文章目录
- 一些被坑了的注意点
-
- C语言发展史
-
- C编译
-
- 条件语句
-
- 变量
-
- C关键字
- inline
- volatile
- attribute
-
- program pack
- 宏定义
- __DATE__
- __TIME__
- __FILE__
- __LINE__
- C字符
-
- C函数
- stdio.h
-
- string.h
- sizeof
- isspace
- strlen
- strcat
- strcmp
- strchr
- strcpy
- 字符串类型转换函数
- 共用体
- 枚举
- 结构体
- 结构体中的结构体
- 结构体的嵌套与初始化
- 结构体指针
- 函数指针
- 回调函数
- 指针
-
- 条件编译
- #ifdef的使用
- #ifndef的使用
-
- #if和#elif指令
- 位运算
-
- C运算
- 浮点运算
- 字符型
- 浮点型
- 整型定义
- 默认类型
-
- 初始化值
- 运算时类型转换
泉水
一些被坑了的注意点
(int16)
这是一个只有懂的才懂的痛点。
我们在FSMC传输时使用的都是Uint16,但是呢此时直接使用该值就会出问题。
尤其是转接的时候,当一个int16通过Uint16给到你,你又需要传递给别人的时候,你需要做的是Uin16 b =(int16)a
#define
- #define宏定义后面是不能有分号的,否则会被识别成语句。起不到作用。
结构体与共用体
union{
struct{
a:1;
}bit;
Uint16 all;
}state
- 结构体和共用体写完之后一定要有分号
- 结构体和共用体内用分号,最后一个量没有
枚举类型
enum{
a,
b,
c
}Type;
跟结构体和共用体一样,最后一定要有分号。内部用逗号。纠正一下,只有枚举内部用逗号,结构体和共用体内部一定要用分号!
指针
C语言发展史
C语言概述
C语言最初由 Dennis Ritchie 于 1969 年到 1973 年在 AT&T 贝尔实验室里开发出来,主要用于重新实现 Unix 操作系统。此时,C语言又被称为 K&R C。其中,K 表示 Kernighan 的首字母,而 R 则是 Ritchie 的首字母。
C90 标准
由于C语言被各大公司所使用(包括当时处于鼎盛时期的 IBM PC),因此到了 1989 年,C语言由美国国家标准协会(ANSI)进行了标准化,此时C语言又被称为 ANSI C。
而仅过一年,ANSI C 就被国际标准化组织 ISO 给采纳了。此时,C语言在 ISO 中有了一个官方名称——ISO/IEC 9899: 1990。其中:
• 9899 是C语言在 ISO 标准中的代号,像 C++ 在 ISO 标准中的代号是 14882;
• 而冒号后面的 1990 表示当前修订好的版本是在 1990 年发布的。
对 于ISO/IEC 9899: 1990 的俗称或简称,有些地方称为 C89,有些地方称为 C90,或者 C89/90。不管怎么称呼,它们都指代这个最初的C语言国际标准。
C99标准
在随后的几年里,C语言的标准化委员会又不断地对C语言进行改进,到了 1999 年,正式发布了 ISO/IEC 9899: 1999,简称为 C99 标准。
C99 标准引入了许多特性,包括内联函数(inline functions)、可变长度的数组、灵活的数组成员(用于结构体)、复合字面量、指定成员的初始化器、对IEEE754浮点数的改进、支持不定参数个数的宏定义,在数据类型上还增加了 long long int 以及复数类型。
毫不夸张地说,即便到目前为止,很少有C语言编译器是完整支持 C99 的。
C11标准
2007 年,C语言标准委员会又重新开始修订C语言,到了 2011 年正式发布了 ISO/IEC 9899: 2011,简称为 C11 标准。
C11标准新引入的特征尽管没 C99 相对 C90 引入的那么多,但是这些也都十分有用,比如:字节对齐说明符、泛型机制(generic selection)、对多线程的支持、静态断言、原子操作以及对 Unicode 的支持。
C编译
编译就是通过编译器将人写到代码翻译成机器语言。
编译器将.c翻译成.obj目标文件,.obj是二进制文件,但不是最终的.exe文件。
.obj文件通过链接器将目标文件与目标 文件与库文件合并成最终的.exe文件,也是二进制文件。
我们所讲的编译器是包含了链接器的。
o代替c
将生成的.o文件直接放到.c的位置,可以提高编译速度。
对CCS来说,.o文件在CCSProject ,Debug,同名目录下。
先将.o复制到本地工程.c目录下,然后将文件夹拖动到CCS工程中,接下来将.c文件exclude from project 然后编译,惊奇得发现.o代替.c了!!!
条件语句
else if
分支
1. else if
相当于 if… else
if… else
最少支持嵌套127层。
if(判断条件1){
语句块1
} else if(判断条件2){
语句块2
}else if(判断条件3){
语句块3
}else if(判断条件m){
语句块m
}else{
语句块n
}
do while
while中条件判断语句,看其结果是true还是false
如果是false,循环结束;如果是true,循环继续执行
变量
定义一个字符串
char str[25] = “Good morning”;
printf(“%#X, %#X\n”, &a, str);
定义一个数组u16 pBuffer[x].x=sizeof()。然后定义函数的时候就可以定义(u16* pbuffer),传递过去首地址也就是pBuffer数组名就可以了。长度该是多少传多少。
事实上也可以这样
DeBug(MAIN_DE,"主函数执行");
void DeBug(u16 IdNumber,char* message)
字符串结尾
- while(*string!=‘\0’)等同于while(*string)
因为每个字符串都以’\0’结尾,因此空字符值为0。当值为0时候结束。 - re=fgets(st,n,stdin);if(re);等同于re!=NULL
NULL一般被宏定义为文章结尾EOF或者’\0’. - 避免读到EOF
用入口条件循环进行文件输入
while((ch=getc(fp))!=EOF) - 检测空行。
input[ct][0]!=‘\0’.input[ct]是字符串数组 - 判断字符串是否为空字符串
title[0]!='\0’字符串首字符是否为空字符
定义一个字符串数组

以下是对二维字符数组元素的合法引用:
1.printf(“%c”,arr【1】【4】);//输出1行4列元素‘g’字符
2.scanf(“%c”,&arr【2】【3】);//输入字符到arr【2】行3列元素中
3.arr【2】【0】=‘B’,//把字符赋值给第二行0列的元素
4.printf(“%s”,arr【1】);//arr【1】为第二行的数组名(首元素地址),输出orange
5.scanf(“%s”,arr【2】);//输入字符串到arr【2】行,从arr【2】行的首地址开始存放
static
static 一般用于修饰局部变量,全局变量,函数。
修饰局部变量
void test()
{
int a = 1;
a++;
printf("%d ", a);
}
int main(void)
{
int i = 0;
while (i <= 10)
{
test();
i++;
}
return 0;
结果为2 2 2 2 2 2 2 2 2 2 。将test中int a=1;改为static int a=1; 后: 结果为2 3 4 5 6 7 8 9 10。Static可以讲一个局部变量变为全局变量,作用等同。
- 本质上,static修饰局部变量时,会影响局部变量的生命周期,改变了局部变量的存储位置。
修饰全局变量
全局变量具有外部链接属性。而static修饰全局变量时,这个全局变量的外部链接属性变为内部链接属性。
- 作用域变小。
- 在A.c中定义int a=10,在B.c中 extern int a; 则可调用,a=10。
- 在A.c中定义static int a=10,在B.c中 extern int a; 不可调用,会报错。
修饰函数
类似于static修饰全局变量。函数同样具有外部属性。而static修饰函数时,这个函数的外部链接属性变为内部链接属性。
- 作用域变小。
- 在A.c中定义int add(int x,int y),在B.c中 extern int add(int x,int y); 则可调用。
- 在A.c中定义static int add(int x,int y),在B.c中 extern int add(int x,int y); 则可调用。不可调用,会报错。
C关键字
inline
用于定义内联函数,像普通函数一样被调用,但是在调用时并不通过函数的调用机制,而是直接在调用点展开,这项可以大大减少由函数调用带来的开销,从而提高程序的运行效率
使用注意
- 一般不内联包括循环,递归,switch等复杂操作的内联函数
volatile
告知编译器编译方法的关键字。不优化编译。这个变量有可能被其他子程序改变,所以不能从寄存器里读取变量的值,要从内存里读取。
编译器优化的时候可能会跳过某一段变量的外部赋值(外部用户按键)过程。
attribute
attribute_(at(绝对地址))的作用就是绝对定位。
绝对定位不能在函数中定义,函数中定义的普通变量是局部变量,局部变量是定义在栈区的,栈区由MDK自动分配、释放,不能定义为绝对地址。
一般我们的变量都存在于内部SRAM中,在使用该语句能够将变量定义到对应地址的flash或者ram中。
但是定义的长度不能超过栈或Flash的大小,否则就会造成栈、Flash溢出。
定位到 FLASH
定位到 flash 中,常用于固化信息,例如:设备的出厂信息,FLASH 标记等
const uint8_t usF[] __attribute__((at(0x00030000))) = {0x11,0x22,0x33,0x44,0x55,0x66};
在 0x08010000 的 flash 地址上固定写入数据:
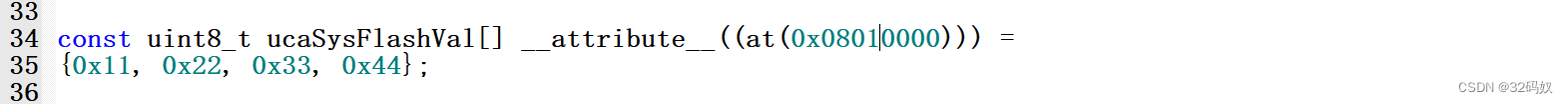
编译后:
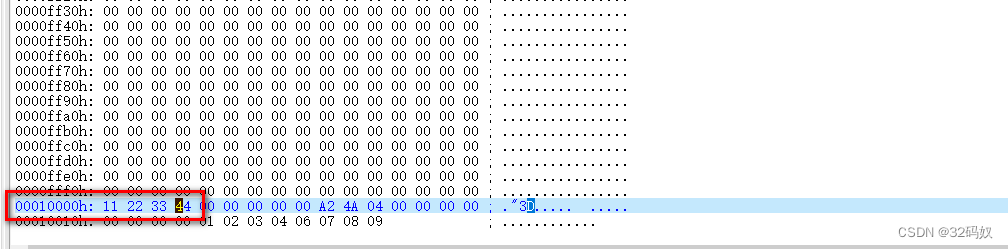 我们在烧录数据的时候,一般是从0x08000000开始按照顺序烧录到flash里面的,要让数据能够定义到绝对地址如0800F000,就必须保证文件内数据也是存储在该地址,所以,MDK在生成文件时会填充0x00字段。
我们在烧录数据的时候,一般是从0x08000000开始按照顺序烧录到flash里面的,要让数据能够定义到绝对地址如0800F000,就必须保证文件内数据也是存储在该地址,所以,MDK在生成文件时会填充0x00字段。
定位到 RAM
常用于数据量较大的缓存,如:串口接收数据。也用于某个位置的特定变量。
uint8_t ucU[USART_RECV_LEN] __attribute__ ((at(0x00025000)));
区别
如果不加 const 修饰,则定位到了 RAM 。
program pack
#program pack 禁止对齐
#pragma pack(4)
typedef struct
{
char buf[3];
word a;
}kk;
#pragma pack()
对齐的原则是min(sizeof(word ),4)=2,因此是2字节对齐,而不是我们认为的4字节对齐。word为结构体中单个成员的最大占用字节数。
- 1.每个成员分别按自己的方式对齐,并能最小化长度
- 2.结构的默认对齐方式是它最长的成员的对齐方式,可以最小化长度
- 3.对齐后的结构体整体长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐。
1个字节a 1个字节b
1个字节c 1个空字节
2个字节D
1个字节...
宏定义
ANSI C 定义了许多宏。在编程中您可以使用这些宏,但是不能直接修改这些预定义的宏。
DATE
当前日期,一个以 “MMM DD YYYY” 格式表示的字符串常量。
TIME
当前时间,一个以 “HH:MM:SS” 格式表示的字符串常量。
FILE
这会包含当前文件名,一个字符串常量。
LINE
这会包含当前行号,一个十进制常量。
STDC 当编译器以 ANSI 标准编译时,则定义为 1;判断该文件是不是标准 C 程序。
printf("%d\n",__LINE__);
printf("%s\n",__FILE__);
C字符
优先级
优先级
a. 圆括号,[ ]
b. ! ++ ,从右向左a++
c. ×
d. > < !=
e. && &(位)
f. ||
g. =
转义字符
\n 换行
" 打印双引号。
\0 的编码值为0
打印字符
%s 字符串
%10s 10位的字符串
%m.nf 总共m位,n位小数点以后的。
C函数
stdio.h
FILE
定义在stdio.h中的派生类型,定义文件指针。FILE *p;
printf
字符串输出函数
sprintf
sprintf(A,B,C,D)把多个元素组合成一个字符串,但不显示在屏幕上。A是目标字符串地址。其余参数与printf相同。
如spintf(des,“%s,%-19s:\n”,last,first);
数字前后缀
- U表示该常数用无符号整型方式存储,相当于 unsigned int
- UL 无符号长整形
- 123一般隐式定义为int型,这样两个int型的数据进行操作后有可能所得的结果超出int型,为了解决这个问题,我们可以用UL强制把int型的数据转换为unsigned long,一旦有一个数据强制转换后,就执行“整型提升”,这样就可以解决溢出的问题了。
- L表示该常数用长整型方式存储,相当于 long
- F表示该常数用浮点型方式存储,相当于 float
- 数值后面加“H“、“h”的意义是该数值是用16进制表示的。
- 数值后面加“B“、“b”的意义是该数值是用2进制表示的。
- 后面什么也不加,代表10进制。
- 数值前面加“0”的意义是该数值是八进制。
- 数值前面加“0x”的意义是该数值是十六进制。
输出格式
%d整型输出,%ld长整型输出,
%o以八进制数形式输出整数,
%x以十六进制数形式输出整数,
%#x表示以0x开头的整数输出
%u以十进制数输出unsigned型数据(无符号数)。
%c用来输出一个字符,
%s用来输出一个字符串,
%f用来输出实数,以小数形式输出,
%e以指数形式输出实数,
%g根据大小自动选f格式或e格式,且不输出无意义的零。
scanf(控制字符,地址列表)
格式字符的含义同printf函数,地址列表是由若干个地址组成的表列,可以是变量的地址,或字符串的首地址。如scanf(“%d%c%s”,&a,&b,str);
string.h
toupper():处理字符串中的每个字符转成大写。
tolower():大写转小写字母。
isalpha(ch):收到字母,返回非零值,非字母,0.
ispunct():收到标点符号,返回非零值,非标点符号,0.
sizeof
size_t :sizeof 的返回的类型。因为C规定sizeof返回整数类型,但没说什么整数,因此用size_t可以自动调取整数类型。
头文件在string.h中。
isspace
isspace():若是空白字符返回1,否则返回0。
strlen
字符串长度函数
strlen(A):统计字符串长度。
strlen(string); string是指针变量。
strcat
字符串拼接函数
a. strcat(A,B):将第二个字符串的备份附加在第一个字符串的末尾作为第一个字符串。拼接函数。第一个字符串的结尾空字符被覆盖。第二个字符串不变。
b. strncat:无法检查第一个数组能否容纳第二个字符串。如果多出来的字符溢出到相邻的存储单元会出问题。
strncat(A,B,C),第三个参数规定了最大添加字符数。也就是添加到第C个字符或者遇到空字符时停止。
strcmp
字符串比较函数
- . while(strcmp(A,B));,strcmp(A,B):比较函数。比较字符串,若两个字符串参数相同,返回0,否则返回非零值。只比较第一个空字符’\0’前面的部分。
- 两字符串皆为字母时,第一个ASCII值-第二个ASCII值。≠情况。
- strcmp会依次比较每个字符,直到发现第一对不同的字符为止。
- strncmp(A,B,C):只比较前C-1个字符。
strchr
字符串查找函数
strchr(A,'\ '):字符查找函数。没有找到返回空指针NULL.
strcpy
把 src 所指向的字符串复制到 dest
char *strcpy(char *dest, const char *src)
如果目标数组 dest 不够大,而源字符串的长度又太长,可能会造成缓冲溢出的情况。
字符串复制函数概述
a. strcpy():拷贝字符串。
- 返回值是一个char*,第一个字符的地址。
- 第一个参数可以不指向数组的开始。如strcpy(copy+7,orig);
- strncpy(A,B,C):最大拷贝字符数C。
如果拷贝字符数小于n,z则拷贝整个字符串包括空字符。如果拷第n还未拷完则不会拷空字符。因此若要确保拷贝的是一个字符串,则把C设为n-1,然后令A[n-1]=‘\0’.
字符串类型转换函数
. atoi():函数,把字母数字转换为整数。返回值为整数。
如果输入字符串atoi(“42stjijso”)将会返回42.
如果输入字符串atoi(“sjji”)将会返回0.
头文件:stdlib.h
. atof():把字符串数字转换成double类型数值。
. atol():把字符串转换成long类型数值。
. strtol()有错误检测功能的atoi函数。把字符串转换成long类型的值。
. strtoul():把字符串转换成unsigned long类型值。
. strtod():把字符串形式的数字转换为double类型的数字。
strtol与strtoul更智能,可以检测首字符是否是数字。
共用体
union hold{
int digit;
double bigf1;
char letter;};
变量:
union hold fit;
union hold save[10];
union hold *pu;
枚举
- 枚举声明符号名称来表示整型常量。提高程序的可读性
enum:创建一个新的类型并制定它可具有的值。语法与结构的语法相同。 - 程序:
enum spetrum{red ,orang,yellow, green, blue, violet}; - enum spetrum作为一个类型名使用,color作为类型变量。
- blue从技术层面看是int类型的常量。
printf(“red=%d”,red);
red代表整数0,其他标识符,分别代表1-5. - 赋值
enum level{cat,lynx=10,puma,tig};
cat是0,接下来是10,11,12
结构体
结构体中的结构体
struct student{
int id;
struct teacher{
int age;
}th;
};
int main(){
struct strudent stu;
stu.th.age=18;就可以访问结构体的结构体。
return 0;
}
结构体的嵌套与初始化
结构体嵌套
在一个结构中包含另一个结构.
struct names{
char first[LEN];
char last[LEN];
};
struct guy{
struct names handle;
char favfood[LEN];
char job[LEN];
float income;
};
int main(void)
struct guy fellow={
{ "ewen","villard"},
"griid al",
"coach",
68112.00
}; 初始化
fellow.handle.first
结构体指针
结构体指针成员变量引用方法是通过“->”符号实现
struct U_TYPE *usart3;
比如要访问 usart3 结构体指针指向的结构体的成员变量 BaudRate,方法是:
Usart3->BaudRate;
结构体指针的输出
struct Animal {
char *name;
int age;
char info[200];
struct Animal *nextAnimal;
};
Animal *nextAnimal 在没有初始化的情况下输出程序编译没有问题,运行报错
animal.nextAnimal = (struct Animal *)malloc(sizeof(struct Animal));
printf("animal.nextAnimal->name: %s, age: %i, info: %s\n", animal.nextAnimal->name, animal.nextAnimal->age, animal.nextAnimal->info);
再次编译重新运行,还是报错。还需要初始化 animal.nextAnimal->name 这个变量
animal.nextAnimal->name = "cat";
也就是说结构体指针变量有些会给默认值,有些又不会给,所以都要初始化指针变量。
#define usart1 (USART_TypeDef *) UART1_BASE 本身后面是个地址,相当于定义了一个指针变量,指向串口的结构体地址。
#define代表的是等价替换,放过去就好了!所以usart1的类型就是USART_TypeDef *。
函数指针
函数指针是指向函数的指针变量。
函数指针可以像一般函数一样,用于调用函数、传递参数。
typedef int (*fun_ptr)(int,int);
调用实例
#include <stdio.h>
int max(int x, int y)
{
return x > y ? x : y;
}
int main(void)
{
int (* p)(int, int) = & max;
int a, b, c, d;
printf("请输入三个数字:");
scanf("%d %d %d", & a, & b, & c);
d = p(p(a, b), c);
printf("最大的数字是: %d\n", d);
return 0;
}
回调函数
函数指针变量可以作为某个函数的参数来使用的,回调函数就是一个通过函数指针调用的函数。
调用过程:
populate_array() 函数定义了三个参数,其中第三个参数是函数的指针,通过该函数来设置数组的值。
我们定义了回调函数 getNextRandomValue(),它返回一个随机值,它作为一个函数指针传递给 populate_array() 函数。
#include <stdlib.h>
#include <stdio.h>
void populate_array(int *array, size_t arraySize, int (*getNextValue)(void))
{
for (size_t i=0; i<arraySize; i++)
array[i] = getNextValue();
}
int getNextRandomValue(void)
{
return rand();
}
int main(void)
{
int myarray[10];
populate_array(myarray, 10, getNextRandomValue);
for(int i = 0; i < 10; i++) {
printf("%d ", myarray[i]);
}
printf("\n");
return 0;
}
指针
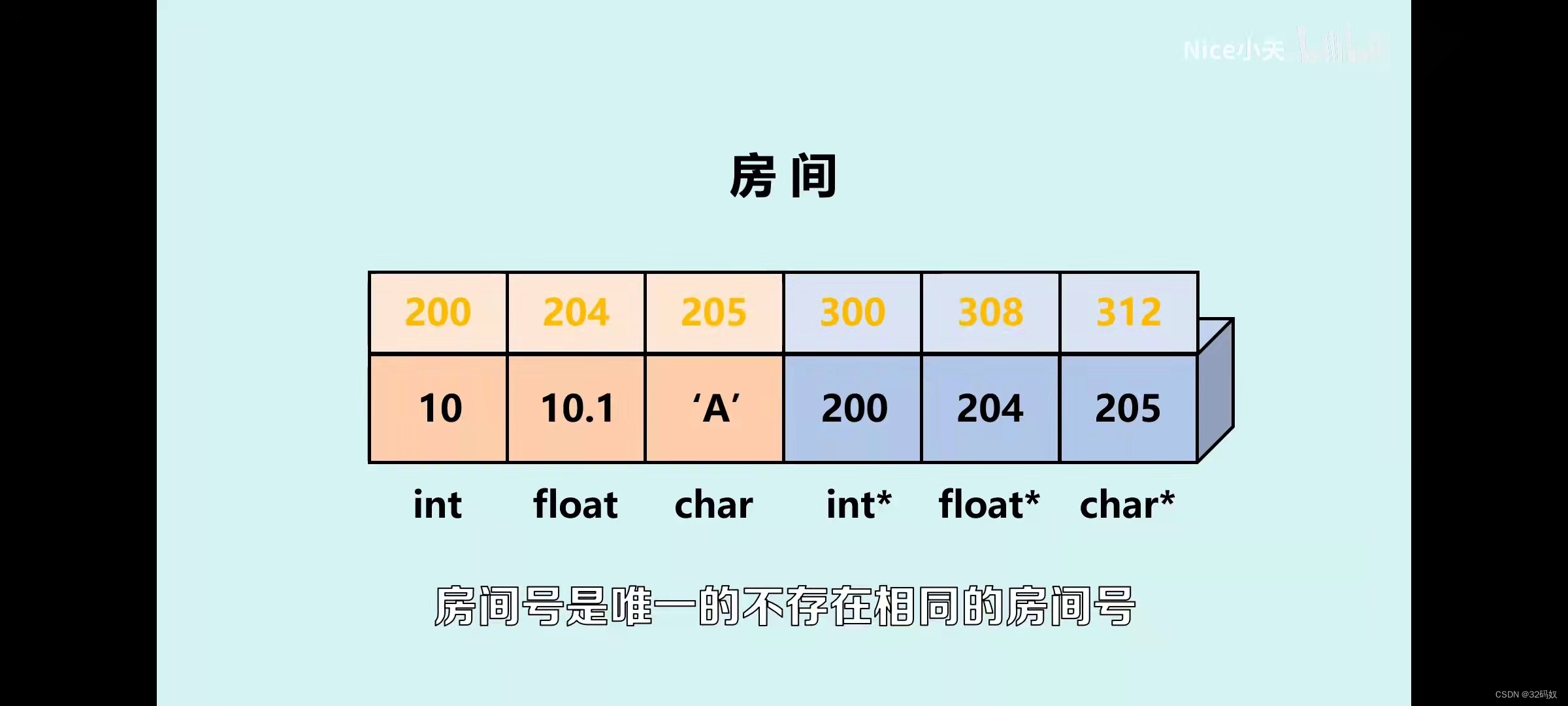
指针的理解
指针的究极理解
int *p=a;
指针放的就是地址,p即为’那儿’,*p则是那儿的值。
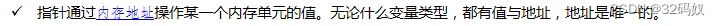
指针的标准理解
指针一定存储的是变量的小端的首地址。
C语言编译器对指针这个特殊的盒子
- 盒子要多大
- 在32位系统中,指针变量就4个字节,因为一个地址最大值就是32个盒子。
- 盒子里存放的地址内存的读取方法是什么
- char * p,C编译器认为char是修饰* 的,以下是编译器读的过程。
- 先看到p,p是核心节点
- 看到* ,是个指针,分配个大小
- 这个* 怎么读内存?找类型,这个*是char类型的。一次读一个字节。
- 这个时候你要是赋值是int的0x12345678,那么char *p存放的只有一个字节也就是78的地址。如果是int *p,则取出来的地址就是四个字节,就是12345678所有四个盒子的地址。
*p++=*a++;
先将a那儿的值*a给了p那儿,然后a那儿地址加1,p那儿地址加1。
指针的修饰符
const
常量的定义
const int a=100;a就不能变了
编译器翻译成了只读的变量。但是它还是通过地址可以变的
内存中还是一个变量,在可读可写的区域,所以还是可以变的。
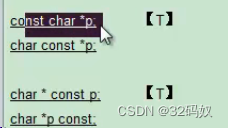

标T的是推荐的写法,
第一种char和const都是修饰指针*的,所以不分前后。p地址可以变,p里面的内容就不能操作了
第二种const是修饰p的,不分前后。地址不可变了,内容可以变。相对硬件资源就很合适这种状况。
第三种,啥都不能变,如ROM
volatile
防止优化
typedef
别名
条件编译

编译器根据条件执行或忽略块。
#ifdef的使用
#ifdef MAVIS
#include ”horse.h"
#indlude STABLES 5
#else
#include "cow.h"
#define STABLES 15
#endif
如果定义了MAVIS,则执行下列指令,否则
是否定义,#define MAVIS
与普通选择语句主要区别为预处理器不识别{},这种指令结构可以用于嵌套。
在程序中使用上述结构
int main(void)
{
for (i=1; i<LIMIT;i++)
{
#ifdef JUST %是否定义了JUST
printf("i=%d,running total=%d\n",I,total);
#endif
}
}
定义JUST并合理使用#ifdef,编译器会执行用于调试程序的代码,打印中间值。调试结束后,可移除JUST定义再重新编辑。
#ifndef的使用
#ifndef指令
与上述逻辑相反,判断后面的标识符是否是未定义的,可以防止相同的宏被重复定义
#ifndef SIZE
#define SIZE 100
#endif
如果没有定义SIZE,则
C编_cpluslpus
#ifdef __cplusplus
extern “C” {
#endif
#ifdef __cplusplus
}
#endif
在C++编译器中,已经内置了__cplusplus这个宏定义,所以在使用C++编译器编译其它语言(比如C语言)时,用这样的方式,可以让编译器把extern “C” 代码块中的内容按照C语言的方式进行编译。
#if和#elif指令
#if SYS==1
#include "ibmpc.h"
#elif SYS==2
#include "vax.h"
#elif SYS==3
#include "mac,h"
#endif
泛型选择(C11)
泛型编程指那些没有特定类型,但是一旦指定一种类型,就可以转换成指定类型的代码。
位运算
-
左移:从二进制的角度看现象,就是左移几位就在右边添几个0。
从逻辑上来讲左移n位就是乘以2的n次方了。
-
右移:从二进制角度看,则是在左边填0,右边去除移动的位数的位 。
(如遇到时1>>1, 便是0.);
(注意:如果操作数是一个正数,那么左边的空缺位使用0补,如果操作数是一个负数,那么左边的空缺位使用1补)
从逻辑上来讲右移就是除以2的n次方;
-
按位逻辑运算符有四个,皆用于整型数据,包括char。
a. ~按位取反
b. &按位与 与:乘
c. |按位或 或:加
d. ^按位异或 异或:加-除
磁极,相同为零,不用为1.
快速乘除
乘2的n次幂
number<<n
若number为非负,则用number除以2的n次幂
number>>n
u8 u16 u32 互相转换
#include <stdio.h>
#define u8 short int
#define u16 long int
#define u32 long long
int main()
{
u8 a[2] = { 0xcd, 0xe2 };
u16 b;
b=a[0];
b=b<<8;
b=b|a[1];
u8 a[2] = { 0 };
u16 b = 0xc32d;
a[1] = b >> 8;
a[0] = b & 0xff;
u8 a[2] = { 0xab, 0xcd };
u16 b;
b= a[0] | a[1] << 8;
int i = 4;
u32 a=0x1234abcd;
u8 b[4];
b[0] = a >> 24;
b[1] = (a >> 16)&0xff;
b[2] =( a >> 8)&0xff;
b[3] = a &0xff ;
while (i--)
{
printf("0x%02x\n", b[i]);
}
int i = 4;
u32 a;
u8 b[4] = {0xcf,0xb3,0x43,0xbb};
a = (long long)b[3] << 32;
a = b[0] << 24|b[3];
a =a|(( b[1]&0x00ff)<<16);
a = a | ((b[2] & 0x0000ff) <<8);
printf("0x%02x\n", a);
int i = 2;
u32 a = 0x1234abcd;
u16 b[2];
b[0] =( a >>16);
b[1] = a &0xffff;
while (i--)
{
printf("0x%02x\n", b[i]);
}
int i = 2;
u32 a ;
u16 b[2] = {0xa1cb,0x2bea};
a=b[0]<<16;
a = b[1] |( b[0]<<16);
printf("0x%02x\n", a);
getchar();
}
int int2_bit(int a)
{
int i,bit,size=sizeof(a)*8;
for(i=0;i<size;i++)
{
bit=a&(1<<(size-i-1));
if(bit==1)
pirntf("1");
else
printf("0");
if(i%4==3)
printf(" ");
}
}
int power(int x)
{
int i=1,t=2;
if(x ==0)
t=1;
for(;i<x;i++)
{
t=2*t;
}
return t;
}
int bit_int(char *x)
{ int i=0,n=7,tmp,sum;
for(;i<8;i++,n--)
{
tmp=x[i]*pwer(n);
sum+=tmp;
}
return sum;
}
int ch_sum(int x)
{
int tmp,is=0;
for(int i=0;i<sizeof(x)*8;i++)
{
tmp=1<<i;
if(x&tmp)
{
is++;
}
}
return is;
}
int8_t otcp( uint8_t a)
{
uint8_t b=~a,t=1<<7;
if(a<0)
{
b|=t;
}
return b;
}
u8 a[2] = { 0x6, 0xc };
u16 b;
b=a[0];
b=b<<8;
b=b|(a[1]<<4);
b=b>>4;
printf("0x%0x ",b);
u8 d_k(u8 *databuf)
{ int of=0;
for(int i=0;i<sizeof(datebuf);i++)
{
char c=databuf[i];
if(c==' ')
{
++of;
}
else
{
rxbuf[i-of]=c;
}
}
return rxbuf;
}
char c_buf='a';
int b='a'-'0' ;
printf("0x%0x",b);
printf("\n%d",b);
printf("\n%d",c_buf);
位带操作
位带操作,指的就是单独对一个bit位进行读和写。
STM32 中,有两个地方实现了位带,一个是SRAM区的最低 1MB 空间,令一个是外设区最低 1MB 空间。这两个 1MB 的空间除了可以像正常的 RAM 一样操作外,他们还有自己的位带别名区,位带别名区把这 1MB 的空间的每一个位膨胀成一个 32 位的字,当访问位带别名区的这些字时,就可以达到访问位带区某个比特位的目的。
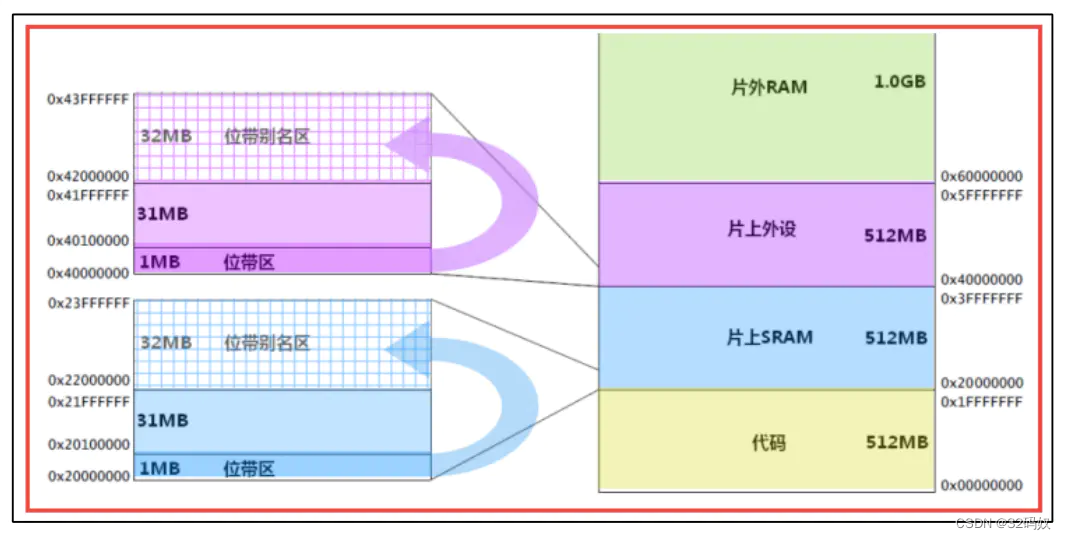
外设外带区的地址为:0X40000000~0X40100000,大小为 1MB,这 1MB 的大小在 103系列大/中/小容量型号的单片机中包含了片上外设的全部寄存器,这些寄存器的地址为:0X40000000~0X40029FFF 。 外 设 位 带 区 经 过 膨 胀 后 的 位 带 别 名 区 地 址 为 :0X42000000~0X43FFFFFF,这个地址仍然在 CM3 片上外设的地址空间中。在 103 系列大/中小容量型号的单片机里面,0X40030000~0X4FFFFFFF 属于保留地址,膨胀后的 32MB位带别名区刚好就落到这个地址范围内,不会跟片上外设的其他寄存器地址重合。
STM32 的全部寄存器都可以通过访问位带别名区的方式来达到访问原始寄存器比特位的效果
对于片上外设位带区的某个比特,记它所在字节的地址为 A,位序号为 n(0<=n<=7),则该比特在别名区的地址为:
AliasAddr= =0x42000000+ (A-0x40000000)84 +n*4;
0X42000000 是外设位带别名区的起始地址,0x40000000 是外设位带区的起始地址,(A-0x40000000)表示该比特前面有多少个字节,一个字节有 8 位,所以8,一个位膨胀后是 4 个字节,所以4,n 表示该比特在 A 地址的序号,因为一个位经过膨胀后是四个字节,所以也*4。
SRAM 的位带区的地址为:0X2000 0000~X2010 0000,大小为 1MB,经过膨胀后的位带别名区地址为:0X2200 0000~0X23FF FFFF,大小为 32MB。操作 SRAM 的比特位这个用得很少。
SRAM位带别名区地址:
对于 SRAM 位带区的某个比特,记它所在字节的地址为 A,位序号为 n(0<=n<=7),则该比特在别名区的地址为:
AliasAddr= =0x22000000+ (A-0x20000000)84 +n*4;
公式分析同上。
C运算
浮点运算
以下运算需要1584字节的代码量
t
e
m
p
=
1.43
−
t
e
m
p
0.0043
+
25
temp = \frac{1.43-temp}{0.0043}+25
temp=0.00431.43−temp+25
以下运算需要40个字节的代码量
t
e
m
p
=
1.43
f
−
t
e
m
p
0.0043
f
+
25
temp = \frac{1.43f-temp}{0.0043f}+25
temp=0.0043f1.43f−temp+25
加f代表指定单精度,不加f会按照双精度处理。
字符型
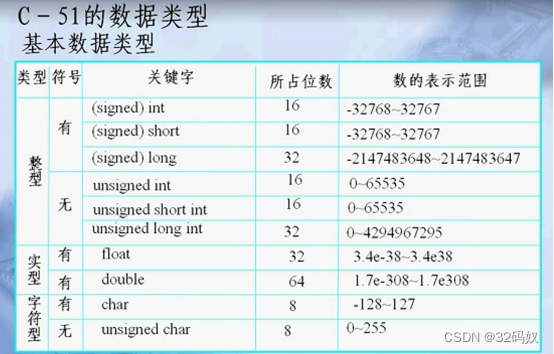
字符型的范围是0-65535,没有负的char
char16位,可以存储一个中文。Java采用Unicode编码。
定义一个字符串
const char add[] = “你好”。
浮点型
浮点数后面加f或F是float型
浮点数赋值 float a=(float)1.1
浮点数后面加d或D是double型。
œ Double 是分数,或实数。
科学记数法5.3E12也是double型。
整型定义
- 默认整数是int。其他类型使用就要加字母。
- 低精度赋值给高精度是可以自动进行类型转换的,高精度到低精度则需要强制。
- int的字节数一般跟随系统的位数,跟随地址的位数。32位系统的int是4个字节,地址是32位。
- 浮点中默认类型是double,若要用float,加F.
- 整数中默认类型int,若要用long,加L。
默认类型
自动类型转换
默认整数是int,可以赋值给float,自动进行类型转换。
- 数据范围从小到大,与字节数不一定相关
- double>float;
- long>int
- float>long
- long num1=100;
当数据类型不一样,发生数据转换
默认小数点的类型是double型。
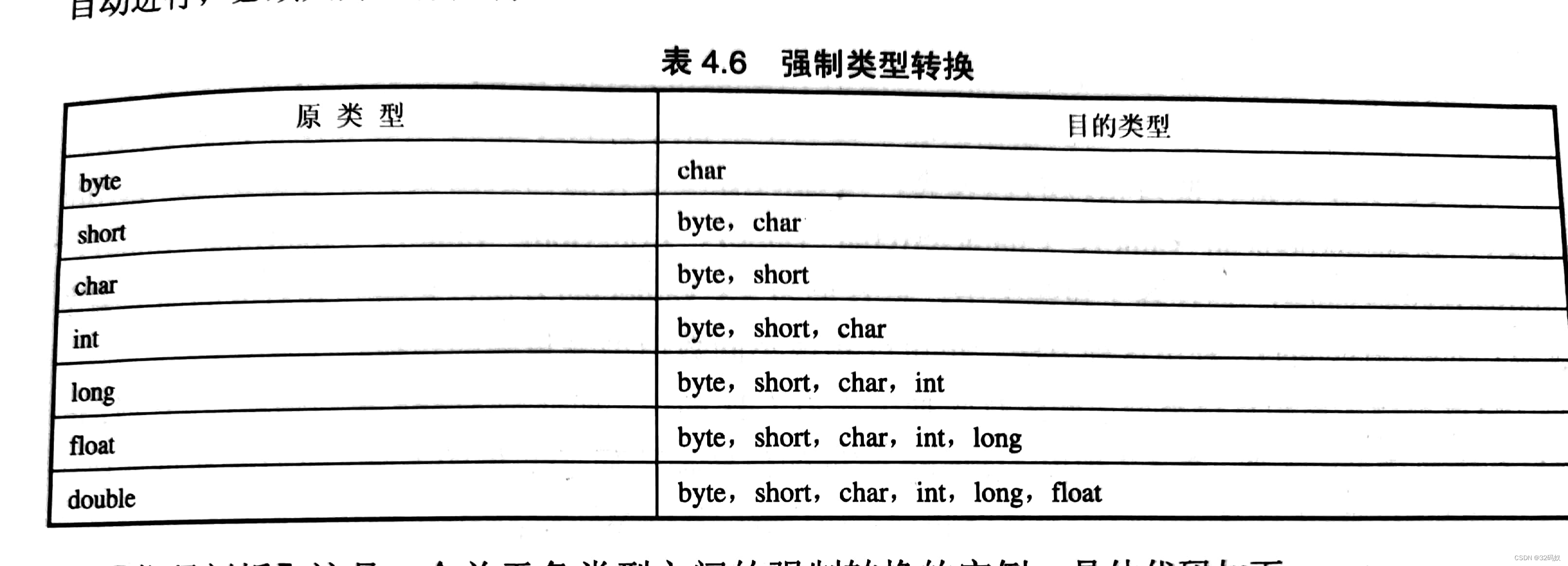
强制类型转换
数据类型转换
○ 布尔类型不能进行数据转换
○ ()
○ 防止数据溢出
○ 并不是四舍五入,所有的小数位都会舍弃
初始化值
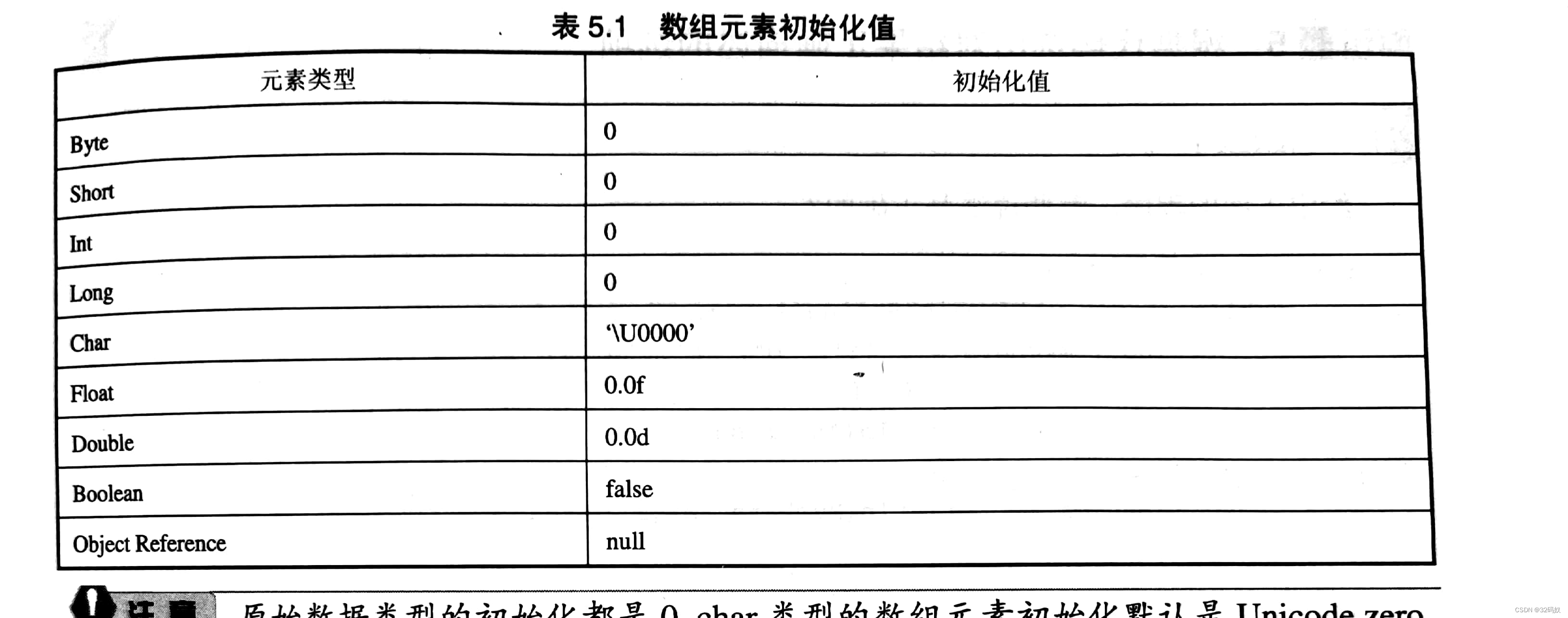
运算时类型转换
运算中会自动转换为数据范围大的那种
- int+double =double+double
byte、char、short都可以进行加减乘除的数学运算
○ 运算时首先翻译为int类型,再进行计算
○ int ()=byte+byte;右边变int+int,因此左边要用int接收
○ 对于byte、char、char,如果右侧没超过左侧范围,编译器自动补上强制,超过范围报错。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)