导数(Derivative)是微积分学(微积分学是研究极限、微分学、积分学和无穷级数等的一个数学分支)中重要的基础概念。一个函数在某一点的导数描述了这个函数在这一点附件的变化率。导数的本质是通过极限的概念对函数进行局部的线性逼近。当函数f的自变量在一点x0上产生一个增量h时,函数输出值的增量与自变量增量h的比值在h趋于0时的极限如果存在,即为f在x0处的导数,记作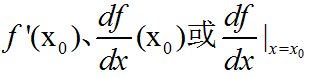
导数是函数的局部性质。不是所有的函数都有导数,一个函数也不一定在所有点上都有导数。若某函数在某一点导数存在,则称其在这一点可导,否则称为不可导。如果函数的自变量和取值都是实数的话,那么函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率(斜率用来量度斜坡的斜度,数学上,直线的斜率在任一处皆相等,是直线倾斜程度的量度。透过代数和几何能计算出直线的斜率;曲线上某点的切线斜率反映此曲线的变数在此点的变化快慢程度,用微积分可计算出曲线中任一点的切线斜率)。
对于可导的函数f,x→f’(x)也是一个函数,称作f的导函数。寻找已知的函数在某点的导数或其导函数的过程称为求导。反之,已知导函数也可以倒过来求原来的函数,即不定积分(在微积分中,一个函数f的不定积分,也称为原函数或反导数,是一个导数等于f的函数F,即F’=f。不定积分和定积分间的关系由微积分基本定理确定)。微积分基本定理说明了求原函数与积分是等价的。求导和积分是一对互逆的操作,它们都是微积分学中最为基础的概念。
一般定义:设有定义域和取值都在实数域中的函数y=f(x)。若f(x)在点x0的某个领域内有定义,则当自变量x在x0处取得增量Δx(点x0+Δx仍在该邻域内)时,相应地y取得增量Δy=f(x0+Δx)-f(x0);如果Δy与Δx之比当Δx→0时的极限存在,则称函数y=f(x)在点x0处可导,并称这个极限为函数y=f(x)在点x0处的导数,记为f’(x0),即:
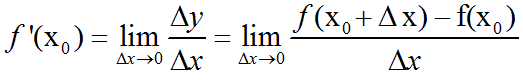
对于一般的函数,如果不使用增量的概念,函数f(x)在点x0处的导数也可以定义为:当定义域内的变量x趋近于x0时,f(x)-f(x0)/(x-x0)的极限,也就是说:
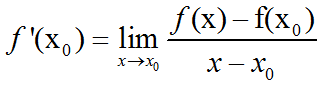
几何意义:当函数定义域和取值都在实数域中的时候,导数可以表示函数的曲线上的切线斜率。
导函数:若函数f(x)在其定义域包含的某区间I内每一个点都可导,那么也可以说函数f(x)在区间I内可导,这时对于I内每一个确定的x值,都对应着f的一个确定的导数值,如此一来就构成了一个新的函数x→f’(x),这个函数称作原来函数f(x)的导函数,记作:y’、f’(x)或者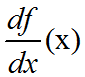 。值得注意的是,导数是一个数,是指函数f(x)在点x0处导函数的函数值。但在不至于混淆的情况系,通常也可以说导函数为导数。由于对每一个可导的函数f(x),都有它的导函数f’(x)存在,我们还可以定义将函数映射到其导函数的算子。这个算子称为微分算子。
。值得注意的是,导数是一个数,是指函数f(x)在点x0处导函数的函数值。但在不至于混淆的情况系,通常也可以说导函数为导数。由于对每一个可导的函数f(x),都有它的导函数f’(x)存在,我们还可以定义将函数映射到其导函数的算子。这个算子称为微分算子。
导数与微分:微分也是一种线性描述函数在一点附近变化的方式。微分和导数是两个不同的概念。但是,对一元函数来说,可微与可导是完全等价的。可微的函数,其微分等于导数乘以自变量的微分dx,换句话说,换句话说,函数的微分与自变量的微分之商等于该函数的导数。因此,导数也叫做微商。函数y=f(x)的微分又可记作dy=f’(x)dx。
函数可导的条件:如果一个函数在定义域为全体实数,即函数在(-∞,+∞)上都有定义,那么该函数是不是在定义域上处处可导呢?答案是否定的。函数在定义域中一点可导需要一定的条件。首先,要使函数f在一点可导,那么函数一定要在这一点处连续。换言之,函数若在某点可导,则必然在该点处连续。然而,连续性并不能保证可导性。即使函数在一点上连续,也不一定就在这一点可导。事实上,存在着在每一点都连续,但又在每一点都不可导的”病态函数”。在连续而不可导的函数里,一种常见的情况是,函数在某一点连续,并且可以定义它的左导数和右导数,然而左导数和右导数并不相等,因而函数在该处不可导。实际上,若函数导数存在,则必然可以推出左右导数相等,这是由极限的性质(极限存在则左右极限相等)得来。如果函数在一点的左右导数都存在并且相等,那么函数在该处可导。
导数与函数的性质:
(1)、单调性:如果函数的导函数在某一区间内恒大于零(或恒小于零),那么函数在这一区间内单调递增(或单调递减),这种区间也称为函数的单调区间。导函数等于零的点称为函数的驻点(或极值可疑点),在这类点上的函数可能会取得极大值或极小值。
(2)、凹凸性:可导函数的凹凸性与其导数的单调性有关。如果函数的导函数在某个区间上单调递增,那么这个区间上的函数是向下凸的,反之则是向上凸的。
基本函数的导数:
(1)、多项式函数:如果f(x)=xr,其中r是非零实数,那么导函数f’(x)=rxr-1。函数f的定义域可以是整个实数域,但导函数的定义域则不一定与之相同。
(2)、常函数的导数是0。
(3)、底数为e的指数函数y=ex的导数还是自身。一般的指数函数y=ax的导数还需要乘以一个系数即为ln(a)ax。自然对数函数ln(x)的导数是x-1.同样的,一般的对数函数loga(x)导数则还需要乘以一个系数即为1/(xln(a))。
(4)、三角函数的导数仍然是三角函数,或者由三角函数构成:
f’(sin(x))=cos(x) f’(tan(x))= sec2(x)=1/(cos2(x))
f’(cos(x))=-sin(x) f’(cot(s))=-csc2(x)=-1/(sin2(x))
(5)、反三角函数的导数则是无理分式:
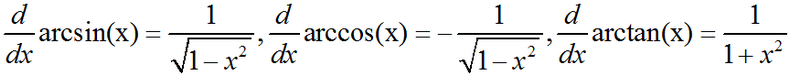
导数的求导法则:由基本函数的和、差、积、商或相互复合构成的函数的导函数则可以通过函数的求导法则来推导。基本的求导法则如下:
(1)、求导的线性性:对函数的线性组合求导,等于先对其中每个部分求导后再取线性组合:(af+bg)’=af’+bg’(其中a,b为常数);
(2)、两个函数的乘积的导函数,等于其中一个的导函数乘以另一者,加上另一者的导函数与其的乘积:(fg)’=f’g+fg’
(3)、两个函数的商的导函数也是一个分式,其中分子是分子函数的导函数乘以分母函数减去分母函数的导函数乘以分子函数后的差,而其分母是分母函数的平方:(在g(x)≠0处方有意义)
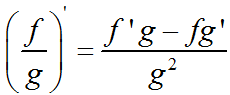
(4)、复合函数的求导法则:如果有复合函数f(x)=h[g(x)],那么f’(x)=h’[g(x)]·g’(x)
若要求某个函数在某一点的导数,可以先运用以上方法求出这个函数的导函数,再看导函数在这一点的值。
二阶导数:如果函数的导数f’(x)在x处可导,则称[f’(x)]’为x的二阶导数,记做: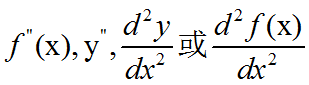
函数在定义域中一点可导需要一定的条件是:函数在该点的左右两侧导数都存在且相等。连续的函数不一定处处可导。但处处可导的函数一定处处连续。
以上内容摘自:维基百科
之前在 http://blog.csdn.net/fengbingchun/article/details/73848734 和 http://blog.csdn.net/fengbingchun/article/details/73872828 中介绍过激活函数sigmoid、ReLU、Leaky ReLU、ELU、softplus,这里分别对它们进行求导:
sigmoid:
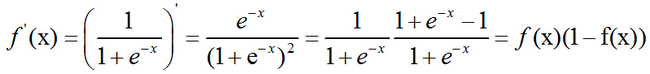
ReLU:
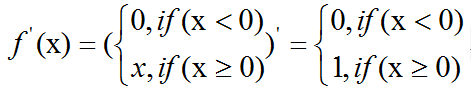
Leaky ReLU:
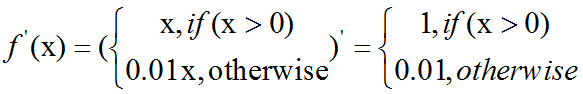
ELU:
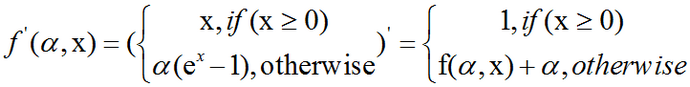
对ELU求导数好像有些复杂,在Caffe和tiny-dnn中求法好像也不一致,公式中是 维基百科 中给出的求法。
softplus:
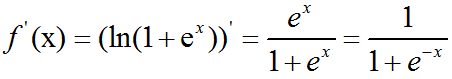
根据以上公式实现的C++代码:
#include "funset.hpp"
#include <math.h>
#include <iostream>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
#include "common.hpp"
#define EXP 1.0e-5
namespace fbc {
// ========================= Activation Function: ELUs ========================
template<typename _Tp>
int activation_function_ELUs(const _Tp* src, _Tp* dst, int length, _Tp a = 1.)
{
if (a < 0) {
fprintf(stderr, "a is a hyper-parameter to be tuned and a>=0 is a constraint\n");
return -1;
}
for (int i = 0; i < length; ++i) {
dst[i] = src[i] >= (_Tp)0. ? src[i] : (a * (exp(src[i]) - (_Tp)1.));
}
return 0;
}
template<typename _Tp>
int activation_function_ELUs_derivative()
{
// to do
}
// ========================= Activation Function: Leaky_ReLUs =================
template<typename _Tp>
int activation_function_Leaky_ReLUs(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = src[i] > (_Tp)0. ? src[i] : (_Tp)0.01 * src[i];
}
return 0;
}
template<typename _Tp>
int activation_function_Leaky_ReLUs_derivative(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = src[i] > (_Tp)0. ? (_Tp)1 : (_Tp)0.01;
}
return 0;
}
// ========================= Activation Function: ReLU =======================
template<typename _Tp>
int activation_function_ReLU(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = std::max((_Tp)0., src[i]);
}
return 0;
}
template<typename _Tp>
int activation_function_ReLU_derivative(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = src[i] < (_Tp)0 ? (_Tp)0 : (_Tp)1;
}
return 0;
}
// ========================= Activation Function: softplus ===================
template<typename _Tp>
int activation_function_softplus(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = log((_Tp)1. + exp(src[i])); // log1p(exp(src[i]))
}
return 0;
}
template<typename _Tp>
int activation_function_softplus_derivative(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = (_Tp)(1. / (1. + exp(-src[i])));
}
return 0;
}
// ============================ Activation Function: sigmoid ================
template<typename _Tp>
int activation_function_sigmoid(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = (_Tp)(1. / (1. + exp(-src[i])));
}
return 0;
}
template<typename _Tp>
int activation_function_sigmoid_derivative(const _Tp* src, _Tp* dst, int length)
{
for (int i = 0; i < length; ++i) {
dst[i] = (_Tp)(exp(-src[i]) / pow((1+exp(-src[i])), 2.f));
}
return 0;
}
int test_activation_function()
{
std::vector<double> src{ 1.23f, 4.14f, -3.23f, -1.23f, 5.21f, 0.234f, -0.78f, 6.23f };
int length = src.size();
std::vector<double> dst(length);
fprintf(stderr, "source vector: \n");
fbc::print_matrix(src);
fprintf(stderr, "calculate activation function:\n");
fprintf(stderr, "type: sigmoid result: \n");
fbc::activation_function_sigmoid(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: sigmoid derivative result: \n");
fbc::activation_function_sigmoid_derivative(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: sigmoid fast result: \n");
fbc::activation_function_sigmoid_fast(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: softplus result: \n");
fbc::activation_function_softplus(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: softplus derivative result: \n");
fbc::activation_function_softplus_derivative(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: ReLU result: \n");
fbc::activation_function_ReLU(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: ReLU derivative result: \n");
fbc::activation_function_ReLU_derivative(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: Leaky ReLUs result: \n");
fbc::activation_function_Leaky_ReLUs(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: Leaky ReLUs derivative result: \n");
fbc::activation_function_Leaky_ReLUs_derivative(src.data(), dst.data(), length);
fbc::print_matrix(dst);
fprintf(stderr, "type: Leaky ELUs result: \n");
fbc::activation_function_ELUs(src.data(), dst.data(), length);
fbc::print_matrix(dst);
return 0;
}
GitHub:https://github.com/fengbingchun/NN_Test