广度优先搜索(BFS)
如何理解广度优先搜索:如果对广度优先遍历没有一点点了解的同学建议先去看看树的层次遍历,其实这就是广度优先搜索的一个应用,层次遍历的大致思路就是:将二叉树按从上往下。从左往右逐层遍历二叉树;广度优先搜索其实也是这个思路,解题时关键就是看你在这个过程中需要做些什么;
如何实现广度优先搜索:
我们直到其实深度优先搜索是利用了栈的这个结构,所以我i们也可以利用递归实现深度优先搜索,而广度优先搜索是利用了队列这个结构,因为本人比较喜欢使用java语言所以我实现广度优先搜索一般就使用java自带的队列结构LinkedList类;
简单的描述广度优先搜索的大致过程:
首先将根节点入队列;然后判断队列是否为空,若不为空则将队列中的节点出队列(往往这个阶段我们就可以对出队列的节点进行某些操作),将节点出队列后,欧安段该节点是否有左右节点,若有将其左右节点入队列,然后重复判断队列是否为空及其后的操作,直到队列为空;
下面结合例题理解广度优先搜索:
广度优先遍历在树中的应用:
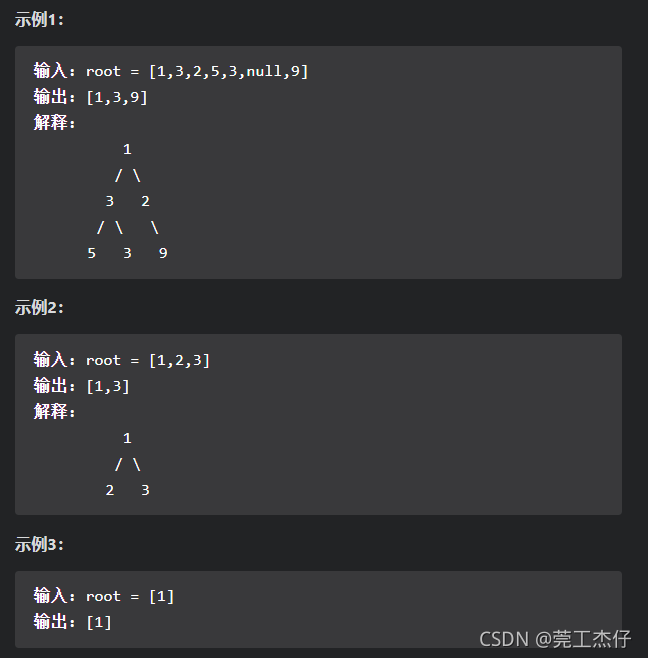
例题一:给定一个非空二叉树, 返回一个由每层节点平均值组成的数组。(力扣:637)
这题的思路和细节都放到代码中去了:
//利用队列广度优先遍历搜索该二叉树,并将没一层的节点值相加求平均值
class Solution {
public List<Double> averageOfLevels(TreeNode root) {
//建立一个队列用于保存每层二叉树的平均值
List <Double> list =new ArrayList <Double>();
//建立一个队列来施行深度优先遍历
Queue <TreeNode> queue=new LinkedList <TreeNode> ();
//将根节点入队列
queue.offer(root);
//广度优先遍历
while(!queue.isEmpty()){
double cout=0;
//记住一定要先保存每次队列的长度,不然经过里面的for循环后,队列的长度会不断变化
int size=queue.size();
int i;
//应为在同一阶段的队列中的节点肯定都是同一层的节点,所以将该层的节点相加并求平均值
//为什么我们可在队列中确切的数量呢?因为我们在啊上面记录了每次循环后的队列长度,即使后面的节点不断入队列
//也没有关系
for(i=0;i<size;i++){
TreeNode temp=queue.poll();
cout=cout+temp.val;
if(temp.left!=null){
queue.offer(temp.left);
}
if(temp.right!=null){
queue.offer(temp.right);
}
}
//将每层节点的平均值用list保存起来
list.add(cout/size);
}
return list;
}
}
例题2:在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处。如果二叉树的两个节点深度相同,但 父节点不同 ,则它们是一对堂兄弟节点。我们给出了具有唯一值的二叉树的根节点 root ,以及树中两个不同节点的值 x 和 y 。只有与值 x 和 y 对应的节点是堂兄弟节点时,才返回 true 。否则,返回 false。力扣(993)
理解:又是一道典型的广度优先遍历题,这道题的困难点就在于如何判断x,y是否拥有相同的父节点,一开始这个问题我是没有办法解决的,我看了题解找到的方法,那就是先判断各个父节点的左右孩子节点是否为x,y我一开始想的始一旦有两个x或y这不就错了吗?看来始我想多的,书中的节点的值补重复
//这道题额第一感觉要使用广度优先遍历来解题,看看能否解出
class Solution {
//创建一个变量来判断结果
boolean pd=false;
//创建一个队列实现广度优先遍历算法
Queue <TreeNode> queue=new LinkedList <TreeNode>();
public boolean isCousins(TreeNode root, int x, int y) {
//首先将根节点入队列
queue.offer(root);
while(!queue.isEmpty()){
//在每一层节点中去寻找x,y
int size=queue.size();
//使用一个HashSet来判断是否有两个节点
HashSet <Integer> set=new HashSet <Integer>();
for(int i=0;i<size;i++){
//保存出队列的节点
TreeNode temp=queue.poll();
//判断x,y是否为兄弟节点如果是直接返回false
if(temp.left!=null&&temp.right!=null){
if(temp.left.val==x&&temp.right.val==y||temp.left.val==y&&temp.right.val==x) {
return false;
}
}
//如果该节点的值等于x或者y,将该值加入set
if( temp.val==x|| temp.val==y){
set.add(temp.val);
}
//判断set中是否含有两种类型的数值
if(set.size()==2){
pd=true;
}
//将该节点的左右节点加入队列
if(temp.left!=null){
queue.offer( temp.left);
}
if(temp.right!=null){
queue.offer( temp.right);
}
}
}
return pd;
}
}
例题三:从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。(力扣:剑指 Offer 32 )
//典型的层次遍历也就是bfs
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
//创建一个队列来实现广度优先遍历
Queue <TreeNode> queue =new LinkedList();
//创建一个集合保存结果
List<List<Integer>> list=new ArrayList<List<Integer>>();
//当root为null需要返回的是[],一个空集合
if(root==null){
return list;
}
//将根节点入队列
queue.offer(root);
//BFS
while(!queue.isEmpty()){
//记住这一步几乎是使用队列实现广度优先遍历最为关键的一步
int l=queue.size();
//集合list1必须为一个局部变量,每完成一次大的循环就重新生成一个list1
List <Integer> list1=new ArrayList<Integer>();
//按层将元素放入集合list1中
for(int i=0;i<l;i++){
TreeNode temp=queue.poll();
list1.add(temp.val);
if(temp.left!=null){
queue.add(temp.left);
}
if(temp.right!=null){
queue.add(temp.right);
}
}
//将list1放进List中
list.add(list1);
}
return list;
}
}
**例题四:**给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。初始状态下,所有 next 指针都被设置为 NULL。力扣(116)
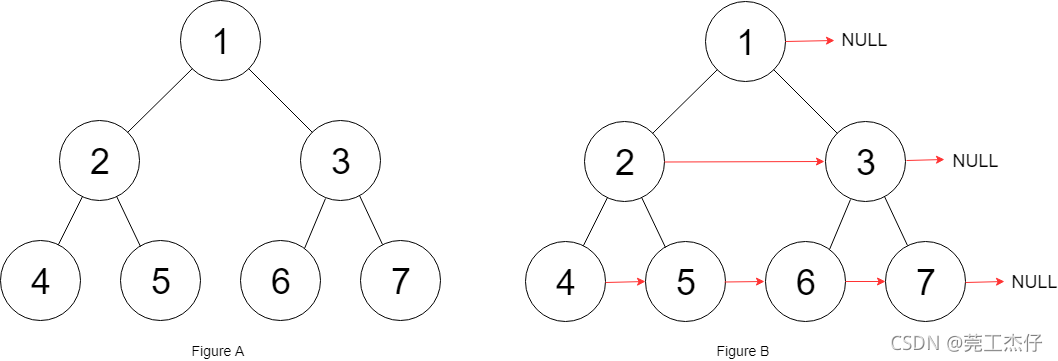
//使用广度优先遍历为同一层的元素建立连接
class Solution {
//建立一个队列进行广度优先遍历
Queue<Node> queue=new LinkedList<Node>();
public Node connect(Node root) {
//判断根节点是否为空避免出现异常
if(root==null){
return null;
}
bfs(root);
return root;
}
public void bfs(Node root) {
//将根节点入队列
queue.offer(root);
//进行深度优先搜索
while(!queue.isEmpty()){
//保存好每一层次的节点的数量
int size=queue.size();
//使用一个变量来保存前一个节点的信息,并且pre一开始作为哨兵节点
Node pre=new Node();
for(int i=0;i<size;i++){
Node temp=queue.poll();
if(temp.left!=null){
queue.offer(temp.left);
}
if(temp.right!=null){
queue.offer(temp.right);
}
//填充同一层节点之间的next
pre.next=temp;
//使用pre保存当前节点的信息,作为下一次循环的前一个节点
pre=temp;
}
//当pre为该层次的最后一个节点时,将该节点的next赋空
pre.next=null;
}
}
}
理解:其实只要你理解了广度优先遍历的话做出这道题是不难的,无非就是在遍历过程,将层次的节点不断指向同一层次的下一个节点,不过也有亮眼的操作,就是设置了一个哨兵节点,方便我们改变节点的next指向
例题5:给定一个 N 叉树,找到其最大深度。最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔(请参见示例)。
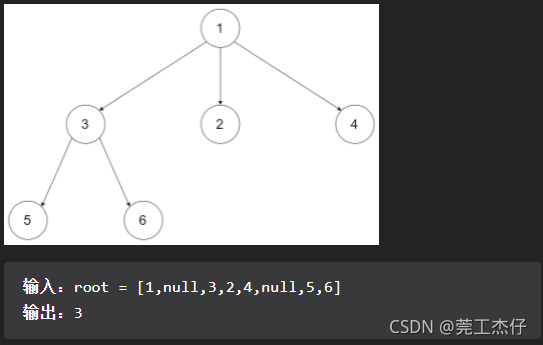
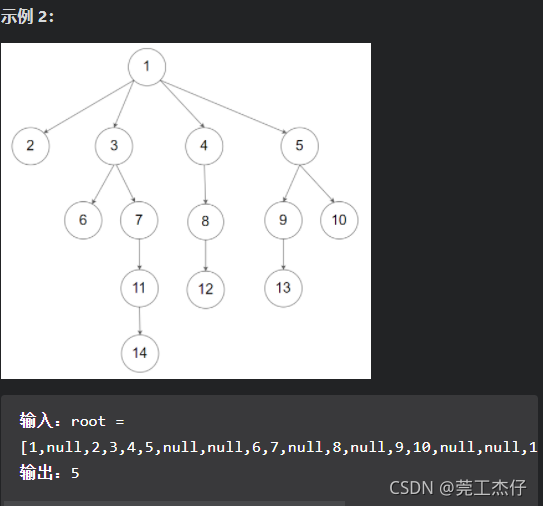
代码及细节如下:
/*
// Definition for a Node.
class Node {
public int val;
public List<Node> children;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, List<Node> _children) {
val = _val;
children = _children;
}
};
*/
//即便我可以使用层次的思想将其保存起来,但是我好像没有办法分别它是那一层
//忽然想到了可以仿照二插树的层次遍历
class Solution {
public int maxDepth(Node root) {
//创建一个变量来保存层数
int floot=0;
//避免产生异常
if(root==null){
return floot;
}
//创建一个队列来实现广度优先遍历
Queue<Node> queue =new LinkedList<Node>();
//将根节点入队列
queue.offer(root);
//进行广度优先遍历
while(!queue.isEmpty()){
//创建一个变量来保存每层元素的个数
int size=queue.size();
for(int i=0;i<size;i++){
//用一个临时的节点变量来保存出队列的元素
Node temp=queue.poll();
//将该节点的孩子节点入队列
for(int j=0;j<temp.children.size();j++){
queue.offer(temp.children.get(j));
}
}
//每完成一层的遍历,层数加一
floot++;
}
return floot;
}
}
理解:其实这道题跟二叉树的层次遍历的思路是一致的,不过就是把二叉树的左右节点入队列,改为了,使用一个循环将二叉树的说有孩子节点入队列,他的代码的重要的地方并没有改变
例题6:给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。假设二叉树中至少有一个节点。(力扣:513)
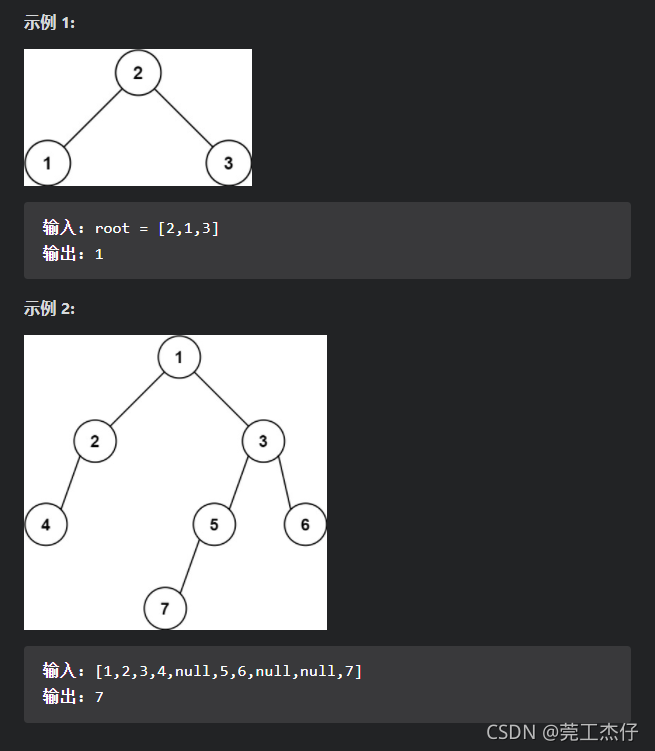
理解:看到题目的第一思路:最深是吧不就是求二叉树的深度吗?所以先求根节点左子树的深度与右子树的深度进行比较,然后再较深的那一边求出最左边的节点,最左边的节点这不简单?不就是层次遍历最后一层的第一个节点吗?思路可行,开搞
// 第一思路:求二叉树的深度+前序遍历 即dfs+bfs
class Solution {
public int findBottomLeftValue(TreeNode root) {
// 避免异常的产生
if(root.left==null&&root.right==null){
return root.val;
}
TreeNode temp;
int deep=0;
// 判断根节点左子树高还是右子树高
int l=deep(root.left);
int r=deep(root.right);
if(l>=r){
temp=root.left;
deep=l;
}
else{
temp=root.right;
deep=r;
}
//编写一个求最左边节点的函数,我想了一想好像使用广度优先遍历求解比较稳妥
// 创建一个队列来使用广度优先遍历
Queue<TreeNode> queue=new LinkedList<TreeNode>();
// 将根节点入队列
queue.offer(temp);
// 进行广度优先遍历
while(!queue.isEmpty()){
// 没进行一次层次遍历,deep减一
deep--;
// 如果deep==0说明到达了最底层,跳出循环
if(deep==0){
break;
}
int cout=queue.size();
for(int i=0;i<cout;i++){
TreeNode node=queue.poll();
// 将当前节点的左右节点入队列
if(node.left!=null){
queue.offer(node.left);
}
if(node.right!=null){
queue.offer(node.right);
}
}
}
// 跳出循环后队列中就只剩下0层的元素,此时队列中的第一个元素就为最左边元素
return queue.poll().val;
}
// 编写一个求二叉树深度的函数
public int deep(TreeNode root){
if(root==null){
return 0;
}
int lh=deep(root.left);
int rh=deep(root.right);
return Math.max(lh,rh)+1;
}
}
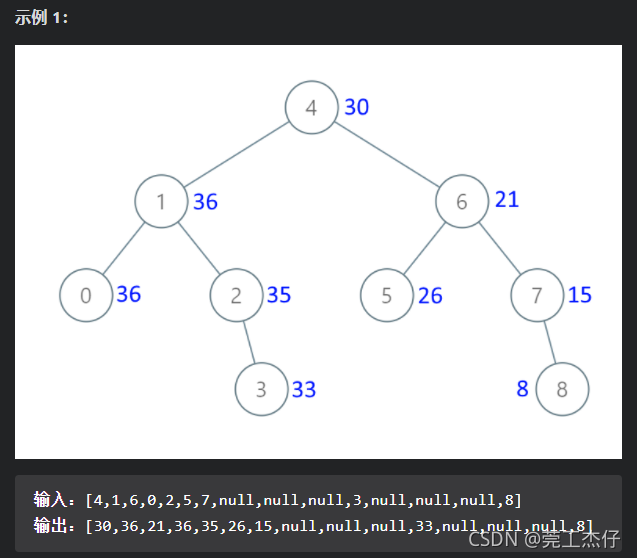
例题7 :给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。(力扣:515)
理解:我第一眼看过去广度优先遍历,老实说这种题对于目前的我实在有些简单
// 一眼看过去:广度优先遍历
class Solution {
public List<Integer> largestValues(TreeNode root) {
// 创建一个集合保存每层的最大值
List<Integer> list=new ArrayList<Integer>();
// 避免异常的产生
if(root==null){
return list;
}
// 创建一个队列进行广度优先遍历
Queue<TreeNode> queue=new LinkedList<TreeNode>();
// 将根节点入队列
queue.offer(root);
// 进行广度优先遍历
while(!queue.isEmpty()){
// 创建一个变量来保存每层的最大值
int max=Integer.MIN_VALUE;
int cout=queue.size();
for(int i=0;i<cout;i++){
TreeNode temp=queue.poll();
if(temp.val>max){
max=temp.val;
}
// 将当前节点的左右节点入队列
if(temp.left!=null){
queue.offer(temp.left);
}
if(temp.right!=null){
queue.offer(temp.right);
}
}
list.add(max);
}
return list;
}
}
例题8:给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。(力扣:538)
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。
节点的右子树仅包含键 大于 节点键的节点。
左右子树也必须是二叉搜索树。

方法1:不使用二叉搜索树的性质,直接使用两次dfs,第一次用于保存原始二叉树的值,第二次用于修改二叉树的节点的值
// 一眼看过去使用两次dfs
class Solution {
// 创建一个集合来保存,原始二叉树的数据
List<Integer> list=new ArrayList<Integer>();
public TreeNode convertBST(TreeNode root) {
dfs(root);
dfs1(root);
return root;
}
// 第一个深度优先遍历用于保存二叉树中的数据
public void dfs(TreeNode root){
if(root==null){
return ;
}
list.add(root.val);
dfs(root.left);
dfs(root.right);
}
// 第2个深度优先遍历用于修改二叉树的值
public void dfs1(TreeNode root){
if(root==null){
return ;
}
// 创建一个变量用于保存比root.val大的值的总和
int sum=0;
for(int i=0;i<list.size();i++){
int temp=list.get(i);
if(temp>=root.val){
sum=sum+temp;
}
}
root.val=sum;
dfs1(root.left);
dfs1(root.right);
}
}
方法二:使用二叉搜索树的性质,直接从二叉树的最右边进行深搜,那么在回溯过程中节点值的和就是比该节点的值大的节点值之和
// 利用二叉搜索树的性质,dfs从最右边节点开始,修改节点的值
// 这道题又帮我进一步理解了:有关递归的返回值
class Solution {
// 从最右边的节点开始,这样每次sum都为比该节点的值大的节点之和
int sum=0;
TreeNode head;
public TreeNode convertBST(TreeNode root) {
if(root==null){
return null;
}
convertBST(root.right);
sum=sum+root.val;
root.val=sum;
convertBST(root.left);
// 我管你中间过程的返回值去哪了,我只确定最后一层栈的返回值的是根节点就行了
return root;
}
}
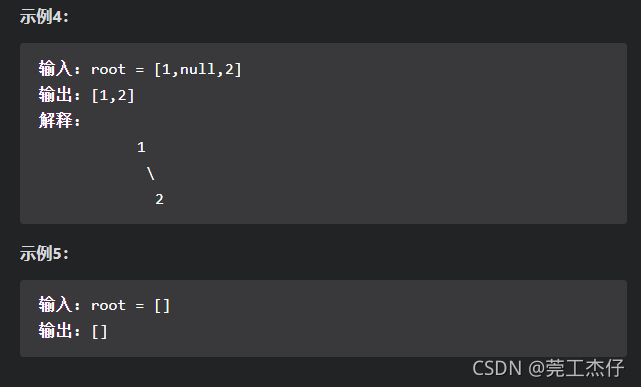
例题9:给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。(力扣:662)
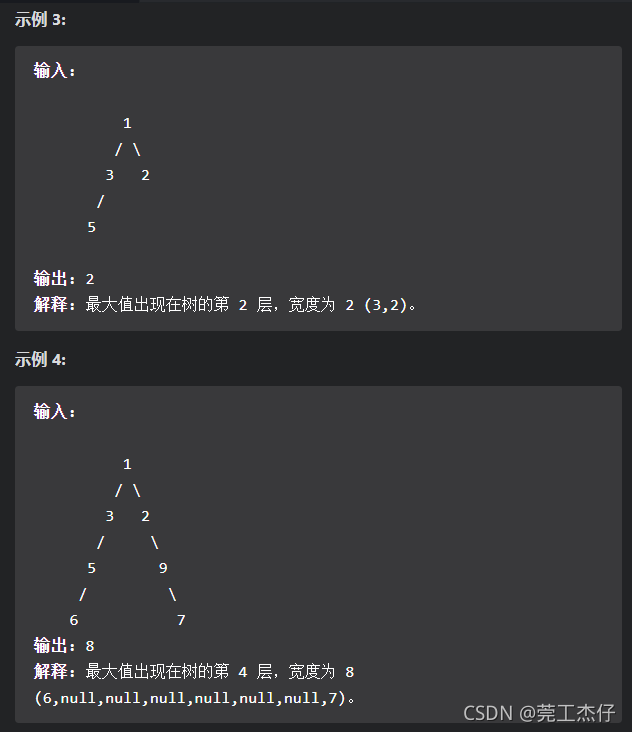
// 第一思路:广度优先遍历,思路可行,开搞
// 搞完一波发现思路好像不太行,因为它中间空的位置也要计算
// 看了看评论发现一个很吊的思路:因为每个节点原本的值是没有用处的,所以我们可以用其来保存节点的位置信息
// 所用的算法知识点(完全二叉树的性质):对于一颗完全二插树,如果按照从上至下,从左往右对所有节点从零开始顺序编号
// 则父节点的左孩子节点的序号:2*i+1 父节点的左孩子节点的序号:2*i+2;
// 所以每层的宽度就可以使用:每层最后一个节点的值减去最后一个节点的值+1
class Solution {
public int widthOfBinaryTree(TreeNode root) {
// 避免异常的产生
if(root==null){
return 0;
}
// 创建一个队列来进行广度优先遍历,注意这个地方就不要使用Queue<TreeNode> queue=new LinkedList<TreeNode>();
// 因为父类不能调用子类的方法:getLast getFirst
LinkedList<TreeNode> queue=new LinkedList<TreeNode>();
// 创建一个变量来保存最大宽度
int maxwidth=0;
// 将根节点入队列
queue.offer(root);
// 改变根结点的值
root.val=0;
while(!queue.isEmpty()){
TreeNode k=new TreeNode();
// 记录当前队列中的个数
int cout=queue.size();
//创建一个变量来计算每层的宽度
int width=queue.getLast().val-queue.getFirst().val+1;
for(int i=0;i<cout;i++){
TreeNode temp=queue.poll();
if(temp.left!=null){
queue.offer(temp.left);
temp.left.val=temp.val*2+1;
}
if(temp.right!=null){
queue.offer(temp.right);
temp.right.val=temp.val*2+2;
}
}
// 求出每一层的宽度
// 通过比较找除最大宽度
if(width>maxwidth){
maxwidth=width;
}
}
return maxwidth;
}
}
广度优先遍历在数组中的应用:
兄弟们,我们的广度优先遍历的适用范围更加的广泛了:以前的题目总是限制在树的结构里面现在,拓展到数组里面了,所以打算在这里做一个隔断以后与树相关的题目放到上面去,与数组有关的部分放在这里:
例题1:给定一个保存员工信息的数据结构,它包含了员工 唯一的 id ,重要度 和 直系下属的 id 。
比如,员工 1 是员工 2 的领导,员工 2 是员工 3 的领导。他们相应的重要度为 15 , 10 , 5 。那么员工 1 的数据结构是 [1, 15, [2]] ,员工 2的 数据结构是 [2, 10, [3]] ,员工 3 的数据结构是 [3, 5, []] 。注意虽然员工 3 也是员工 1 的一个下属,但是由于 并不是直系 下属,因此没有体现在员工 1 的数据结构中。现在输入一个公司的所有员工信息,以及单个员工 id ,返回这个员工和他所有下属的重要度之和。

理解:很典型的一道广度优先遍历题目,其实没什么好说的,细节我都放在代码注释里面:
/*
// Definition for Employee.
class Employee {
public int id;
public int importance;
public List<Integer> subordinates;
};
*/
class Solution {
public int getImportance(List<Employee> employees, int id) {
//首先我们可以先创建一个Map,将该节点的id与该节点链接起来
//因为它在集合中的位置与它的id并不对应,如果我们用map将它的id与
//他的重要性,以及直接下属联系起来
Map <Integer,Employee> map=new HashMap<Integer,Employee>();
for(Employee e:employees){
map.put(e.id,e);
}
//创建一个变量来保存所有的重要性之和
int sum=0;
//创建一个队列方便进行广度优先遍历
Queue <Integer> queue=new LinkedList();
//将所给的id入队列
queue.offer(id);
//进行广度优先遍历
while(!queue.isEmpty()){
int temp1=queue.poll();
//通过map获取id所对应的一些信息,也就是Employee
Employee temp2=map.get(temp1);
if(temp2!=null){
sum=sum+temp2.importance;
//将当前节点的所有直接下属入队列
for(Integer e: temp2.subordinates){
queue.offer(e);
}
}
}
return sum;
}
}
例题2:小朋友 A 在和 ta 的小伙伴们玩传信息游戏,游戏规则如下:
1.有 n 名玩家,所有玩家编号分别为 0 ~ n-1,其中小朋友 A 的编号为 0
每个玩家都有固定的若干个可传信息的其他玩家(也可能没有)。传信息的2.关系是单向的(比如 A 可以向 B 传信息,但 B 不能向 A 传信息)。
每轮信息必须需要传递给另一个人,且信息可重复经过同一个人
3.给定总玩家数 n,以及按 [玩家编号,对应可传递玩家编号] 关系组成的二维数组 relation。返回信息从小 A (编号 0 ) 经过 k 轮传递到编号为 n-1 的小伙伴处的方案数;若不能到达,返回 0。(力扣:173)

前言:兄弟们这可是一道大哥级别的题目,是我这近几天来认为最有意思的一道题,这题的解法有三种:1.基于邻接表的广度优先遍历 2.基于邻接矩阵的广度优先遍历 3.基于邻接矩阵的深度优先遍历,其中有关深度优先遍历的解法我放到了DFS的那篇文章那边,相信如果你理解了这道题一定会有很大的收获:
代码及细节如下:
//第三种方法:基于邻接表的广度优先遍历
//这种方法的核心思想就是,将广度遍历到第k层的节点保存到队列中,然后在队列中寻找适合的节点
class Solution {
public int numWays(int n, int[][] relation, int k) {
//创建一个邻接表
List<ArrayList<Integer>> list=new ArrayList <ArrayList<Integer>>();
//为邻接表赋予空间
for(int i=0;i<n;i++){
list.add(new ArrayList());
}
//将各个节点的关系加入邻接表
for(int j=0;j<relation.length;j++){
list.get(relation[j][0]).add(relation[j][1]);
}
//创建一个队列进行广度优先遍历
Queue<Integer> queue =new LinkedList<Integer>();
//将根节点入队列
queue.offer(0);
//广度优先遍历的具体实现
int step=0;
while(!queue.isEmpty()&&step<k){
//使用一个变量保存每层节点的个数
int size=queue.size();
for(int i=0;i<size;i++){
//将队列的头节点入队列,并将与之相联系的节点入队列
int temp=queue.poll();
for(int a:list.get(temp)){
queue.offer(a);
}
}
step++;
}
//队列中所留有的信息就是从0出发第k层所能到达的节点,找到其中等于n-1的个数就是方法的个数
int path=0;
if(step==k){
while(!queue.isEmpty()){
if(queue.poll()==n-1)
path++;
}
}
return path;
}
}
例题3:给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标。(力扣:55)
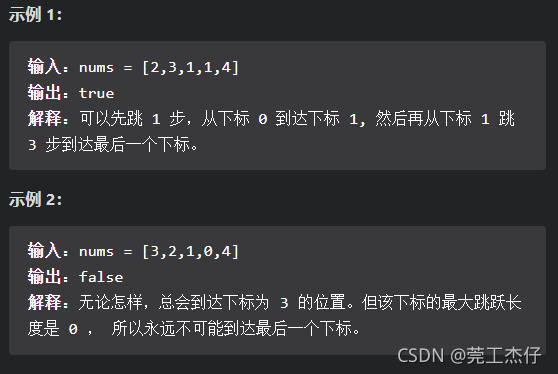
这道题是有点东西的:其实看到这道题的瞬间我就想到了楼梯问题,确实思路也可行,唯一的问题的是不断将重复的元素入队列导致时间超出了限制。而我在其中也学会了一个心得知识点就是避免将重复的元素入队列,至于怎么避免,为每个元素都加上一个visited,如果入过队列visit设置为1,具体细节在代码中
/*
算法是行的通的就是非要画蛇添足,现在优化一波算法,如果pd==true直接return
//第一眼思路:Map+广度优先遍历
class Solution {
//设计一个map将元素的下标以及所能跳跃的步数建立联系
Map<Integer,Integer> map;
//设计一个全局变量判断是否能到达最后一个位置
boolean pd=false;
public boolean canJump(int[] nums) {
map=new HashMap<Integer,Integer>();
//建立联系
for(int i=0;i<nums.length;i++){
map.put(i,nums[i]);
}
if(nums.length==0){
return true;
}
bfs(nums);
return pd;
}
public void bfs(int[] nums){
int len=nums.length-1;
//创建一个队列,方便进行广度优先遍历
Queue<Integer> queue=new LinkedList<Integer>();
//将起始位置入队列
queue.offer(0);
//将行广度优先遍历并在过程中判断是否能到达最后一个位置
while(!queue.isEmpty()){
int a=queue.poll();
if(a==len){
pd=true;
if(pd){
break;
}
}
//将当前节点所能到达的位置入队列
for(int i=1;i<=map.get(a);i++){
queue.offer(a+i);
}
}
}
}
*/
//算法是行的通的就是非要画蛇添足,导致超出时间限制,现在优化一波算法,如果pd==true直接return
/*
class Solution {
public boolean canJump(int[] nums) {
//当数组长度为1,直接返回ture
int len=nums.length-1;
if(len==0){
return true;
}
//创建一个队列,方便进行广度优先遍历
Queue<Integer> queue=new LinkedList<Integer>();
//创建一个数组为每个位置做标记
int[] visited=new int[len+1];
//将起始位置入队列
queue.offer(0);
//将行广度优先遍历并在过程中判断是否能到达最后一个位置
while(!queue.isEmpty()){
int a=queue.poll();
//设置一个变量记录当前位置所能跳跃的最大步数
int jump=nums[a];
if(a+jump>=len){
return true;
}
//将当前节点所能到达的位置入队列
for(int i=1;i<=jump;i++){
queue.offer(a+i);
}
}
return false;
}
}
*/
//优化到这个地步,还是不行,看了一下题解,发现了一个解决方法就是,将已经入过队列的位置标记,避免重复从而节省时间
class Solution {
public boolean canJump(int[] nums) {
//当数组长度为1,直接返回ture
int len=nums.length-1;
if(len==0){
return true;
}
//创建一个队列,方便进行广度优先遍历
Queue<Integer> queue=new LinkedList<Integer>();
//创建一个数组为每个位置做标记
int[] visited=new int[len+1];
//将起始位置入队列
queue.offer(0);
visited[0]=1;
//将行广度优先遍历并在过程中判断是否能到达最后一个位置
while(!queue.isEmpty()){
int a=queue.poll();
//设置一个变量记录当前位置所能跳跃的最大步数
int jump=nums[a];
if(a+jump>=len){
return true;
}
//将当前节点所能到达的位置入队列
for(int i=1;i<=jump;i++){
if(visited[a+i]!=1)
queue.offer(a+i);
//将入过队列的位置标记为1
visited[a+i]=1;
}
}
return false;
}
}
例题4:
一条基因序列由一个带有8个字符的字符串表示,其中每个字符都属于 “A”, “C”, “G”, “T"中的任意一个。
假设我们要调查一个基因序列的变化。一次基因变化意味着这个基因序列中的一个字符发生了变化。
例如,基因序列由"AACCGGTT” 变化至 “AACCGGTA” 即发生了一次基因变化。
与此同时,每一次基因变化的结果,都需要是一个合法的基因串,即该结果属于一个基因库。
现在给定3个参数 — start, end, bank,分别代表起始基因序列,目标基因序列及基因库,请找出能够使起始基因序列变化为目标基因序列所需的最少变化次数。如果无法实现目标变化,请返回 -1。
注意:
起始基因序列默认是合法的,但是它并不一定会出现在基因库中。
如果一个起始基因序列需要多次变化,那么它每一次变化之后的基因序列都必须是合法的。
假定起始基因序列与目标基因序列是不一样的。(力扣:413)
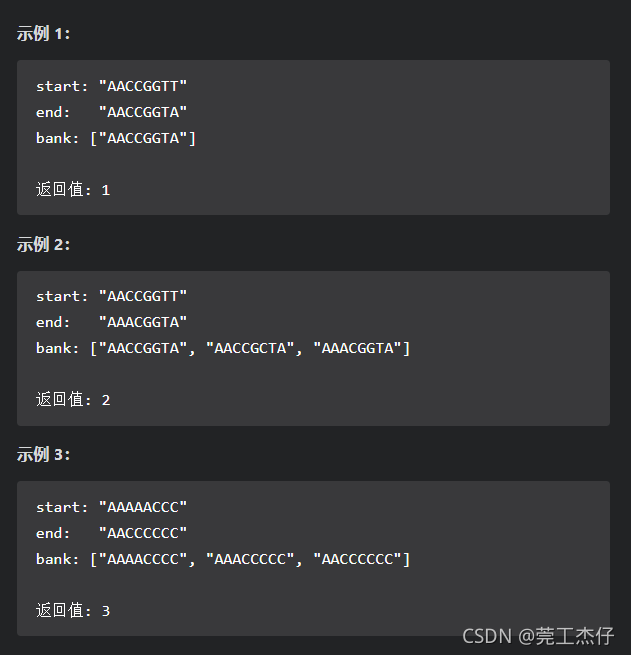
//思路:的确时广度优先遍历。看了评论区的大佬的思路才理解
//大致思路:首先就是改变字符串的每一个字母,并且判断bank中是否存在该字符串,如果存在加入第层子树
//然后再第一层子树中:重复上面的步骤,直到找到目标字符串
// 然后经历了多少层的层次遍历就是需要转换的次数
class Solution {
public int minMutation(String start, String end, String[] bank) {
// 首先将bank中的所有字符串加入集合中,其实我感觉list,set都是可以的但还是使用set算了,避免有重复的字符串
Set<String> set=new HashSet<String>();
// 创建一个集合保存遍历过的字符串,防止重复进入队列,超出时间限制
Set<String> set1=new HashSet<String>();
// 将bank中的字符串加入到set中
for(String s:bank){
set.add(s);
}
// 创建一个数组记录A C G T
char[] gen={'A','C','G','T'};
// 判断bank中是否含有end如果没有直接返回-1
if(!set.contains(end)){
return -1;
}
// 创建一个队列来进行广度优先遍历
Queue<String> queue =new LinkedList<String>();
// 将起始字符串入队列
queue.offer(start);
// 设置一个变量来记录广度优先遍历的层数
int size=0;
// 进行广度优先遍历
while(!queue.isEmpty()){
int cout=queue.size();
size++;
// 按层数将队列中的元素依次遍历
for(int i=0;i<cout;i++){
String temp=queue.poll();
// 将temp转化为数组方便改变其中的字母
char[] temp1=temp.toCharArray();
// 将temp中的每个元素依次改变
for(int j=0;j<temp.length();j++){
// 保存当前位置的字母,方便一会复原
char c=temp1[j];
// 依次使用每个基因代替该节点
for(int k=0;k<4;k++){
temp1[j]=gen[k];
String temp2=new String(temp1);
// 如果找到目标字符串直接返回size
if(temp2.equals(end)){
return size;
}
if(set.contains(temp2)&&!set1.contains(temp2)){
queue.offer(temp2);
}
// 将入过队列的字符串记录下来,防止重复入队列
set1.add(temp2);
}
// 将数组复原
temp1[j]=c;
}
}
}
return -1;
}
}
例题5:字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
1.序列中第一个单词是 beginWord 。
2.序列中最后一个单词是 endWord 。
3.每次转换只能改变一个字母。
4.转换过程中的中间单词必须是字典 wordList 中的单词。
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。(力扣:127)

//屠虫少年终将屠龙,第一次单挑困难题
//大致思路:BFS+HashSet,细节在代码中
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 首先如果wordList中不存在endwork直接返回
if(!wordList.contains(endWord)){
return 0;
}
// 去除重复的字符串
HashSet<String> set=new HashSet<String>(wordList);
// 创建一个队列来进行广度优先遍历
Queue<String> queue=new LinkedList<String>();
// 将起始字符串入队列
queue.offer(beginWord);
// 创建一个变量记录转换的次数
int size=1;
// 创建一个数组记录wordList中出现过的字母方便下文对字符串的转换
// char[] ch={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
HashSet<Character> set1=new HashSet<Character>();
for(String s:set){
for(int j=0;j<s.length();j++){
set1.add(s.charAt(j));
}
}
char[] ch=new char[set1.size()];
int m=0;
// 将set1中的字母放进数组中去
for(char c:set1){
ch[m]=c;
m++;
}
// 进行广度优先遍历
while(!queue.isEmpty()){
size++;
// 记录当前层次的队列的元素个数,依次进行遍历
int cout=queue.size();
for(int i=0;i<cout;i++){
String temp=queue.poll();
// 将temp转换为数组方便下面对字符串中字母的替换
char[] arr=temp.toCharArray();
// 对字符串中的每个字母进行遍历
for(int j=0;j<temp.length();j++){
// 每次替换前先记录下该字母方便复原
char fy=arr[j];
// 对每个字母都进行替换
for(int k=0;k<ch.length;k++){
arr[j]=ch[k];
// 将替换后的数组再次转换为字符串
String str=new String(arr);
// 判断是否出现了目标字符串
if(str.equals(endWord)){
return size;
}
if(set.contains(str)){
queue.offer(str);
// 将遍历过的字符串去除,避免重复入队列浪费时间
set.remove(str);
}
}
// 将数组复原
arr[j]=fy;
}
}
}
return 0;
}
}
例题6:存在一个 无向图 ,图中有 n 个节点。其中每个节点都有一个介于 0 到 n - 1 之间的唯一编号。给你一个二维数组 graph ,其中 graph[u] 是一个节点数组,由节点 u 的邻接节点组成。形式上,对于 graph[u] 中的每个 v ,都存在一条位于节点 u 和节点 v 之间的无向边。该无向图同时具有以下属性:
不存在自环(graph[u] 不包含 u)。
不存在平行边(graph[u] 不包含重复值)。
如果 v 在 graph[u] 内,那么 u 也应该在 graph[v] 内(该图是无向图)
这个图可能不是连通图,也就是说两个节点 u 和 v 之间可能不存在一条连通彼此的路径。
二分图 定义:如果能将一个图的节点集合分割成两个独立的子集 A 和 B ,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B 集合,就将这个图称为 二分图 。
如果图是二分图,返回 true ;否则,返回 false 。(力扣:785)
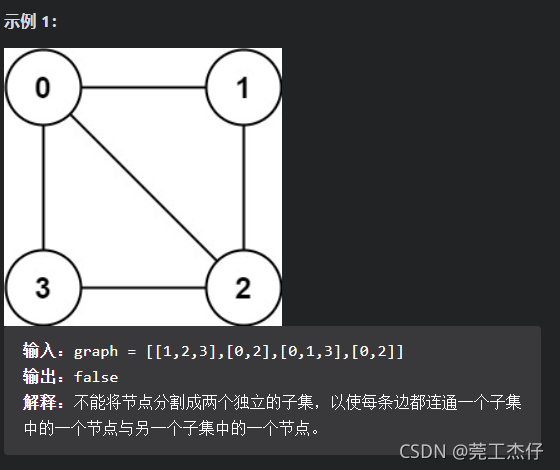
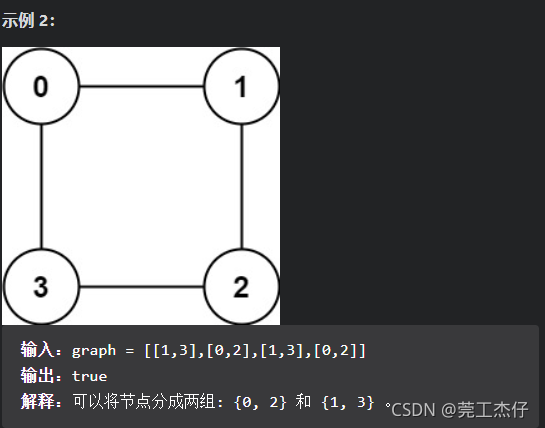
// 看了看题解的得出了一个大致的思路:将图中的节点进行染色,大致思路是这样的,假设存在边u-v
// 我们可以将u记录为红色,那么v就可以杯记录为绿色,假设此时又有一条边v-k,
// k节点可能又两种情况:1.没有被访问过,也就是没有被染色,那么我们就可以将其染成与v相反的颜色
// 2:如果已经被访问过了,那它肯定就会又颜色,如果是与v相反的颜色说明没问题,如果是与v相同的颜色
// 就说明这个图肯定不是二分图了那么直接返回false
// 首先我们先使用广度优先遍历来做一下吧:
// 在第一次提交就出现了一个问题,那就是该图可能不是连通图
// 怎末解决吧:我思考了一下进行多次广度优先遍历,对color进行遍历找到没有被染色的节点,然后对这些节点进行广搜
class Solution {
int[] color;
public boolean isBipartite(int[][] graph) {
// 创建一个数组来保存当前节点的颜色的信息,我们可以使用1来代表一种颜色,-1来代表另一种颜色,0代表没有染色
this.color=new int[graph.length];
// 创建一个boolean变量来保存结果
boolean pd=true;
for(int i=0;i<graph.length;i++){
// 如果存在某节点没有被染色,就以该节点为起点进行一次广度优先遍历
if(color[i]==0){
pd=pd&&bfs(graph,i);
}
}
return pd;
}
public boolean bfs(int[][] graph,int start){
// 首先创建一个队列来进行广度优先遍历
Queue<Integer> queue=new LinkedList<Integer>();
// 以start为起点入队列吧
queue.add(start);
// 在入队列的同时为该节点染色
color[start]=1;
// 进行广搜
while(!queue.isEmpty()){
// 记录先目前层次中元素的个数
int cout=queue.size();
for(int i=0;i<cout;i++){
// 将当前层次中的节点依次出队列
int temp=queue.poll();
// 将与当前节点有联系的节点都入队列
for(int j:graph[temp]){
// 在将该节点入队列之前先将该节点进行一下判断
// 首先如果当前节点没有被染色那么我们就将它的颜色染成与当前节点染色相反的染色然后返回
if(color[j]==0){
color[j]=0-color[temp];
queue.add(j);
continue;
}
else{
// 如果颜色相等,那肯定就不是2分图了,直接返回
if(color[j]==color[temp]){
return false;
}
// 如果颜色不相等,我们就不鸟它,因为有颜色就说明它已经入过队列
// 如果在将它入队列可能会造成死循环
}
}
}
}
// 如果在整个深搜过程中都没有问题,就说明这个图为2分图
return true;
}
}
例题7: n 张多米诺骨牌排成一行,将每张多米诺骨牌垂直竖立。在开始时,同时把一些多米诺骨牌向左或向右推。
每过一秒,倒向左边的多米诺骨牌会推动其左侧相邻的多米诺骨牌。同样地,倒向右边的多米诺骨牌也会推动竖立在其右侧的相邻多米诺骨牌。
如果一张垂直竖立的多米诺骨牌的两侧同时有多米诺骨牌倒下时,由于受力平衡, 该骨牌仍然保持不变。
就这个问题而言,我们会认为一张正在倒下的多米诺骨牌不会对其它正在倒下或已经倒下的多米诺骨牌施加额外的力。
给你一个字符串 dominoes 表示这一行多米诺骨牌的初始状态,其中:
dominoes[i] = ‘L’,表示第 i 张多米诺骨牌被推向左侧,
dominoes[i] = ‘R’,表示第 i 张多米诺骨牌被推向右侧,
dominoes[i] = ‘.’,表示没有推动第 i 张多米诺骨牌。
返回表示最终状态的字符串。(leetcode 838)

/*
// 做这道题时首先要明确几点:1:骨牌的倾斜式随着时间进行的,时间间隔为1秒,这也是为什么可以使用广度优先遍历的原因
2:每张骨牌最多同时收到:一左一右的力,因为已经倒下的骨牌不受其他骨牌的影响
如果这种情况骨牌会中立
具体的解决思路:使用广度优先遍历解题,使用一个队列按时间层次对骨牌的状态进行处理,使用time数组记录骨牌骨牌所在的时间层次,
因为倒下的骨牌不会收到其他骨牌的影响,使用一个集合记录每一个骨牌的受力情况,从而判断它是否会倒下
*/
class Solution {
public String pushDominoes(String dominoes) {
int n = dominoes.length();
// 创建一个队列按照每个骨牌的倒下时间顺序进行进出队列
// 这是一个新的语法,我之前都是用Queue<> queue=new LinkedList<>();
Deque<Integer> queue = new ArrayDeque<Integer>();
// 记录骨牌倒下的时间,避免本不能对其造成影响的骨牌对齐造成影响,只有在其之前一个层次的
// 力能影响它
int[] time = new int[n];
// 初始化time数组,因为time[i]=0意味着初始化被施加力量的骨牌
Arrays.fill(time, -1);
// 这里的语法围殴也没怎么使用过,居然还有集合类型的数组,这样就更加方便了
// 我之前都是使用集合的嵌套完成的散列表
List<Character>[] force = new List[n];
// 为列表赋予空间
for (int i = 0; i < n; i++) {
force[i] = new ArrayList<Character>();
}
// 将初始化时被施加力量的骨牌加入队列
for (int i = 0; i < n; i++) {
char f = dominoes.charAt(i);
if (f != '.') {
queue.offer(i);
time[i] = 0;
force[i].add(f);
}
}
// 创建一个数组来记录遍历之后的骨牌的状态,骨牌的初始化都是中立的
char[] res = new char[n];
Arrays.fill(res, '.');
// 进行广度优先遍历
while (!queue.isEmpty()) {
int i = queue.poll();
// 这里跟之前一些遍历题不一样的地方就在于它没有使用for循环进行,层次的划分,
// 不过好像也没有必要,因为到题中已经有了一个time数组来记录循环
// 如果该过牌只受到一个力,哪它一定会倒下
if (force[i].size() == 1) {
char f = force[i].get(0);
// 根据所受到的力改变骨牌的状态
res[i] = f;
int ni = f == 'L' ? i - 1 : i + 1;
// 判断受他影响的骨牌是否在数组范围内
if (ni >= 0 && ni < n) {
int t = time[i];
// 如果时还没受过印象的骨牌记录,它的时间层次,并未其添加一个力
if (time[ni] == -1) {
queue.offer(ni);
time[ni] = t + 1;
force[ni].add(f);
}
// 这个地方也很关键,只有前一秒的骨牌能影响现在的骨牌
else if (time[ni] == t + 1) {
force[ni].add(f);
}
}
}
}
return new String(res);
}
}
例题8: 2039. 网络空闲的时刻



// 其实由数学规律不难知道花费的时间:为最后一个数据宝开始发送的时间+发送完一个完整数据包所需的时间
// 最后一个包的发送时间:
// 首先是发送了多少个包:第一个包往返路程的时间-1(因为最后一秒已经回到了)/该节点的等待时间
// 最后一个包开始发送的时间=发送的包的数量*等待时间
// 所以这道题只是看着吓人实际上简单的很
class Solution {
public int networkBecomesIdle(int[][] edges, int[] patience) {
// 记录服务器的数量
int len=patience.length;
// 创建一个邻接表
List<Integer>[] arr=new List[len];
// 创建一个数组记录访问过的服务器避免进入死循环
int[] visited=new int[len];
// 为邻接表赋予空间
for(int i=0;i<len;i++){
arr[i]=new ArrayList<Integer>();
}
// 根据所给的图建立邻接表
for(int i=0;i<edges.length;i++){
arr[edges[i][0]].add(edges[i][1]);
arr[edges[i][1]].add(edges[i][0]);
}
// 创建一个变量记录搜索的层数
int index=0;
// 创建一个数组记录受到信息所花费的时间
int[] time=new int[len];
// 建立好邻接表后开始进行广度优先遍历,并在遍历的过程中,记录符服务器受到信息所花费的时间
Deque<Integer> queue=new LinkedList<>();
queue.offer(0);
while(!queue.isEmpty()){
// 记录当前队列中元素的数量
int count=queue.size();
for(int i=0;i<count;i++){
// 将该层次的节点出队列
int a=queue.poll();
// 如果当前节点已经访问过直接跳过
if(visited[a]==1){
continue;
}
// 标记访问过的节点
visited[a]=1;
// 记录到达当前节点所需要的时间,因为index只是一般的时间所以*2
time[a]=index*2;
// 将当前的队列中的节点出队列
List<Integer> temp=arr[a];
// 将与当前节点相邻的节点都入队列
for(int b:temp){
queue.add(b);
}
}
index++;
}
// 根据受到第一个包是时间,来计算最后该线路的安静时间,即接受到最后一个包的使劲按
int max=0;
// 注意下标从1开始
for(int i=1;i<len;i++){
if(time[i]<patience[i]){
max=Math.max(max,time[i]);
}else{
int temp=(time[i]-1)/patience[i]*patience[i]+time[i];
max=Math.max(max,temp);
}
}
return max+1;
}
}
last