其实我的专业不是数学专业,只不过在阅读paper时,我们会经常看到0范数或者1范数这些范数问题。本文就来分析看看到时什么是范数?什么是0范数、1范数、2范数?它们的区别又是什么?为了方便某些着急的people,先直观的列举:
首先直观的先抛出定义:一般将向量的范数的定义为,
(1)
如果令p=2,则为范数。同时我们知道若已知向量为,则其欧氏范数为,
欧式范式就是范数,它用于表示向量(或矩阵)的大小(算术平方和)。
令公式(1)中的p=0,则得到范数的数学表达式,
范数表示向量中非0元素的个数。在很多范例模型中都会遇到范数,比如压缩感知中,我们遇到凸优化问题的求解,就会遇到这个典型的问题(虽然实际中大多转化为求解范数,下面会讲到什么是范数)。正是因为,所以我们想要直接求解它是十分困难的,这个优化模型在数学上被认为是一个NP-hard问题(什么是NP-hard问题,请看这里https://blog.csdn.net/weixin_42368982/article/details/108187284)。这里我们只需要知道,求解一个NP-hard问题是很复杂、也不可能找到解的,所以我们十分需要转化。
范数的数学定义同范数相似,令p=1,即。我们可以直观的从范数的原始定义公式(1)中找打范数的物理意义,范数等于向量中所有元素绝对值之和。从范数的优化公式中我们会发现,求解范数相比求解范数简单太多,我们可以借助现有凸优化算法(线性规划或是非线性规划),找到我们想要的可行解。
鉴于范数的实用性如此之大,现在我们来细细讨论范数。而我们的范数有两个很值得讨论的点:正则项与稀疏解。在正式进入讨论前,我们先看看什么是过拟合问题?
拟合问题是我们在机器学习过程中一定会面临的问题。那么什么样的问题是拟合问题呢?
机器学习利用模型对数据进行拟合,机器要对未曾在训练集合出现的样本进行正确预测,这是机器学习的真正目的。而拟合问题又包含欠拟合问题和过拟合问题。机器学习的数据集包含训练集和测试集。欠拟合和过拟合的性能的区别在于过拟合对于训练集的学习能力更强,而在测试集上的性能较差,而欠拟合在训练集和测试集上表现的性能都较差。
形象的说,若已知两类数据集分别为【请,清,静,婧】;【是,额,时,更】,现在机器来判断“菁”是属于那一类。在过拟合的情况下,机器会把“菁”判断为不是第一类,所以它是第二类。但实际上“菁”存在第一类中都有的“青”,所以实际上应该判断为第一类。过拟合就把这个训练集单个样本自身的特点都捕捉到,并分为一类。,这就是过拟合问题。这样范数的正则项的作用就体现出来了,往下看吧!
范数会让你的模型变傻一点,相比于记住事物本身,此时机器更倾向于从数据中找到一些简单的模式。例如上面距离的数据集:【请,清,静,婧】;【是,额,时,更】。
变傻前的机器:【请,清,静,婧】
变傻后的机器:【青,0,0,0】。相比于原来,它记住了简单的特征,这就是 范数正则项的作用。
为什么正则化可以防止过拟合问题?
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,即抗扰动能力强。
正则化会使模型偏好于更小的权值。更小的权值意味着更低的模型复杂度;添加 正则化相当于为模型添加了某种先验条件,这个先验条件限制了参数的分布,从而降低了模型的复杂度。
模型的复杂度降低,意味着模型对于噪声与异常点的抗干扰性的能力增强,从而提高模型的泛化能力。直观来说,就是对训练数据的拟合刚刚好,不会过分拟合训练数据(就向上面判断字符“菁”的问题一样)。
了解了范数的正则项的作用后,稀疏解的问题又出来了。这里解决两个问题:(1)为什么增加范数能够保证稀疏?(2)为什么范数找到一个稀疏解呢?
(1)为什么增加范数能够保证稀疏?
由范数的物理意义我们知道,范数表示向量(或矩阵)所有元素的绝对值之和。现在就随机选取两个向量和,其中向量和向量的范数分别如下,
,。明显向量不是稀疏向量,且仅仅是看范数的数值大小,我们可能很难比较向量的稀疏程度,因此实际需求中我们还需要结合损失函数。所以说增加范数能够更大几率的保证稀疏。
(2)为什么范数找到一个稀疏解呢?
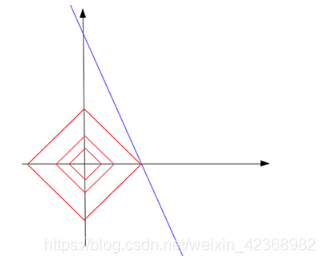
回到前面的问题,在平面直角坐标系上,假设一次函数经过(2,5)这一点。所以,参数的解有无数组 (在蓝线上的点都是解)。
这里先假设向量的范数是一个常数,将其图形化在xy坐标轴上为一个正方形 (红色线;范数表示元素的绝对值之和,若绝对值之和为常数,则相加之和为一常数),不过在这些边上只有很少的点是稀疏的,即与坐标轴相交的4个顶点。 这样这些同心正方形们可以和解相交,最终找到我们满足稀疏性要求的解,同时这个交点使得范数取得最小值。
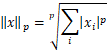 (1)
(1)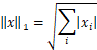 。我们可以直观的从范数的原始定义公式(1)中找打
。我们可以直观的从范数的原始定义公式(1)中找打