您是否一直在代码中处理包含大量数据的数据集,并且一旦执行代码,您就会发现代码需要很长时间才能产生最终输出?
嗯,这可能会令人沮丧!您可能使用了正确的语法,并且逻辑也是正确的。然而,该代码会消耗大量 RAM,并且执行时间过长。
这时您应该考虑优化代码以更好地利用 CPU 资源。查找原因并定位其发生位置对于确定最佳解决方案极为重要。
在这种情况下,你会采取什么方法?您是否会使用点击和试用方法来试验您的代码,以找到代码中消耗最大资源的位置?
这是一种方法,但肯定不是最好的方法。 Python 为我们提供了令人惊奇的工具,称为分析器,它通过检测代码中导致整体代码性能不佳的确切区域,使我们的生活变得轻松。
简而言之,分析是指详细统计代码使用的不同资源以及代码如何使用这些资源。
在本教程中,我们将深入研究众多分析器,并学习如何可视化代码中的瓶颈,这将使我们能够识别问题以优化和增强代码的性能。
什么是剖析? 如果程序消耗过多 RAM 或执行时间过长,则有必要找出代码整体性能障碍背后的原因。
这意味着您需要确定代码的哪一部分阻碍了性能。
您可以通过优化您认为是造成瓶颈的主要原因的代码部分来解决问题。但通常情况下,您可能最终会修复代码中的错误部分,以试图疯狂猜测问题的位置。
您不应简单地寻找问题的中心,而应选择确定性方法,以帮助您找到导致性能障碍的确切资源。
这就是分析的用武之地。
分析使您能够以最小的努力找到代码中的瓶颈,并允许您优化代码以获得最大的性能增益。
分析的最佳部分是可以分析任何可测量的资源(不仅仅是 CPU 时间和内存)。
例如,您还可以测量网络带宽和磁盘 I/O。在本教程中,我们将重点在 Python 分析器的帮助下优化 CPU 时间和内存使用。
因此,事不宜迟,让我们深入研究 Python 提供的众多方法来对 Python 程序执行确定性分析。
使用时间模块 Python 提供了大量的选项来测量代码的 CPU 时间。其中最简单的是时间模块 。让我们考虑一下我们的代码需要花费大量的时间来执行。
您可以在此处使用计时器来计算代码的执行时间并不断对其进行动态优化。定时器非常容易实现,并且几乎可以在代码中的任何地方使用。
例子: 在下面的代码片段中,我们将查看一段非常简单的代码,它测量代码执行一个简单函数所花费的时间。
import time
def linear_search(a, x):
for i in range(len(a)):
if a[i] == x:
return i
return -1
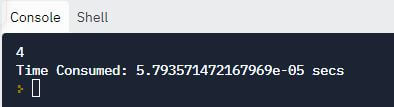
start = time.time()
print(linear_search([10, 20, 30, 40, 50, 60, 70, 80, 90, 100], 50))
stop = time.time()
print("Time Consumed: {} secs".format(stop - start))
Output:
解释: 在上面的代码中,我们对给定列表实现了线性搜索,并使用函数搜索该列表中的特定数字。
time 模块的 time() 方法允许我们通过跟踪执行整个 Linear_search() 函数所花费的时间来跟踪执行这段代码所需的时间。
在这种情况下,开始时间和停止时间之间的差异是函数计算输出的实际时间。
因此,它让我们清楚地了解使用 Linear_search 函数搜索列表中的元素所需的时间。
讨论: 考虑到列表的长度,这是一种超快速的搜索机制;因此这不是一个大问题。然而,想象一个由数千个数字组成的巨大列表。
那么,在这种情况下,就代码消耗的时间而言,这种搜索技术可能不是最好的算法。
因此,这是另一种方法,可以帮助搜索相同的元素,但需要更少的时间,从而允许我们优化代码。
我们将再次借助 time.time() 函数检查经过的时间,以比较两个代码所花费的时间。
import time
def binary_search(a, x):
low = 0
high = len(a) - 1
mid = 0
while low <= high:
mid = (high + low) // 2
if a[mid] < x:
low = mid + 1
elif a[mid] > x:
high = mid - 1
else:
return mid
return -1
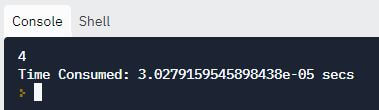
start = time.time()
print(binary_search([10, 20, 30, 40, 50, 60, 70, 80, 90, 100], 50))
stop = time.time()
print("Time Consumed: {} secs".format(stop - start))
Output:
当我们比较两个输出时,很明显二分搜索比线性搜索方法消耗的时间更少。
因此,time.time() 函数使我们能够跟踪代码从列表中搜索特定元素所花费的时间,这使我们能够在最佳搜索算法的帮助下提高代码的性能。
使用cProfile 虽然 time 模块帮助我们跟踪代码达到最终输出所需的时间,但它并没有为我们提供太多信息。
我们必须通过手动分析代码来比较每种算法所花费的时间,从而确定最佳解决方案。
但是,在您的代码中有时会需要某些其他参数的帮助来确定代码的哪一部分导致了最大延迟。
这时您可以使用 cProfile 模块。 cProfile 是 Python 中的内置模块,通常用于执行分析。
它不仅提供代码执行所花费的总时间,而且还显示每个步骤所花费的时间。
反过来,这使我们能够比较和定位实际需要优化的代码部分。
使用cProfile的另一个好处是,如果代码中有大量函数调用,它会显示每个函数被调用的次数。
事实证明,这有助于优化代码的不同部分。
Note: cProfile 通过 cProfile.run(statement, filename=None, sort=-1) 函数帮助我们对代码执行分析。
在语句参数中,您可以传递要分析的代码或函数名称。如果您希望将输出保存到某个文件,则可以将该文件的名称传递给 filename 参数。
sort 参数用于指定输出的打印顺序。让我们看一个利用 cProfile 模块显示 CPU 使用统计信息的示例。
import cProfile
def build():
arr = []
for a in range(0, 1000000):
arr.append(a)
def deploy():
print('Array deployed!')
def main():
build()
deploy()
if __name__ == '__main__':
cProfile.run('main()')
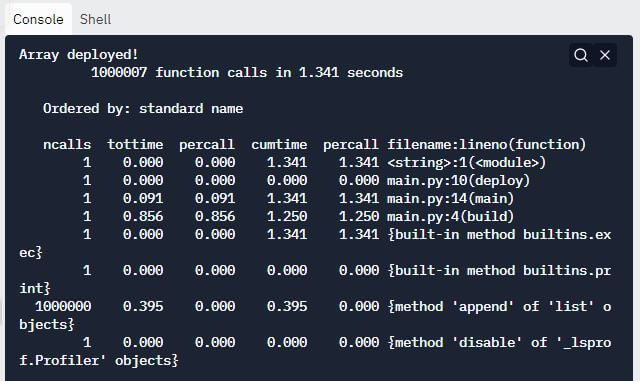
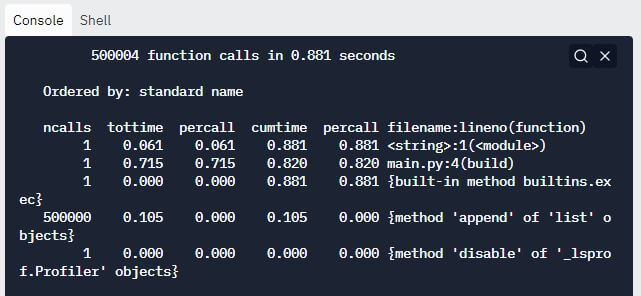
Output:
解释:
显示输出后,cProfile 显示的下一个信息是代码中发生的函数调用次数以及执行这些函数调用所需的总时间。
下一条信息是“Ordered by: standard name”,它表示最右列中的字符串用于对输出进行排序。
表的列标题包含以下信息:
ncalls:代表呼叫次数。
tottime:表示函数所花费的总时间。它不包括调用子函数所花费的时间。
每次调用:(tottime)/(ncalls)
cumtime:表示函数所花费的总时间以及父函数调用子函数所花费的时间。
percall: (cumtime)/(原始调用)
filename:lineno(function):给出每个函数各自的数据。
可以通过在 build() 方法本身中打印输出来对此代码进行轻微改进。这将减少单个函数调用,并帮助我们稍微提高代码的执行时间。
借助嵌套函数可以更好地可视化这一点。因此,让我们可视化分析对于嵌套函数的重要性。
分析嵌套函数 让我们对嵌套函数实现分析,即一个函数调用另一个函数来可视化 cProfile 如何帮助我们优化代码。
import cProfile
def build():
arr = []
for a in range(0, 1000000):
if check_even(a):
arr.append(a)
def check_even(x):
if x % 2 == 0:
return x
else:
return None
if __name__ == '__main__':
cProfile.run('build()')
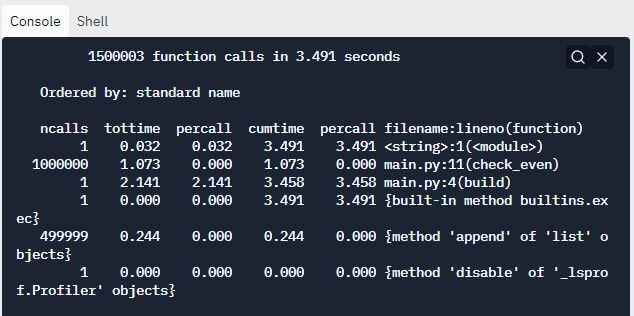
Output:
上面的 cProfile 报告清楚地表明 check_even 方法已被调用 1000000 次。这是不必要的,并且会影响我们代码的性能。
因此,我们可以通过消除此函数调用并在循环本身内执行所需的检查来优化代码,如下面的代码片段所示。
import cProfile
def build():
arr = []
for a in range(0, 1000000):
if a % 2 == 0:
arr.append(a)
if __name__ == '__main__':
cProfile.run('build()')
Output:
我们成功地消除了代码中不必要的函数调用,从而显着提高了代码的整体性能。
使用 GProf2Dot 可视化分析 识别瓶颈的最佳方法之一是可视化性能指标。 GProf2Dot 是一个非常有效的工具,可以可视化我们的分析器生成的输出。
Example: 假设我们正在分析以下代码片段:
import cProfile
import pstats
def build():
arr = []
for a in range(0, 1000000):
arr.append(a)
if __name__ == '__main__':
profiler = cProfile.Profile()
profiler.enable()
build()
profiler.disable()
stats=pstats.Stats(profiler).sort_stats(-1)
stats.print_stats()
stats.dump_stats('output.pstats')
安装
pip install gprof2dot 注意:要可视化图表,您必须确保已安装 Graphviz。您可以从以下链接下载:https://graphviz.org/download/
生成 pstats 文件
python -m cProfile -o output.pstats demo.py
可视化统计数据
gprof2dot -f pstats output.pstats | "C:\Program Files\Graphviz\bin\dot.exe" -Tpng -o output.png
就这样。您会发现在同一目录中生成了一个 PNG 文件,如下所示:
注意:在 Windows 中从 pstats 文件创建图表时,您可能会遇到特殊错误。因此,最好使用点文件的完整路径,如上所示。
使用snakeviz可视化分析 可视化 pstats 输出的另一种令人难以置信的方法是使用 Snakeviz 工具,它可以让您清楚地了解资源的利用情况。您可以使用 pip 安装程序来安装它:“pip install Snakeviz”。
安装snakeviz工具后,您需要从命令行执行代码并生成.prof文件。生成 .prof 文件后,您必须执行以下命令才能在浏览器上可视化统计信息:
snakeviz demo.prof Example: 在下面的代码中,我们将可视化嵌套函数如何消耗资源。
def build():
arr = []
for a in range(0, 1000000):
if check_even(a):
arr.append(a)
def check_even(x):
if x % 2 == 0:
return x
else:
return None
build()
To visualize the output using snakeviz, use the following command on your terminal.
Snakeviz 展示了两种可视化风格:冰柱和旭日。默认样式为Icicle,其中不同部分代码消耗的时间以矩形的宽度表示。
而在旭日视图的情况下,它由弧的角度范围表示。让我们看一下上面代码的冰柱和旭日视图。
图 1 – SnakeViz 冰柱视图
图 2 – SnakeViz Sunburst 视图
Python 线路分析器 CProfiler 允许我们检测代码中每个函数消耗了多少时间,但它不提供代码中每一行所花费时间的信息。
有时,仅在函数调用级别进行分析并不能解决问题,因为当从代码的不同部分调用某个函数时,它会导致混乱。
例如,该函数可能在 call#1 下执行良好,但会降低 call#2 下的性能。这无法通过功能级别分析来识别。
因此,Python 提供了一个名为 line_profiler 的库,它使我们能够对代码执行逐行分析。
在下面的示例中,我们将直观地展示如何从 shell 使用 line_profiler。给定的代码片段有一个 main() 函数,该函数调用其他三个函数。
主函数调用的每个函数都会生成 100000 个随机数并打印它们的平均值。
每个函数中的 sleep() 方法可确保每个函数花费不同的时间来完成操作。
为了能够可视化行分析器生成的输出,我们为脚本中的每个函数使用了 @profile 装饰器。
import time
import random
def method_1():
time.sleep(10)
a = [random.randint(1, 100) for i in range(100000)]
res = sum(a) / len(a)
return res
def method_2():
time.sleep(5)
a = [random.randint(1, 100) for i in range(100000)]
res = sum(a) / len(a)
return res
def method_3():
time.sleep(3)
a = [random.randint(1, 100) for i in range(100000)]
res = sum(a) / len(a)
return res
def main_func():
print(method_1())
print(method_2())
print(method_3())
main_func()
我们可以使用以下命令来执行并分析上面的代码片段:
kernprof -l demo_line_profiler.py 注意:您必须先安装线路分析器,然后才能在其帮助下执行逐行分析。要安装它,请使用以下命令:
pip install line-profiler kernprof 命令在完成对整个脚本的分析后会生成 script_name.lprof 文件。 .lprof 文件被创建并驻留在同一项目文件夹中。
现在,在终端中执行以下命令以可视化输出:
python -m line_profiler demo_line_profiler.py.lprof 从上面的输出可以明显看出,线路分析器已为每个函数生成了一个表。让我们了解一下表中每一列的含义。
使用 Pyinstrument Pyinstrument 是一个统计 Python 分析器,与 cProfile 非常相似。但与 cProfile 分析器相比,它具有一定的优势。
使用 Pyinstrument 的另一个巨大优势是可以通过多种方式可视化输出,包括 HTML。您甚至可以查看完整的通话时间线。
然而,使用 Pyinstrument 的一个主要缺点是它在处理多线程中运行的代码时效率不高。
示例:在下面的脚本中,我们将生成几个随机数并求它们的总和。然后我们将把总和附加到一个列表中并返回它。
pip install pyinstrument
import random
def addition(x, y):
return x + y
def sum_list():
res = []
for i in range(1000000):
num_1 = random.randint(1, 100)
num_2 = random.randint(1, 100)
add = addition(num_1, num_2)
res.append(add)
return res
if __name__ == "__main__":
o = sum_list()
我们可以使用以下命令执行代码以可视化 pyinstrument 输出:
pyinstrument demo_pyinstrument.py
使用雅皮 另一种 Python 分析器,缩写为 Yappi,是用 C 语言设计的 Python 分析器。它支持多线程代码的分析。它执行功能级分析。
它还允许我们以多种格式格式化分析输出,例如 callgrind 和 pstat。
Yappi 利用我们的能力来决定是否要分析 CPU 时间或挂起时间。
CPU 时间是代码使用 CPU 所花费的总时间,而 walltime 是代码运行的时间,从第一行到最后一行。
Yappi 将输出存储为 stat 对象,使我们能够过滤分析结果并对它们进行排序。我们可以在 Yappi 的帮助下调用、启动、停止和生成分析报告。
Example: 在下面的代码中,我们有一个函数,它会迭代 100000 个数字,并将每个数字加倍,然后将其附加到列表中。然后我们将使用 Yappi 对其进行分析。
def addition(x, y):
return x+y
def sum_list():
res = []
for i in range(10000):
out = addition(i, i)
res.append(out)
return res
if __name__ == "__main__":
o = sum_list()
Output:
使用 Palanteer Palanteer 是另一个分析工具,可用于分析 Python 和 C++ 代码。
因此,如果您处理包装 C++ 库的 Python 代码并且希望深入了解应用程序的组件,那么它是您的武器库中的一个强大工具。
Palanteer 使用一个 GUI 应用程序来显示结果,这使得动态跟踪和可视化统计数据非常有用。
Palanteer 跟踪几乎所有性能参数,从函数调用到操作系统级内存分配。
然而,palanteer 的问题是你必须从头开始构建它,即从源头开始构建它。它还没有预编译的二进制文件。
Python 内存分析器 我们已经经历了一个充满分析器和示例的世界,这些示例演示了如何分析代码以测量其执行时间。
还有其他因素(例如内存使用情况)决定了代码的性能。
因此,为了可视化代码中不同资源的内存使用情况,Python 为我们提供了一个内存分析器来测量内存使用情况。要使用内存分析器,您必须使用 pip 安装它:
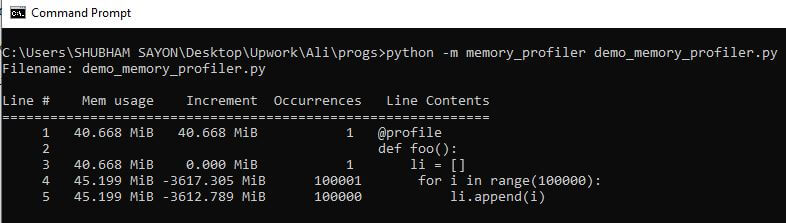
pip install -U memory_profiler 就像行分析器一样,内存分析器用于跟踪逐行内存使用情况。您必须使用 @profile 装饰器装饰每个函数以查看使用统计信息,然后使用以下命令运行脚本:
python -m memory_profiler script_name.py 在下面的代码中,我们将在列表中存储 100000 范围内的值,然后借助内存分析器可视化内存使用情况。
@profile
def foo():
li = []
for i in range(100000):
li.append(i)
foo()
Output:
蟒蛇Pympler 在许多情况下,需要借助对象来监视内存使用情况。这时,称为 pympler 的 Python 库就可以方便地满足要求。
它为我们提供了以各种方式监视内存使用情况的模块列表。
在本教程中,我们将了解assizeof 接受一个或多个对象作为输入并返回每个对象的大小(以字节为单位)的模块。
pip install Pympler 示例:在下面的代码中,我们将创建几个列表并存储两个不同范围内的值,然后使用 pympler 库的 asizeof 模块找出每个列表对象占用的大小。
from pympler import asizeof
li_1 = [x for x in range(100)]
li_2 = [y for y in range(100000)]
print("Space occupied by li_1 : %d bytes"%asizeof.asizeof(li_1))
print("Space occupied by li_2 : %d bytes"%asizeof.asizeof(li_2))
print("Space occupied by li_1 + li_2: %d bytes"%asizeof.asizeof(li_1,li_2))
Output: