir = './ocr'
target_width, target_height = 363, 269
for file in os.listdir(img_dir):
if os.path.splitext(file)[1].lower() in '.png|.jpg':
img_list.append(file)
print('当前总图片数量: %d' % len(img_list))
index = 0
error_index = 0
for img_path in img_list:
img = cv2.imread(os.path.join(img_dir,img_path),cv2.IMREAD_COLOR)
h, w, _=img.shape
if h != target_height or w != target_width:
img = cv2.resize(img, dsize=(target_width, target_height))
image_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(image_gray, 170, 220, apertureSize=3)
lines = cv2.HoughLines(edges, 1, np.pi / 180, 250)
for line in lines:
rho, theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b))
y1 = int(y0 + 1000 * (a))
x2 = int(x0 - 1000 * (-b))
y2 = int(y0 - 1000 * (a))
cv2.line(img, (x1, y1), (x2, y2), (255, 255, 255), thickness=20)
img = img[5:155,100:270,:]
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,127,255,cv2.THRESH_BINARY_INV)
coords = np.column_stack(np.where(thresh > 0))
coords = np.array(coords, dtype=np.float32)
rect = cv2.boundingRect(coords)
[y, x, h, w] = rect
img = img[y:y+h,x:x+w,:]
h,w,_ = img.shape
if h>w:
pad = int((h-w)/2.0)
img = cv2.copyMakeBorder(img,0,0,pad,pad, cv2.BORDER_CONSTANT,value=[255,255,255])
elif w>h:
pad = int((w-h)/2.0)
img = cv2.copyMakeBorder(img,pad,pad,0,0, cv2.BORDER_CONSTANT,value=[255,255,255])
img = cv2.resize(img, dsize=(128, 128))
img = cv2.copyMakeBorder(img,10,10,10,10, cv2.BORDER_CONSTANT,value=[255,255,255])
code = os.path.splitext(img_path)[0]
save_path = 'crop/%s.png' % code
cv2.imwrite(save_path, img)
index += 1
print(img_path)
if __name__ == "__main__":
'''
程序入口
'''
main()
效果如下图所示:

2.3 png转svg
这里主要通过opencv的形态学操作提取图像轮廓实现转换。
import cv2
import os
def main():
'''主函数'''
img_list = list()
img_dir = './crop'
for file in os.listdir(img_dir):
if os.path.splitext(file)[1].lower() in '.png|.jpg':
img_list.append(file)
print('当前总图片数量: %d' % len(img_list))
index = 0
for img_path in img_list:
textimg = cv2.imread(os.path.join(img_dir,img_path),cv2.IMREAD_COLOR)
textimg = cv2.resize(textimg, dsize=(640, 640))
blur = cv2.GaussianBlur(textimg, (3, 3), 0)
gray = cv2.cvtColor(blur, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 10, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
contours,hierarchy = cv2.findContours(thresh, mode=cv2.RETR_TREE, method=cv2.CHAIN_APPROX_SIMPLE)
epsilon = 10
h, w, _ = textimg.shape
code = os.path.splitext(img_path)[0]
svg_path = 'svg/'+code+'.svg'
with open(svg_path, "w+") as f:
f.write(f'<svg version="1.0" xmlns="http://www.w3.org/2000/svg" width="{w}.000000pt" height="{h}.000000pt" viewBox="0 0 680.000000 680.000000" preserveAspectRatio="xMidYMid meet">')
f.write(f'<g transform="scale(1.00000,1.00000)">')
for c in contours:
f.write('<path d="M')
approx = cv2.approxPolyDP(c,epsilon,False)
for i in range(len(approx)):
x, y = approx[i][0]
if i == len(approx)-1:
f.write(f"{x} {y}")
else:
f.write(f"{x} {y} ")
f.write('"/>')
f.write(f'</g>')
f.write("</svg>")
index +=1
print('当前处理完 %d 张图片' % index)
print('全部处理结束')
if __name__ == "__main__":
'''程序入口'''
main()
部分样例转换结果如下图所示:

2.4 svg转ttf
ttf是专门的字体库文件,目前能够支持ttf编辑的软件并不多。这里推荐使用FontForge,该软件提供了python处理接口,可以使用python脚本批量转换svg到ttf。
首先从官网下载windows版的FontForge并安装,本文将其安装到D盘的toolplace的文件夹中。要使用FontForge提供的python接口,我们必须要使用FontForge的python执行器,这个执行器位于FontForge安装目录的bin文件夹中,完整路径如下图所示:
D:\toolplace\FontForgeBuilds\bin
在这个目录下面有个名为ffpython.exe的可执行文件,这个就是FontForge提供的python执行器。为了能够正常使用这个执行器,我们需要将我们的可执行目录切换到bin文件夹下面,然后创建一个转换脚本main_ttf.py,内容如下:
from time import sleep
import fontforge, os,psMat
def main():
'''
主函数
'''
img_list = list()
img_dir = './svg'
for file in os.listdir(img_dir):
if os.path.splitext(file)[1].lower() in '.svg':
img_list.append(file)
print('当前总图片数量: %d' % len(img_list))
index = 0
for img_path in img_list:
print('当前处理 '+img_path)
codestr = os.path.splitext(img_path)[0]
code = int(codestr,16)
font = fontforge.font()
font.encoding = 'UnicodeFull'
font.version = '1.0'
font.weight = 'Regular'
font.fontname = 'uni'+codestr
font.familyname = 'uni'+codestr
font.fullname = 'uni'+codestr
glyph = font.createChar(code, "uni"+codestr)
glyph.importOutlines(os.path.join(img_dir,img_path))
base_matrix = psMat.translate(0,0)
glyph.transform(base_matrix)
font.generate('./ttf/'+codestr+'.ttf')
index +=1
print('当前处理完 %d 张图片' % index)
os.remove(os.path.join(img_dir,img_path))
print('全部处理结束')
if __name__ == "__main__":
'''
程序入口
'''
main()
然后使用下面的命令执行该脚本:
./ffpython.exe main_ttf.py
最后在当前目录下会生成一个个的ttf文件。
我们可以使用FontForge的客户端查看我们这个生成的字体文件,打开后在菜单栏上选择Encoding-Compact,如下图所示:

可以看到我们已经成功的将png图片批量转换成了ttf文件。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)