一、数据库简介
数据库是存放数据的仓库
特征:数据结构化,数据共享,减少冗余,数据独立
数据库管理系统(DBMS):管理数据库的系统,按一定数据模型组织数据。Mysql是一个小型关系数据库管理系统。
1.1.常见数据库
数据库分为关系型数据库(RDMS:Relation DataBase Management System)和非关系型数据库
关系型数据库:数据以表的形式存在(有表的概念)
非关系型数据库:数据以key,value、文本、图片等形式存储(没有表的概念)
关系型数据库:oracle(大型项目使用:银行、电信),mysql(web项目使用最广泛),microsoft sql server(微软项目使用较多),sqlite(轻量级数据库,用于移动平台)
非关系型数据库:mingodb(文档数据库,没有表结构的概念),redis(键值对型数据库)
1.2.数据库模型
层次模型,网状模型,关系模型
1.3.关系型数据库
关系型数据库:使用关系模型(记录组或二维数据表)把数据组织到数据表中
数据行:一条记录(元组)
数据列:字段(属性)
数据表:数据行的集合(关系数据库基本存储结构,由行,列组成)
数据库:数据表的结合
关系型数据库语言:SQL(结构化查询语言),可以用于数据查询(DQL:select)、数据操纵(DML:update,insert,delete)、数据定义(DDL:create,drop)和数据控制(DCL:grant,remoke)
主键(码):数据表的唯一标识,不能为空
成绩中的主键是学号+课程号(多对多)

二、软件的安装与使用:mysql+navicat
2.1.安装
mysql特点:开源、社区版免费、支持多平台(windows,mac)/多语言(java,python)
mysql的msi删除与安装
mysql的压缩包删除与安装 mysql安装时找不到MSVCR120.dll
2.2.启动关闭mysql服务
windows下启动和关闭mysql服务,都需要以管理员方式打开cmd(C:\Windows\System32\cmd.exe,右键以管理员方式打开)进行执行
1.启动服务:net start mysql ,也可以打开任务管理器 – 服务 – 找到mysql – 右键开始
2.登录:mysql -u root -p,输入密码
3.查看所有数据库:show databases
4.关闭服务:net stop mysql,也可以打开任务管理器 – 服务 – 找到mysql – 右键停止
linux下启动mysql服务并使用navicate连接
1.启动服务:systemctl start mysqld
2.登录:mysql -u root -p,输入密码
3.查看所有数据库:show databases
4.关闭服务:service mysql stop
2.3.mysql连接navicat
1.linux系统下执行ifconfig命令获取ip地址
2.打开navicate,连接 - 输入连接名,刚获得的IP地址,用户名密码
3.注意:以下几个默认数据库不要随便使用
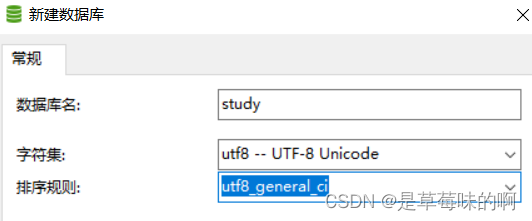
4.新建数据库
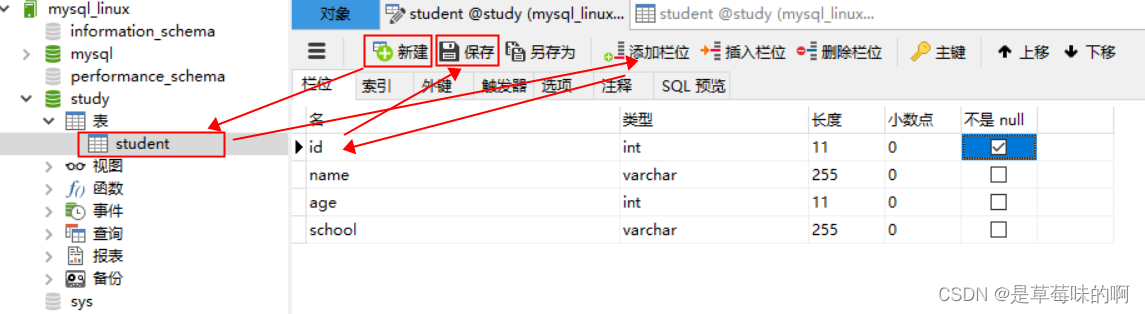
5.添加表字段(设计表)
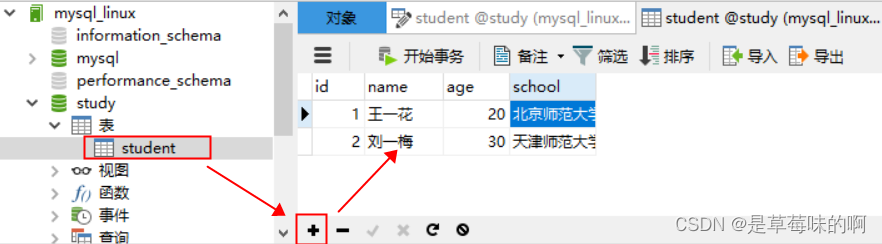
6.添加表数据(行)
三、数据库基本概念
3.1.数据类型
1.数值类型
①.整型:tinyint(1字节,八位二进制,范围0-255) ,smallint(2字节,范围大 ),int (有符号,范围:-2147483648-2147483648;无符号,unsigned,范围0-4294967295),bigint;
②.浮点型(有两个参数,第一个参数代表数字的长度,第二个参数代表小数位)
单精度:float(a,b) /双精度:double(a,b) / 数字型:decimal(a,b)
decimal和float都可以用来表示浮点数,但是在数据库中,float是按照近似值存的,decimal是按照字符串保存的
例:3.1415可以用float(5,4)来设置 decimal(5,4)
2.字符串常用类型
①.char(3)是定长的,存入两个,会占三个字节
②.varchar(3)是可变长,不够的话会在后面加空格,但是取出数据的时候不会有空格,存入两个字符会占两个字节,范围(0-65533)
③.text长文本数据(比varchar保存的文本更长一些)
④.longtext
3.时间日期常用类型
①.date:yyyy-mm-dd
②.time:hh-mm-ss
③.datetime:yyyy-mm-dd hh-mm-ss
4.图片类型
①.blob
3.2.约束

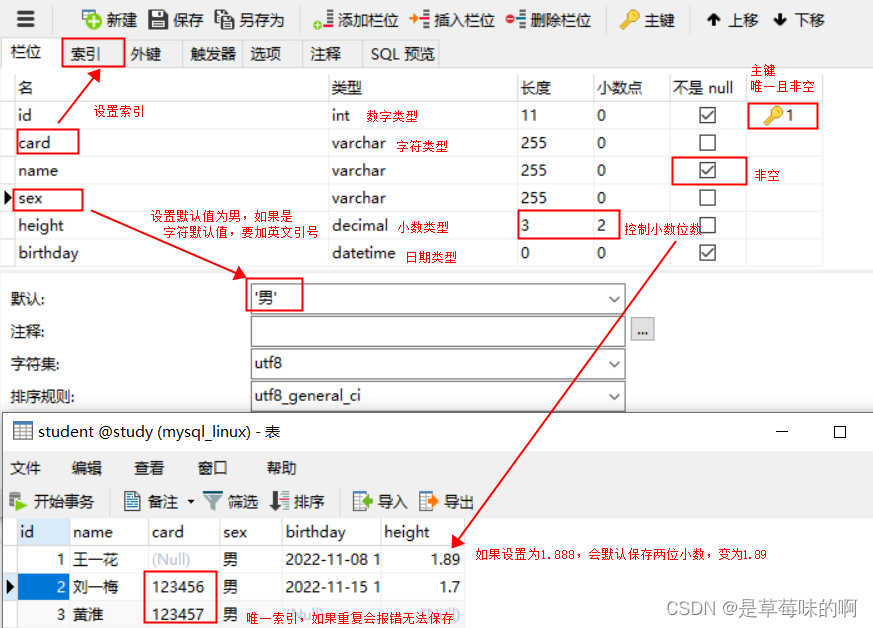
3.3.数据库备份
备份的场景:1.在测试中,为了防止数据库产生错误操作,2.清理产生的垃圾数据(例如在自动化测试中,对注册模块生成的所有数据,都属于典型的垃圾数据,应该清理)
备份还原方法:图形化工具navicate
备份:右键需要备份的数据库 – 转储sql文件 – 结构和数据(或者仅结构)-- 找到位置存储导出的sql文件
还原:右键需要还原的数据库 – 运行sql文件 – 找到之前导出的sql文件运行即可
备份还原方法2:命令行
进入数据库命令行模式:mysql -uroot -p123456(当出现mysql>就行了)
退出数据库命令行模式:exit
备份:mysqldump -u数据库用户名 -p 目标数据库名 > 备份后文件名.sql:mysqldump -uroot -p study > study.sql
还原:mysql -u数据库用户名 -p 新数据库名 < 要恢复的sql文件名.sql:mysql -uroot -p study < study.sql
3.4.linux操作数据库
连接数据库:mysql -uroot -p123456
show databases; use study; show tables; select * from student;
四、DDl数据定义语言
4.1.DDL操作数据库
-- 创建数据库:create database 数据库名 编码字符集 排序规则;
create database mybase1;
create database mybase2 character set utf8 collate=utf8_general_ci;
-- 查看所有数据库
show databases;
-- 查看某个数据库
show create database mybase2;
-- 使用某个数据库(切换数据库)
use mybase2;
-- 解决 navicate 在执行 use 数据库名 报错的问题,执行以下语句后再使用use语句就不会报错了
show variables like "sql_mode";
set sql_mode='';
set sql_mode='no_engine_substitution,strict_trans_tables';
-- 查看当前在使用数据库(database()是SQL内置函数,括号不能省略)
select database();
-- 修改数据库编码
alter database mybase2 character set gb2312;
alter database mybase2 character set utf8 collate=utf8_general_ci;
-- 删除数据库
drop database [if exists] mybase2;
4.2.DDL操作表
-- 创建表(创建表每一句都是逗号,最后一个不带逗号)
create table [if not exists] exam(
// 字段名 类型 约束
// 列名 数据类型 无符号 主键 自动增长 不为空
id int(11) unsigned primary key auto_increment not null,
//default是默认值
name varchar(20) not null,
height decimal(3,2),
sex varchar(1) default '女'
//tinyint为1位短整型null为允许为空
sunscore tinyint(1) null,
photo bolb,
// 主键也可以提取到下面,以便多主键时使用,例如设置sno和cno的属性组为主键primary key(sno, cno)
primary key (id)
) default charset=utf8
-- 查看所有表
show tables;
-- 查看创建的表信息
show create table exam;
-- 显示表里面的内容
desc exam;
-- 删除表
drop table [if exists] exam;
-- 修改表的字符集
alter table exam character set gbk;
-- 修改表名
rename table exam to exam1;
-- 添加列
alter table exam add [column] history int not null;
-- 修改列类型
alter table exam modify history double(5,1);
-- 修改列名
alter table exam change history art double(5,1);
-- 删除列
alter table exam drop art;
-- 复制表(只复制表的缩影和结构)
五、DML数据操纵语言
5.1.增删改
-- 插入记录
-- 插入一条记录的部分列
insert into exam (id,name,english,chinese,math) values(2,'张三',90,90,90);
-- 插入多条记录
insert into exam (id,name,english,chinese) values(null,'张三',90,90),(null,'李四',90,90),(null,'王五',90,90);
-- 插入一条记录的全部列(数据个数和类型要与表结构一一对应,主键可以为0或者null进行占位)
insert into exam values(null,'李四',90,90,100);
-- 插入多条记录
insert into exam values(null,'李四',90,90,100),(null,'李四',90,90,100),(null,'王五',90,90,100);
-- 插入图片,图片最好放在mysql的目录下,以免发生权限问题
create table photo(
stuphoto bolb
);
insert into photo('E:\mysql\Install\1.PNG');
-- 修改记录
-- 修改全部记录
update exam set name='王五',math=80;
--修改id=5的记录
update exam set name='孙刘',math=89 where id=5;
-- 删除记录
-- 删除全部记录
delete from exam;
-- 删除部分记录
delete from exam where id=5;
5.2.逻辑删除和物理删除
逻辑删除是通过某个字段的特定值表示数据是删除(0)或者未删除(1)状态
isdelete,查询时过滤出isdelete=1的就可以查到未删除的
update exam set isdelete=0 where id=1;
select * from exam where isdelete=1;
物理删除是真实在数据库上删除了这一条记录
delete from exam where id=1;
drop,delete,truncate在表操作上的区别
①.delete from exam;-- 删除表的所有内容,但不清空auto_incremenet(主键),下次再添会把原来的自增1
②.truncate table exam;-- 删除表的所有内容,并清空auto_incremenet
③.drop table exam;-- 删除整张表(包括数据和表结构)
六、DCL数据控制语言
6.1.使用HeidiSQL设置权限
可以使用管理用户认证和权限来添加删除用户,以及设置添加删除等权限.
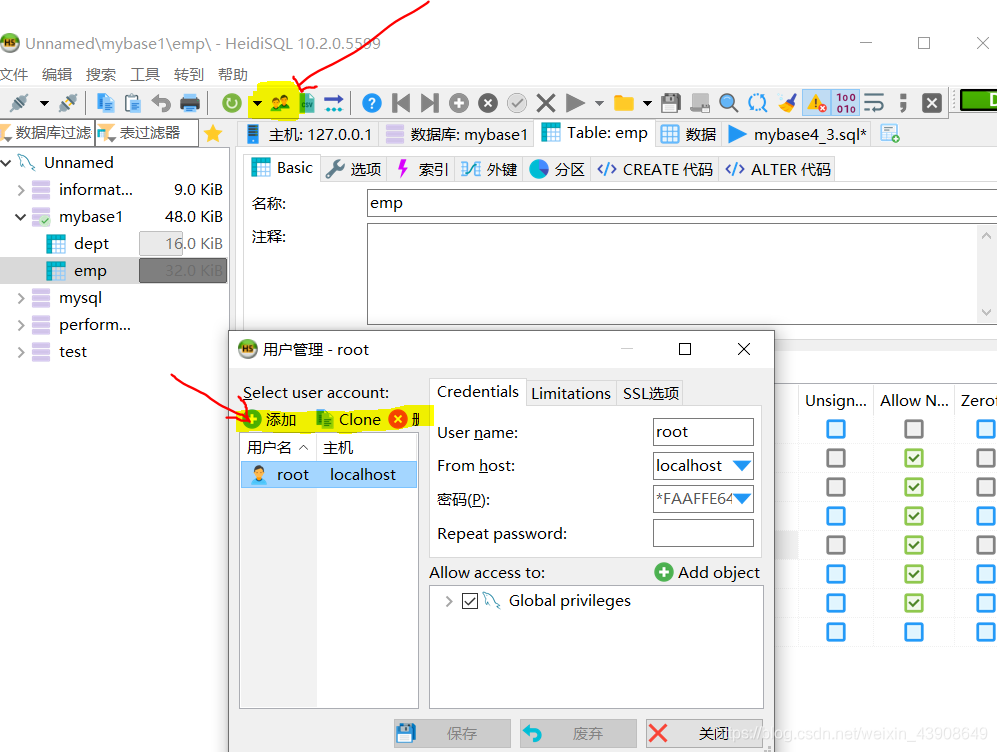
6.2.使用命令行来设置权限
win+R打开cmd

6.3.练习
创建用户:
mysql> create user apple@localhost identified by 'root123';
给用户授权:
mysql> grant select,drop on mysql.*to apple@localhost;
撤销权限://本用户不能撤销自己的权限,需要用其他用户来撤销
mysql> revoke select on mysql.* from apple@localhost;
删除用户:
mysql> drop user apple@localhost;
登录:
C:\Users\dada>mysql -uroot -proot123.
退出登录:
mysql> exit;
查看表数据:
mysql> select * from host;/mysql> select * from db;
查看表结构:
mysql> desc host;
删除表全部记录:
mysql> delete from host;//没有赋予此权限就不能使用
显示表的所有权限:
mysql> show grants for root@localhost;
七、DQL数据查询语言
7.1.全表查询
– 全表查询: select * from表;
– 查询部分字段: select字段,字段,字段.from表;
– 过滤重复字段行: select [distinct] 列名,列名 from 表名;
– 查询字段起别名: select字段 as新字段名,字段 新字段名from表;
小练习
create table exam(
id int(11) primary key auto_increment,
name varchar(20),
english int,
chinese int
)
insert into exam values (null, '张三',85,74);
insert into exam values (null,'李四',95,90);
insert into exam values (null, '王五',89,84);
-- 查询所有记录:
select * from exam;
-- 查询这个班级人的姓名和英语成绩:
select name,english from exam;
-- 查询英语成绩,将重复英语成绩去掉:
select distinct english from exam;
-- 显示这个人的名称和对应总成绩的分数:(使用as起别名,as可以省略)
select id,name,english+chinese+math as Allscore from exam;
7.2.条件查询
-- where语句后面可以加条件限制,条件关键字: =,>,>=, <, <=, <>
-- 模糊查询like+通配符:_下划线(前面只能有一个字符),%匹配(前面可有任意多个字符)
-- 使用and,or
-- 使用in,not in
-- between...and...(数值类型和日期类型)
-- is null,is not null:空值NULL比较的时候不能使用" ="号,必须使用is null
-- 查询或条件中使用表达式:当查询需要对选出的字段进行进一步计算,可以在数字列上使用算术表达式(+,-,*,/)
小练习
create table emp(
empno int primary key auto_increment,
ename varchar(20),
job varchar(20),
mgr int,
hiredate date,
sal double(7,2),
comm double(5,2),
deptno int not null
)
insert into emp (empno,ename,job,mgr,hiredate,sal,comm,deptno) values
(1002, '白展堂','manger',1001, '1983-05-09', 7000.00 ,200.00,10),
(1003, '李大嘴','clerk' ,1002, '1980-07-08', 8000.00 ,100.00,10),
(1004, '吕秀才','clerk' ,1002, '1985-11-12', 4000.00 ,NULL, 10),
(1005, '郭美蓉','clerk' ,1002, '1985-03-04', 4000.00 ,NULL, 10),
(2001, '胡一菲','leade' ,NULL, '1994-03-04', 15000.00,NULL, 20),
(2002, '陈美嘉','mange' ,2001, '1993-05-24', 10000.00,300.00,20),
(2003, '吕子乔','clerk' ,2002, '1995-05-19', 7300.00 ,100.00,20),
(2004, '张益达','clerk' ,2002, '1994-10-12', 8000.00 ,500.00,20),
(2005, '曾小贤','clerk' ,2002, '1993-05-10', 9000.08 ,700.00,20),
(3001, '刘晓梅','leade' ,NULL, '1968-08-08', 13000.00,NULL ,30),
(3002, '夏冬梅','mange' ,3001, '1968-09-21', 10000.00,600.00,30),
(3003, '夏雪儿','clerk' ,3002, '1989-09-21', 8000.00 ,300.00,30);
-- 查询职员表中薪水低于10000元的职员信息
select * from emp where sal<10000;
-- 查询职员表中不属于部门10的员工信息(!=等价于<>)
select * from emp where deptno<>10;
-- 查询职员表中在1993年05月10号入职的职员信息,比较日期类型数据
select * from emp where hiredate in('1993-05-10');
-- 查询薪水大于5000并且职位是clerk的职员信息
select * from emp where sal>5000 and job='clerk';
-- 查询薪水大于5000或者职位是' K'结尾的职员信息
select * from emp where sal>5000 or job like '%k';
-- 查询职位是leader或者manager的员工
select * from emp where job in('leade','mange');
-- 查询不是部门10或20的员工
select * from emp where deptno not in(10,20);
-- 查询薪水在5000-10000之间的职员信息
select * from emp where sal between 5000 and 10000;
-- 查询哪些职员的奖金数据为NULL
select * from emp where comm is null;
-- 查询年薪高于100000的职员信息
-- sql语句执行,先是from,再是where,最后才是查询select
select empno,ename,job,sal*12 as yearsal from emp where sal*12>100000;
7.3.排序查询
一列排序:select *from 表名 [where子句] order by字段[asc desc]
多列排序:select *from 表名 [where子句] order by字段[asc|desc] ,字段[asc]desc]…
注意
asc是升序(默认),desc是降序
order by必须出现在select中的最后一个子句,不能放在where之前
多列排序首先按照第一列进行排序,第一列数据相同,再以第二列排序,以此类推
多列排序时,不管正序还是倒序,每个列需要单独设置排序方式
小练习
-- 查询所有学生的信息,并且按语文成绩进行排序.
select * from exam order by chinese desc;-- 降序
select * from exam order by chinese asc; -- 升序
select * from exam order by chinese; -- 不写默认是升序
-- 查询学生的信息,按照英语成绩降序排序,如果英语成绩相同按照语文降序.
select * from exam order by english desc,chinese desc;
7.4.聚合函数
查询时多行数据参与运算返回一行结果,也称作分组函数、多行函数、集合函数
– sum() :求和
– count() :做统计
– max() :求最大
– min() :求最小
– avg() :求平均
– 对空值的处理:
– IFNULL(exprl,expr2) :如果expr1不是null,则直接返回expr1的值,否则返回expr2
小练习
-- 查询每个学生总成绩:
select sum(chinese+english) from exam where id=2;
-- 统计学生的个数:
select count(*) from exam;
-- 统计英语成绩的最高分:
select max(english) from exam;
-- 统计语文成绩的最低分:
select min(chinese) from exam;
-- 统计英语成绩平均分:
select avg(english) from exam;
7.5.分组查询
– group by子句
– 对结果集按照给定字段值相同的记录进行分组
– 配合聚合函数使用
– by后面有什么字段,查询时就可以保留什么字段,这样就比较有意义
– having子句
– 用来对分组后的结果进一步限制
– 查询语句执行顺序
– 5select 1from 2where 3group by 4having 6order by
– where与having的区别
– where过滤记录,having过滤分组
– 过滤时机不同,先where后having
– where是在查询表时逐行过滤以选取满足条件的记录
– having是在数据查询后并且分完组后对分组进行过滤的,以决定分组的取舍
– having必须跟在group by后面
小练习
-- 查询每个职位的最高工资和最低工资?
select job,max(sal),min(sal) from emp group by job;
-- 查询每个部门每种职位的最高工资?
select deptno,job,max(sal) from emp group by deptno,job;
-- 查询每个部门的最高薪水,只有最高薪水大于15000的记录才被输出显示?
select deptno,max(sal) as maxsal from emp group by deptno having maxsal>=15000;
-- 查询每个部门平均工资,前提是该部门的平均工资高于9000
select deptno,avg(sal) as avgsal from emp group by deptno having avgsal>=9000;
7.6.分页查询
– 知识点
– 分页查询使用的是limit关键字进行查询。
– 第一个参数:起始位置,第二个参数:每页需要显示的条目数
– 按页查询取值为: (需要查看第几页-1)乘以第二个参数
小练习
-- 展示前三条职员信息:
select * from emp limit 0,3;
-- 展示3,4,5,6四条职员信息
select * from emp limit 3,4;
-- 展示第三页,每一页都有5条,查询第三页,第一个参数为(3-1)*5
select * from emp limit 10,5;
-- 展示第二页,每一页都有2条,查询第二页,第一个参数为(2-1)*2
select * from emp limit 2,2;
-- 查看工资最高的前十个职员信息:
select * from emp order by sal desc limit 0,10;
7.7.单表约束
主键: primary key (默认唯一且非空,用来保证数据完整性,一个表只能有一个主键)
唯一: unique
非空: not null
设置方法
-- 1.创建表,主键字段后创建
create table exam(
id int(11) primary key,
name varchar(20) unique,
chinese int not null
)
-- 2.创建表,表的所有属性后创建
create table exam(
id int(11),
name varchar(20) unique,
chinese int not null,
primary key (id)
)
-- 3.修改表,发生在表创建好了之后
alter table exam modify id int(11) primary key;
alter table exam modify name varchar(21) unique not null;
7.8.外键约束
外键: foreign key (和其他表建立联系,从表的属性可以是主表的主键,外键关联属性可以重复,可以为空,一个表可以有多个外键)
如果表A的主键是表B中的字段,则该字段称为表B的外键,表A称为主表,表B称为从表
注意
从表任何记录都可以随便删,主表只能删除没有从表依赖的项,删除表要先删除从表
添加外键约束前提:主表一定要设置主键
大量外键会影响数据查询操作以外的其他操作(增删改)的操作效率,项目中很少用到,基本上都使用关联表,进行左右连接查询实现
-- 1.添加外键,表的所有属性后创建
create table emp( -- 员工表
id int primary key,
name varchar(21),
age int,
deptno int,
// constraint设置外键的名字
constraint my_deptno forigen key(deptno) references dept(id)
)
create table dept( -- 部门表
id int primary key,
dname varchar(21),
loc varchar(21)
)
-- 2.修改外键,修改列的约束类型时必须加上属性的数据类型:alter table 从表 add foreign key (从表外键字段) references 主表(主键字段);
alter table emp add foreign key(deptno) references dept(id);
-- 3.删除外键
alter table emp drop foregin key deptno;
7.9.索引
作用:提高查询速度,快速查找特定值的记录,一个表只能有一个
注意:大量外键会影响数据查询操作以外的其他操作(增删改)的操作效率
-- 开启运行时间监测
set profiling=1;
-- 查询第10000条数据
select * from nucleic_acid where num='10000';
-- 查看执行时间
show profiles;
-- 创建索引,将表的num字段添加为索引
-- carete index 表名 on 表名(字段名);
carete index nucleic_acid on nucleic_acid(num);
-- 查询第10000条数据
select * from nucleic_acid where num='10000';
-- 查看执行时间
show profiles;
-- 删除索引
-- drop index 索引名称 on 表名;
drop index num on nucleic_acid;
7.10.多表查询
知识点
– 笛卡尔积: select * from A,B;](将主表的记录都拼接到从表中)
– 等值连接: select * from A,B where A.主键=B.外键;
– 内连接: select * from A inner join B on A.主键=B.外键;(inner可以省略)
– 左外连接: select * from A left outer join B on条件;
(左边的表全存在,右边的如果匹配不上就用null来连接)
– 右外连接: select * from A right outer join B on条件
– 子查询结果若为单行单列: select * from 表名 where 字段 =,>,<… (子查询)
– 子查询结果若为多行单列: select * from 表名 where 字段 in/not in (子查询)
– 自连接:自己与自己连接
(on比where起作用更早,先根据on条件进行多表的连接操作,生成一个临时表再通过where来筛选)
小练习
-- 等值查询/内连接练习(等值连接和内连接的结果相同)
-- 查看每个员工的名字以及其所在部门的名字?//先执行from,在执行select,再执行where
select e.ename,d.dname,d.loc from emp e ,dept d where e.deptno=d.deptno;
-- 查看工作地点在北京的员工有哪些?
select * from emp inner join dept on emp.deptno=dept.deptno where dept.loc='北京';
-- 外连接练习
-- 查看每个城市员工的平均工资?]//ifnull(avg(sal),0)代表如果结果是空,显示0,如果不是显示avg(sal)
select dept.loc,ifnull(avg(sal),0) from emp right join dept on emp.deptno=dept.deptno group by dept.loc;
-- 查看工作地点在上海的员工有哪些?
select emp.*,dept.dname,dept.loc from emp left outer join dept on emp.deptno=dept.deptno where dept.loc='上海';
-- 子查询练习
-- 查找和曾小贤同职位的员工?
select * from emp where job=(select job from emp where ename='曾小贤');
-- 查找薪水比整个机构平均薪水高的员工?
select * from emp where sal>(select avg(sal) from emp);
-- 查询出部门中有CLERK但职位不是CLERK的员1的信息?
select * from emp where deptno in(select distinct deptno from emp where job='clerk') and job<>'clerk';
-- 查看每个城市员工的平均工资?
select dept.loc,avg(sal) from emp inner join dept on emp.deptno=dept.deptno group by dept.loc;
-- 查询列出最低薪水高于部门20的最低薪水的部门信息?(子查询在having子句中)
select deptno,min(sal) as minsal from emp group by deptno having minsal>(select min(sal) from emp where deptno=20);
-- 自连接练习
-- 列出所有员工的姓名及其直接上级的姓名?
select e1.ename as emploee,e2.ename as boss from emp e1 left join emp e2 on e1.mgr=e2.empno;
八、ER模型
数据库有效存储现实世界中有意义的数据,通过E-R图能更有效的模拟现实世界
E-R模型的脚本元素:实体、联系、属性
联系分类:一对一、一对多、多对多
举个栗子:学生、老师、班级是三个实体,后面的是属性,学生与班级关系属于多对一(一个学生只能属于一个班级,一个班级可以有多个学生),老师和班级的关系属于多对多(一个老师可以属于多个班级,一个班级也可以有多个老师)
一般多对多关系都会有一个中间表
学生(学号,姓名,年龄,性别,班级号)
班级(班级号,老师id)
老师(教师编号,姓名,年龄,性别,手机号,任教科目,班级号)
九、实践
-- 创建表:注意:要先创建引用表,外键的设置需要和引用表的数据类型一致
create table certificate(
id int unsigned primary key auto_increment,
certificate_name varchar(40)
)
create table category(
id int unsigned primary key auto_increment,
type_name varchar(40),
certificate_id int unsigned,
foreign key(certificate_id) references certificate(id)
)
create table goods(
id int unsigned primary key auto_increment,
goodsName varchar(10),
price int,
count int,
company varchar(20),
remark varchar(20),
type_id int unsigned,
foreign key(type_id) references category(id)
)
create table area(
id varchar(10) primary key,
name varchar(40),
pid varchar(10)
);
-- 插入数据,注意:引用表要先放入数据
insert into certificate values
(null,'行医资格证'),
(null,'食品资格证'),
(null,'安全资格证');
insert into category values
(null,'口罩',1),
(null,'药品',1),
(null,'科技',null),
(null,'玩具',null),
(null,'食品',2);
insert into goods values
(null,'三奇',25,100,'京东','三奇3Q口罩小孩',1),
(null,'三德儿',25,150,'淘宝','口罩一次性医用口罩成人',1),
(null,'袋鼠妈妈',30,180,'拼多多','袋鼠医用口罩',1),
(null,'京东京造',139,100,'淘宝',null,3),
(null,'红霉素',77,160,'京东','红霉素软膏',2),
(null,'闪电卫视',159,190,'微信小店','闪电VIP',null),
(null,'小度儿',30,100,'京东','小度音响',3),
(null,'奇儿',25,100,'淘宝','米奇玩偶',4);
insert into area values
('0000000','河南省',null),
('1111111','福建省',null),
('2222222','安徽省',null),
('0000001','郑州市','0000000'),
('0000002','洛阳市','0000000'),
('0000003','信阳市','0000000'),
('1111112','福州市','1111111'),
('1111113','南平市','1111111'),
('2222223','合肥市','2222222'),
('2222224','芜湖市','2222222'),
('2222225','安庆市','2222222'),
('0000010','中原区','0000001'),
('0000011','二七区','0000001'),
('0000012','金水区','0000001'),
('0000013','惠济区','0000001'),
('0000014','郑东新区','0000001'),
('0000021','老城区','0000002'),
('0000022','偃师区','0000002'),
('0000023','洛龙区','0000002'),
('0000031','平桥区','0000003'),
('0000032','浉河区','0000003'),
-- 查询全部字段
select * from goods;
select * from area;
-- 查询部分字段
select id,goodsName,price from goods;
-- 起别名,所有商品打6.8折后的价格(as可省略)
select id,goodsName,price*0.68 discountPrice from goods;
-- 去重,显示所有公司
select distinct company from goods;
-- 【条件查询】
-- 比较运算:=,>,>=,<,<=,!=,<>
-- 逻辑运算:and[双边条件],or[双边条件],not[单边条件,只对右侧条件有用]
-- 模糊查询:%表示任意多字符,_表示一个任意字符
-- 范围查询:in表示非连续范围,between and表示连续范围
-- 空判断:is null,is not null
-- 单条件查询(比较运算),查询商品名不为袋鼠妈妈的
select * from goods where goodsName!='袋鼠妈妈';
select * from goods where goodsName<>'袋鼠妈妈';
-- 条件查询(逻辑运算and),查询价格为30-100的商品
select * from goods where price>=30 and price<=100;
-- 条件查询(逻辑运算or),查询价格为小于30,大于100的商品
select * from goods where price<30 or price>100;
-- 条件查询(逻辑运算not),查询非拼多多的商品
select * from goods where not company='拼多多';
-- 条件查询(逻辑运算not),查询非拼多多,但价格为25的商品
select * from goods where not company='拼多多' and price=25;
select * from goods where price=25 and not company='拼多多';
-- 多条件查询,查询价格为30并且出自拼多多的商品
select * from goods where price=30 and company='拼多多';
-- 条件查询(模糊查询%),查询所有描述包含口罩的商品
select * from goods where remark like '%口罩%';
-- 条件查询(模糊查询%),查询所有描述以口罩结尾的商品
select * from goods where remark like '%口罩';
-- 条件查询(模糊查询%),查询所有描述以口罩开头的商品
select * from goods where remark like '口罩%';
-- 条件查询(模糊查询_),查询所有商品名以三开头的两个字的商品
select * from goods where goodsName like '三_';
-- 条件查询(模糊查询_),查询所有商品名以儿结尾的两个字的商品
select * from goods where goodsName like '_儿';
-- 条件查询(范围查询in),查询公司为淘宝或京东的商品
select * from goods where company in ('淘宝','京东');
-- 条件查询(范围查询between and),查询商品价格为大于30,小于100的商品
select * from goods where price between 30 and 100;
-- 条件查询(空判断),查询没有描述信息的商品
select * from goods where remark is null;
-- 条件查询(空判断),查询有描述信息的商品
select * from goods where remark is not null;
-- 【排序】(desc降序,asc升序,默认升序)
-- 排序:按商品价格降序查询
select * from goods order by price desc;
-- 排序,按商品价格降序查询
select * from goods order by price asc;
-- 排序,按商品价格降序查询,价格相等按照数量升序查询
select * from goods order by price desc,count asc;
-- 【聚合函数】(不能在where子句中使用),count,max,min,avg,sum
-- 聚合函数(总数),查询商品总数
select sum(count) from goods;
-- 聚合函数,查询描述含有口罩的商品总数
select count(*) from goods;
-- 聚合函数(最大值),查询价格最高的商品
select max(price) as '最高价' from goods;
-- 聚合函数(最小值),查询价格最低的商品
select min(price) as '最低价' from goods;
-- 聚合函数(平均值),查询商品的平均价格
select avg(price) as '平均价' from goods;
-- 聚合函数(和),查询商品的价格总和
select sum(price) as '总价' from goods;
-- 【分组查询】(group by ... having ... 一般字段后面跟上聚合函数,having做查询后的条件过滤,相当于where,但group by后面不推荐使用having)
-- 分组查询,查询每家公司的商品信息数量
select company as '公司',count(*) as '店数',sum(count) as '商品总数' from goods group by company;
-- 分组查询(过滤),查询公司商品平均价格低于50的的公司
select company,avg(price) as avgPrice from goods group by company having avgPrice<50;
-- 【分页查询】(limit 起始行,行数,起始行可以省略,默认第一行为0)
-- 分页查询,查询当前表中第3-7行数据
select * from goods limit 3,4;
select * from goods limit 0,5;
select * from goods limit 5;
-- 每页显示m条数据,求显示第n页的数据
select * from goods limit (n-1)*m,m;
-- 第一页,一页5条
select * from goods limit 0,5;
-- 第二页,一页5条
select * from goods limit 5,5;
-- 第三页,一页5条
select * from goods limit 10,5;
-- 查询商品价格最贵的(前三条)数据信息(先根据价格进行降序排序,再分页查询第一条)
select * from goods order by price desc limit 0,1;
select * from goods order by price desc limit 0,3;
-- 【连接查询】(将不同的表通过特定关系连接)(等值连接,内连接inner join on,左连接:left join on,右连接,right join on)
-- 查询所有存在商品类型的商品信息
select * from goods where type_id is not null;
-- 等值连接(内连接的旧式写法,效率不高),查询商品信息及商品分类
select * from goods,category where goods.type_id = category.id;
select goods.*,category.type_name from goods,category where goods.type_id = category.id;
-- 内连接(两边关联字段为空的不显示)
select * from goods inner join category on goods.type_id = category.id;
select g.*,c.type_name from goods as g inner join category as c on g.type_id = c.id;
select g.*,c.type_name from goods g inner join category c on g.type_id = c.id;
-- 左连接(关联表没有关联值,被关联表数据以空显示,left join左边的是关联表,右边的是被关联表)
select g.*,c.* from goods g left join category c on g.type_id = c.id;
select g.*,c.* from category c left join goods g on g.type_id = c.id;
-- 右连接(被关联表没有关联值,关联表数据以空显示)
select g.*,c.* from goods g right join category c on g.type_id = c.id;
select g.*,c.* from category c right join goods g on g.type_id = c.id;
-- 三表查询,为啥要进行左右连接:因为有第三张表
select g.*,c1.*,c2.* from goods g right join category c1 on g.type_id = c1.id right join certificate c2 on c1.certificate_id = c2.id;
select g.*,c1.*,c2.* from goods g right join category c1 on g.type_id = c1.id left join certificate c2 on c1.certificate_id = c2.id;
-- 【自查询】(将同一个表通过特定关系连接,通过给表起别名的形式将原本一张表变为两张)
-- 查询河南省所有市
select a1.name province,a2.name city from area a1 inner join area a2 on a1.id=a2.pid where a1.name='河南省'
select a1.name province,a2.name city from area a1 left join area a2 on a1.id=a2.pid where a1.name='河南省'
-- 查询河南省所有市和区
select a1.name province,a2.name city,a3.name region from area a1 inner join area a2 on a1.id=a2.pid inner join area a3 on a2.id=a3.pid where a1.name='河南省'
-- 【子查询】(在一个查询中套入另一个查询的过程,辅助主查询语句,要么当条件,要么当数据,所以要放在括号里面提升优先级)
-- 查询价格高于平均价格的信息
select * from goods where price > (select avg(price) from goods);
-- 查询所有来自京东的商品,包含商品分类(如果子查询作为数据使用必须要提供新表名)
select g.*,c.type_name from goods g inner join category c on g.type_id=c.id;
select * from goods where company='京东'
select * from (select g.*,c.type_name from goods g inner join category c on g.type_id=c.id) as new where company='京东'