1。 序言
首先,我是看这两篇文章的。但是,他们一个写的很笼统,一个是根据Encoder-Decoder和Query(key,value)。第二个讲的太深奥了,绕来绕去,看了两天才知道他的想法。
https://segmentfault.com/a/1190000014574524 这个是讲的很笼统的
https://blog.csdn.net/qq_40027052/article/details/78421155 这个是讲的太深奥的。
本文 的一些基础知识还是基于第二个博客展开。但是我通过两张图可以直接让你明白attention和LSTM在一起的组合。
2. Attention+LSTM
2.1 Attention+LSTM的结构体
以翻译为例

上图就是Attention+LSTM的工作原理了。在这个结构里面,在attention计算注意力分配概率的时候,我选择使用softmax,这是很方便的一个方法,大家也可以选择直接使用归一化的方法,把softmax那一行换成用归一化方法归一化到(0,1)之间。当然也可以用其他方法
关于紫色这一行主要是求相似度的。求相似度也有很多方法,在这里为了表示方便,我具使用内积表示。其他方法也有很多,比如:
- 用内积衡量
- 用一个小型神经网络拟合。
- 可以用余弦相似度计算
到这里,我们再来看一下原始的LSTM的结构是什么样的。

很显然啊,原始LSTM比上述Attention+LSTM少了左上角的那一块,而那一块就是Attention。从第一张图我们可以看出,这个attention就是重新计算这个
h
1
′
{h_{1}}'
h1′。
下面,我们用一个方块表示attention,也就是把第一张图简化:

现在,大家就能看清楚了,在每个
h
i
′
{h_{i}}'
hi′之后呢,其实都是要用一次attention的。
到这里,大家应该都看的都理解的差不多了吧。
3. 用文字解释一下Attention+LSTM
用开头的第二个博客的说法,在没有引入注意力机制的LSTM中,模型在翻译每个单词时,前面的四个隐含层
h
i
{h_{i}}
hi对其影响是一样的。然而事实上,我们不希望他们是一样的,因此提出了attention机制。这个机制其实就是计算相似度,然后使用softmax对其进行归一化。
就是这么简单,至于每一步的公式,我们这里以如下结构为例给出。
原始LSTM的隐含层
h
i
{h_{i}}
hi
紫色部分求当前输出是的隐含层
h
i
′
{h_{i}}'
hi′与前面四个输入隐含层的
h
i
{h_{i}}
hi相似度,我们用余弦相似度计算,既有:
e
i
=
h
′
⋅
h
∥
h
′
∥
∥
h
∥
{e_{i}}=\frac{{h_{}}'\cdot h_{}}{\left \| {h_{}}' \right \|\left \| h_{}\right \|}
ei=∥h′∥∥h∥h′⋅h
在这一步,我们求出当前需要输出被翻译的字的英文名的隐含层与前面输入的所有隐含层之间的相似度的值
e
i
{e_{i}}
ei
下一步,我们使用softmax根据相似度值计算每个隐含层对翻译给单词的贡献:
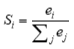
这一步,我们就求出了每个隐含层的贡献度了

然后,我们在根据每个隐含层的贡献度加权求和
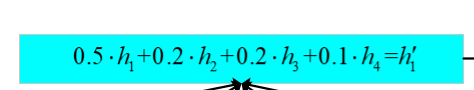
得到当前输出隐含层
h
1
′
{h_{1}}'
h1′的值
4。 用python实现注意力层代码
首先上代码
4.1 attention部分
def attention_3d_block(inputs):
input_dim = int(inputs.shape[2])
a = Permute((2, 1))(inputs)
a = Reshape((input_dim, TIME_STEPS))(a)
a = Dense(TIME_STEPS, activation='softmax')(a)
if SINGLE_ATTENTION_VECTOR:
a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
这里面需要用到的几个函数,我先给解释一下
Permute:这个函数的作用就是行列互换,在这里可以认为是求矩阵inputs转置。
Reshape:同样是调整矩阵的行列,看到这里,是不觉得这一步是多余的?说实话,很多人都认为是多余的。INPUT_DIM = 2,TIME_STEPS = 20,就将其调整为了2行,20列。
Lambda: 官方解释:本函数用以对上一层的输出施以任何Theano/TensorFlow表达式。这里的“表达式”指得就是K.mean,其原型为keras.backend.mean(x, axis=None, keepdims=False),指张量在某一指定轴的均值。
我的解释:什么狗屁的x轴还是y轴的。x轴方向的均值,对于矩阵来讲就是按行求均值。。y轴方向的均值,对于矩阵来讲就是按列求均值。这一定很重要,要记住啊。
RepeatVector:作用为将输入重复n次。这里为什么要重复进行,下面我详细介绍。
详细解释
先看第一个Permute层,由前面数据集的前三个输出我们知道,输入网络的数据的shape是(time_steps, input_dim),即(20,2),这是方便输入到LSTM层里的输入格式。无论注意力层放在LSTM的前面还是后面,最终输入到注意力层的数据shape仍为(time_steps, input_dim)(20,2),对于注意力结构里的Dense层而言,(input_dim, time_steps)(2,20)才是符合的,因此要进行维度变换。
再看第一个Reshape层,可以发现其作用为将数据转化为(input_dim, time_steps)(2,20)。这个操作不是在第一个Permute层就已经完成了吗?没错,实际上这一步操作物理上是无效的,因为格式已经变换好了,但这样做有一个好处,就是可以清楚的知道此时的数据格式,shape的每一个值分别代表什么含义。
接下来是一个Dense层,这个Dense层的激活函数是softmax,显然就是注意力结构里的Dense层,用于计算每个特征的权重。
马上就到SINGLE_ATTENTION_VECTOR值的判断了,现在出现了一个问题,我们的特征在一个时间结点上的维度是多维的(input_dim维),即有可能是多个特征随时间变换一起发生了变换,那对应的,我们的注意力算出来也是多维的。此时,我们会想:是多维特征共享一个注意力权重,还是每一维特征单独有一个注意力权重呢? 这就是SINGLE_ATTENTION_VECTOR值的判断的由来了。SINGLE_ATTENTION_VECTOR=True,则共享一个注意力权重,如果=False则每维特征会单独有一个权重,换而言之,注意力权重也变成多维的了。
下面对当SINGLE_ATTENTION_VECTOR=True时,代码进行分析。Lambda层将原本多维的注意力权重取平均,RepeatVector层再按特征维度复制粘贴,那么每一维特征的权重都是一样的了,也就是所说的共享一个注意力。
接下来就是第二个Permute层,到这步就已经是算好的注意力权重了,我们知道Attention的第二个结构就是乘法,而这个乘法要对应元素相乘,因此要再次对维度进行变换。
最后一个Multiply层,权重乘以输入,注意力层就此完工。
想一想,权重是什么,输入是什么?我们看一下下面图的最上面一行,权重就是下图中softmax计算出来的概率,输入就是
h
i
h_{i}
hi。这下看明白了吗
上面的代码是实现attention部分的
也就是图一中的这一部分

4.2 与LSTM结合
def model_attention_applied_after_lstm():
K.clear_session()
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
在该部分的代码里,我们可以在第三行看到attention_3d_block()这个函数
当我们知道这个函数的输入时,就很清楚的知道Attention-LSTM的运作原理了。
这个时候,我们看的还是云里雾里,现在我们将参数全部带入到函数里
def model_attention_applied_after_lstm():
K.clear_session()
inputs = Input(shape=(20, 2,))
lstm_out = LSTM(32, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
关于LSTM的详细分析,可以参考这个博客。
逐行解释
大家在看代码的时候,一定要在脑子里回想第一张图,并且知道数据的流向。
inputs = Input(shape=(20, 2,))
这一步没什么好说的,输入数据是20行2列。
这个Input不要被他欺骗了,其实他是keras下面的一个函数,注意首字母大写
大家可以看到这个博客。
Input():用来实例化一个keras张量
Input(shape=None,batch_shape=None,name=None,dtype=K.floatx(),sparse=False,tensor=None)
lstm_out = LSTM(32, return_sequences=True)(inputs)
这一步就是调用LSTM了,先把输入数据输入到LSTM网络,这个网络的神经元个数为32个。通过LSTM网络,我们可以去求出来隐含层变量
h
i
h_{i}
hi
继续向下,开始在隐含层后加入attention
attention_mul = attention_3d_block(lstm_out)
这边我需要解释一下,就是我们输入一组向量
下面这一层就很直观了,就是把矩阵拉成平的
attention_mul = Flatten()(attention_mul)
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
output = Dense(1, activation='sigmoid')(attention_mul)
Dense层就是所谓的全连接神经网络层,在这里,因为是回归问题,多输入单输出,所有最后一个全连接层的神经元的个数就是一个。
最后一行啊,关于这个Model这个函数,我还是需要解释一下的
大家可以参考这个博客。
当然,还有另一种使用方式,就是添加在lstm之前
def model_attention_applied_before_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
attention_mul = attention_3d_block(inputs)
lstm_units = 32
attention_mul = LSTM(lstm_units, return_sequences=False)(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
keras让新手最蛋疼的地方就是开发了两个API
Keras通过两个API提供两种计算模型:
- 函数式模型:通过Model类API;
- 顺序式模型:通过Sequential类API;
我个人觉得这个model类API就是为了跟TensorFlow区分才开发的,乍一看很不适应,怎么后面有两个()呢?我草,这是什么?用习惯了才知道,这个model力看着比Sequential明白多了。
model = Model(input=[inputs], output=output)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)