摘要
目标检测是计算机视觉的一个重要分支,其目的是准确判断图像或视频中的物体类别并定位。传统的目标检测方法包括这三个步骤:区域选择、提取特征和分类回归,这样的检测方法存在很多问题,现已难以满足检测对性能和速度的要求。基于深度学习的目标检测方法摒弃了传统检测算法适应性不高、对背景模型的更新要求高、提取特征鲁棒性差和检测的实时性差等缺点,使检测模型在精度和速度方面都有了很大的提升。
目前,基于深度学习的目标检测方法主要分为两大类:一是基于Region Proposal的 two stage目标检测算法,二是基于回归问题的one stage目标检测算法。第一类是先由特定算法生成一系列样本的候选框,再通过卷积神经网络对样本进行分类,最后还要进行边界框的位置精修,代表作主要有R-CNN[1-4]等一系列的检测算法;第二类则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理,直接对预测的目标物体进行回归,经典的算法有SSD[5]和YOLO[6-8]系列等;还有一类方法是新提出的对one stage和two stage方法进行改进,得到的其升级版的方法,比如Faster R-CNN[4]、YOLO[6-8]、SSD[5] 等经典论文的升级版本,包括Cascade R-CNN[12],DSSD[29]等算法,但根据网络结构,它们同样可以归到前两类中。正是由于one stage和two stage两种方法的差异,其在性能上也有不同,前者在检测准确率和定位精度上占优,而后者在检测速度上更具有优势。到现在,目标检测算法仍在进一步更新和演化,许多新的更有效的算法也在不断问世。
1引言
目标检测是为了从图像或视频中识别和定位出我们需要的目标物体,是后续图像理解和应用的基础任务。检测器性能的好坏将直接影响后续的目标跟踪、动作识别以及行为理解等中高层任务的性能。传统的目标检测算法的发展早在2010年就停滞不前,直到2013年将卷积网络引入到目标检测中,才突破了传统检测瓶颈,掀起了深度学习目标检测的热潮。从此以后,基于深度学习的目标检测快速发展。
基于深度学习的目标检测方法,是计算机视觉检测领域的一个重大创新。这
些创新算法都是把传统的计算机视觉领域和深度学习合二为一,并取得了良好的检测效果。准确性和实时性是衡量目标检测系统性能的重要指标,也是一对矛盾体,如何更好地平衡它们一直是目标检测算法研究的一个重要方向。随着深度学习的不断发展,检测的精度和实效性也逐渐提升。因此,基于深度学习的目标检测算法得到了广大研究者的关注,一跃成为机器学习领域的热点话题之一。
目标检测的难点在于:目标形态各异、大小不一,图像的任意位置都可能含有目标,在军事和航空领域,对于弱小目标和模糊目标的检测也是一个难点。目标检测使用矩形框来定位目标,由于目标物体的形态和大小的差异,导致矩形框也具有不同的宽高比,此时,若采用早期的滑动窗口与图像缩放相结合的方法,检测成本会很高,同时检测效率也极低。
2013年Girshick等人提出了R-CNN[1]检测算法,在基于深度学习的目标检测领域取得了重大突破,借助卷积神经网络良好的特征提取和分类性能,并通过Region Proposal方法实现目标检测问题的转化,为后来的深度学习目标检测方法奠定了基础,但此方法容易导致图像信息丢失,资源浪费[1]。2016年,R-CNN系列的最高代表作Faster R-CNN[4]实现了端到端的检测,检测精度可以说是达到了最优,但在检测速度仍有很大的改进空间[4]。这种two-stage的检测器可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有得到质的提升。同年,出现了YOLO和SSD等更快速的检测算法,将目标检测转化为回归问题,真正实现了端到端的实时检测,但精度不如Faster R-CNN高。后来,2017和2018年,作者又在YOLO的基础上进行改进,形成了第二版和第三版的YOLO,YOLOv3可以达到惊人的检测效果。同时,也出现了更多高性能的检测算法,例如Refine-Det[9] 、Relation Net[10]和RFB-Net[11]等,都取得了更好的检测效果。近两年新提出的检测算法有很多都是在先前的算法上进行改进得到的,同样取得了不错的检测效果。
今年CVPR上关于目标检测的论文数量较往年增加了许多,说明这一研究领域的热度不减反增,目标检测算法正在急速发展。本文在第二章和第三章介绍了2013年至今基于深度学习的目标检测方法的发展历程以及几种经典的检测算法,详细描述了各算法的重要思想和创新点,并指出了其缺陷以及在以后出现的算法中关于此问题的改进思路。
2 基于Region Proposal的 two stage检测算法
2.1 R-CNN
R-CNN算法是Region Proposal + CNN这一框架的开山之作,为以后基于CNN的检测算法奠定了基础。该算法首先采用Selective Search算法,对一张多目标图像进行分割和聚类,得到大量的目标候选框,然后将候选框裁剪、放缩至统一尺寸,再使用卷积网络对候选框进行特征提取,提取到的CNN特征输入到每一类的SVM进行分类,判别是否属于该类,最后还要进行边界框的回归,即用线性回归微调边界框的位置和大小[1]。R-CNN的主要缺点是重复计算,需要对每个候选框都进行特征提取,因此计算量很大,时间消耗多。而且,全连接层需要保证输入的候选框大小统一,所以网络输入的一系列图片需要裁剪和放缩至统一尺寸,这样可能导致图像畸变,影响检测效果,下面的SPP-net[2]算法为这些问题提供了解决思路。
2.2 SPP-net
为了解决R-CNN中对候选框进行裁剪、缩放从而影响检测效果的问题,何凯明提出了SPP-Net,即不进行裁剪、缩放,并且在R-CNN最后一个卷积层后,接入了金字塔池化层( spatial Pyramid Pooling, SPP),使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出[2]。还有一点,SPP-Net是把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框对应的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量,所以,检测速度也会大大提升。
2.3 Fast R-CNN
首先,该算法借鉴了SPP-net中金字塔池化的思想,对每个候选框所对应的feature map经过一个ROI pooling layer 形成一个固定长度的feature map,可以说是属于简化版的金字塔池化(SPP)。其次,采用了多任务训练的模式,将回归也加入到网络中,使分类和回归同时进行训练,减少硬件缓存,并且用soft-max替代SVM进行分类[3]。但该算法仍然使用Selective Search方法进行候选框的提取,复杂耗时。
2.4 Faster R-CNN
Faster R-CNN可以简单地看作“区域生成网络RPNs + Fast R-CNN”的系统,该算法最大的创新就是提出了“区域生成网络(RPN)”,用其代替Fast R-CNN中的Selective Search方法进行候选框提取[4]。RPN的核心思想是使用卷积神经网络直接产生Region Proposal,本质就是滑动窗口。其次,使用四步交替训练法进行RPN和Fast R-CNN的训练,RPN与Fast-R-CNN共享卷积层,使提取候选框的成本降为零。
2.5 Cascade R-CNN
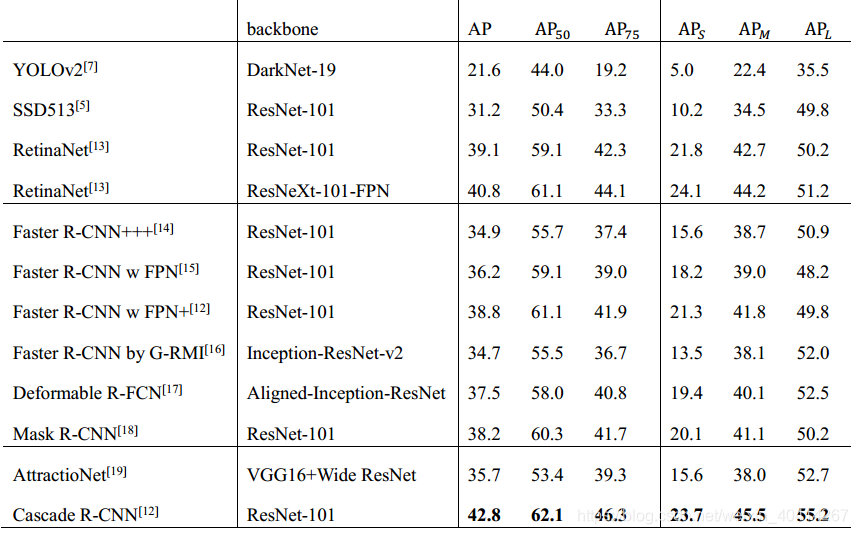
该算法是针对的是检测问题中的IoU阈值选取问题[12]。在classification中,每个proposal会根据一个指定的IoU值判断为正样本或负样本,在bounding-box regression中,每个被标记为正样本的bounding-box会向其ground-truth方向回归。阈值选取越高确实越容易得到高质量的样本,但是一味选取高阈值会引发两个问题,一是正样本数量减少引发的过拟合,二是在训练和测试使用不一样的阈值很容易导致错误匹配,为了解决这些问题,作者提出了Cascade R-CNN stages,用一个stage的输出去训练下一个stage,并且每个stage选用不同的阈值。这样可以保证每一级的header都可以得到足够多的正样本,且正样本的质量可以逐级提升。在训练和测试时,这个操作也都保持一致。在测试中,使用多个header输出的均值作为这个proposal最终的分数,这样检测性能会有进一步的提升。表1中为Cascade R-CNN与其他算法的性能比较[12]。
表1 Cascade R-CNN与其他算法在COCO数据集上的性能比较
3 基于回归问题的one stage检测算法
3.1 YOLOv1
Redmon等人提出的YOLO算法,是将目标检测作为一个回归问题来解决,输入含多个目标的原始图像,便能得到其中物体的位置边框和其所属的类别及其相应的置信度[6]。YOLO基于Google-Net图像分类模型,是一个可以一次性预测多个位置和类别的卷积神经网络,真正意义上实现了端到端的目标检测,检测速度快,但精度相比Faster R-CNN略有下降。
3.2 YOLOv2&YOLO9000
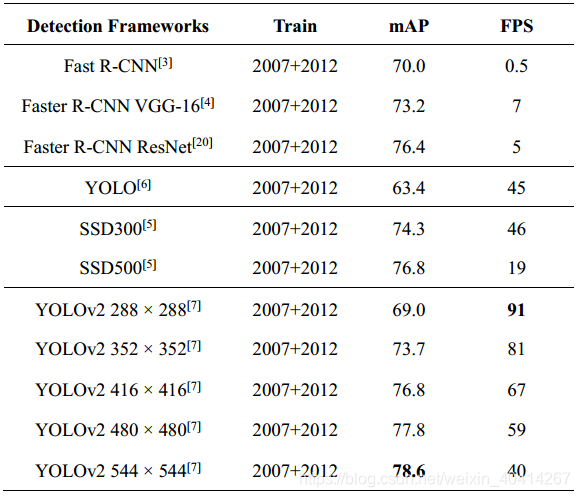
YOLO的第二个版本YOLOv2,在v1的基础上做了很多的优化。YOLOv1在准确度,速度,容错率上都有所欠缺,作者采用了一系列的方法优化了YOLOv1的模型结构,产生了YOLOv2[7]。首先,作者在所有卷积层应用了Batch Normalization,Batch Normalization可以提高模型收敛速度,减少过拟合,使map提升了2%;其次,YOLOv1接受图像尺寸为224×224, 在YOLOv2中,作者采用448×448分辨率的ImageNet数据微调使网络适应高分辨率输入,高分辨率输入使结果提升了4%的mAP;除此之外,去掉了YOLO的全连接层,采用固定框(anchor boxes)来预测bounding boxes,去除了一个pooling层来提高卷积层输出分辨率,修改网络输入尺寸,由448×448改为416×416,使得特征图只有一个中心,虽然略降低了map,却大大提升了召回率;作者还使用多尺度训练,使模型对不同尺寸的图像具有鲁棒性。表2中列举了YOLOv2和其他检测框架在PASCAL VOC 2007上的测试性能,可以看出,在高分辨率下,YOLOv2在VOC 2007上具有78.6的 mAP,仍然可以达到实时检测[7]。
YOLO9000通过结合分类和检测数据集,使得训练得到的模型可以检测约9000类物体,网络结构和YOLOv2类似,区别是每个单元格只有3个Anchor Boxes。作者采用word-tree的方法,综合ImageNet数据集和COCO数据集训练YOLO9000,使之可以实时检测超过9000种物品[7]。
表2 各检测框架在PASCAL VOC 2007上的测试性能比较
3.3 SSD
SSD算法可直接预测目标的坐标和类别,没有生成候选框的过程。网络直接在VGG16网络的基础上进行修改得到。SSD首先使用2个卷积层替换VGG16网络的最后2个全连接层,然后在VGG网络的后面增加4个卷积层[5]。为了检测目标,SSD分别使用两个卷积核为3×3的卷积层对其中5个卷积层的输出进行卷积。其中一个卷积层输出类别作为类别预测结果,另一个卷积层输出包含回归时的目标位置作为位置预测结果[5]。SSD的核心是结合回归思想使用一系列检测器来预测目标的类别和位置。主要从两个方面实现快速高检测精度的目标检测效果,一是对不同尺寸的卷积层输出进行回归,二是通过增加检测器的宽高比来检测不同形状的目标。
3.4 RetinaNet
Two-stage的检测器精度高,速度慢;One-stage的检测器速度快,精度低。作者希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度[13]。论文找出了One-stage检测器精度低的原因,并提出了解决办法。One-stage检测器精度低,究其原因,就是正负样本不均衡,只有少数样本包含目标物体,绝大多数样本都是背景。负样本多是容易分类的,其数量过多,占总loss的大部分,这样会掩盖那些少数真正含有目标信息的正样本,模型的优化方向会向占loss比重大的方向更新,这并不是我们所希望的。作者提出一种新的损失函数focal loss,降低易分类样本的权重,使模型的更新方向向少量有用样本的方向靠拢[13]。其检测性能见表1。
3.5 Refine-Det
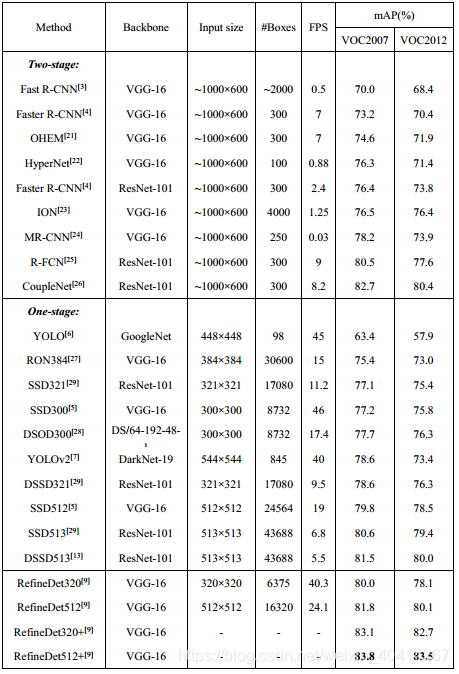
Refine-Det方法,同行继承了two-stage和one-stage两者的优点。网络结构由两个模块构成,一个是anchor细化模块(ARM),另一个是目标检测模块(ODM)。ARM模块用来减小分类器的搜索空间,粗略地描述anchor的位置和大小。通过连接模块(TCB)将ARM中的特征传输给ODM模块,以获取更加准确的目标位置和大小[9]。简单地说,就是将原来two-stage的串行结构转化成了并行。RefineDet与其他算法在VOC数据集上的性能测试见表3[9]。
表3 RefineDet与其他算法在VOC数据集上的性能测试
3.6 YOLOv3
相对于YOLO v2,YOLOv3的检测精度大大提升,而检测速度并没有下降。改进的地方有:v3替换了v2的soft-max loss,改成了logistic loss;v2作者用了5个anchor,v3用了9个anchor,提高了IOU;其次,YOLO v3采用上采样和融合的做法,使用检测层在三种不同尺寸的特征图上进行检测,分别具有stride=32,16,8,这意味着,在输入416 x 416的情况下,我们使用13 x 13,26 x 26和52 x 52的比例进行检测,即融合了3个尺度(1313、2626和52*52),在多个尺度的融合特征图上分别独立做检测,对小目标的检测效果明显提升;最后,由于卷积层数量明显增多,v2的darknet-19变成了v3的darknet-53[8]。表4中列出了YOLOv3和其他一些算法比较的mAP值和运行时间,可以看出,YOLOv3运行速度明显比其他算法快很多[8]。
表4 YOLOv3与其他检测框架在COCO数据集上的测试性能比较

3.7 Relation Networks
该算法引入了物体之间的关联信息,在神经网络中对物体间的relation进行建模。提出了一种relation module,可以在以往常见的物体特征中融合进物体之间的关联性信息,同时不改变特征的维数,能很好地嵌入目前各种检测框架,提高性能[10]。同时,提出了一种特别的代替NMS的去重模块,可以避免NMS需要手动设置参数的问题[10]。
3.8 RFB-Net
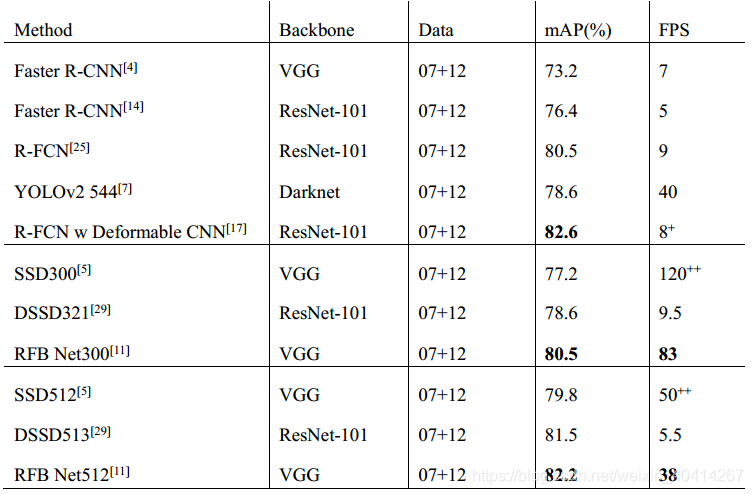
RFB-Net检测器利用多尺度one-stage检测框架SSD,在其中嵌入RFB模块,使得轻量级主干SSD网络也能更快更准[11]。原始SSD,基础主干网络后面接一系列重叠的卷积层,得到一系列空间分辨率减小而感受野增大的特征图。RFB-Net保持了这种结构,并做了些改进,用RFB模块替换了原来的L2归一化,从前面卷积层获取包含小目标的底层特征图[11]。RFB-Net与各算法性能比较见表5[11]。
表5 RFB-Net与各算法在VOC2007数据集上的性能比较
4 总结和展望
本文详细对基于深度学习的目标检测算法进行了较为全面的梳理,总结了各算法相比于先前算法的改进策略,及其本身的创新点及不足之处,对于目标检测领域的研究人员具有重要的参考价值。
目标检测应用范围非常广,例如,在行人检测、车辆检测、卫星遥感对地监测、无人驾驶、交通安全等领域。目前,基于深度学习的目标检测已经取得了很多重要成果,但同时也面临着诸多挑战,例如目标背景的多样性,动态场景的不断变化,对检测系统时效性和稳定性的要求也在逐渐提高。无论是在检测算法方面,还是硬件加速方面,目标检测都存在着许多难点和挑战,等待着我们去进一步突破。
5 参考文献
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for
accurate object detection and semantic segmentation,” in IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 2014.
[2] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in European Conference on Computer Vision (ECCV), 2014.
[3] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object
detection with region proposal networks,” in Neural Information Processing
Systems (NIPS), 2015.
[5] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD:
single shot multibox detector. In ECCV, pages 21–37, 2016.
[6] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, pages 779–788, 2016.
[7] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages 6517–6525. IEEE, 2017.
[8] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv, 2018.
[9] Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, Stan Z. Li. “Single-Shot Refinement Neural Network for Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai and Yichen Wei, “Relation Networks for Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[11] Songtao Liu, Di Huang, and Yunhong Wang, “Receptive Field Block Net for Accurate and Fast Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[12] Zhaowei Cai,and Nuno Vasconcelos,“Cascade R-CNN: Delving into High Quality Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[13] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. In ICCV, 2017.
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[15] T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
[16] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. CoRR, abs/1611.10012, 2016.
[17] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017.
[18] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In ICCV, 2017.
[19] S. Gidaris and N. Komodakis. Attend refine repeat: Active box proposal generation via in-out localization. In BMVC, 2016.
[20] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[21] A. Shrivastava, A. Gupta, and R. B. Girshick. Training region-based object detectors with online hard example mining. In CVPR, pages 761–769, 2016.
[22] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. In CVPR, pages 845–853, 2016.
[23] S. Bell, C. L. Zitnick, K. Bala, and R. B. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, pages 2874–2883, 2016.
[24] S. Gidaris and N. Komodakis. Object detection via a multiregion and semantic segmentation-aware CNN model. In ICCV, pages 1134–1142, 2015.
[25] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: object detection via region-based fully convolutional networks. In NIPS, pages 379–387, 2016.
[26] Y. Zhu, C. Zhao, J. Wang, X. Zhao, Y. Wu, and H. Lu. Couplenet: Coupling global structure with local parts for object detection. In ICCV, 2017.
[27] T. Kong, F. Sun, A. Yao, H. Liu, M. Lu, and Y. Chen. RON: reverse connection with objectness prior networks for object detection. In CVPR, 2017.
[28] Z. Shen, Z. Liu, J. Li, Y. Jiang, Y. Chen, and X. Xue. DSOD: learning deeply supervised object detectors from scratch. In ICCV, 2017.
[29] C. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. DSSD : Deconvolutional single shot detector. CoRR, abs/1701.06659, 2017.
如有错误,欢迎指正~~