在这项工作中,作者首先观察到,对于语义分割,低密度区域在隐藏表示中比在输入中更明显。
作者提出了交叉一致性训练,其中预测的不变性是施加不同的扰动在编码器输出上
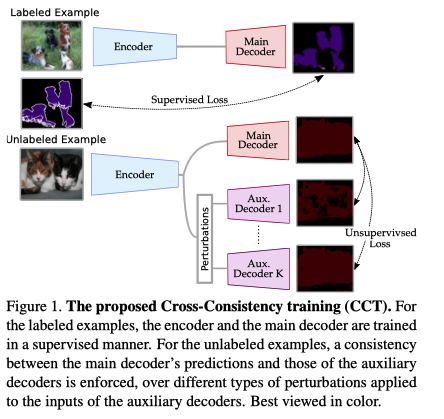

Cross-Consistency Training
该模型包含一个共享的encoder,一个main decoder和K个辅助decoder
对于有标签的数据,使用Cross-Entropy (CE)来进行训练
对于无标签的数据,使用共享的encoder得到中间特征
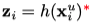
使用扰动函数pr对encoder的输出进行扰动,每一个扰动可以用于多个辅助decoder,
将K个扰动版本的输出 输入到辅助decoder中
使用mean squared error (MSE)作为距离衡量,旨在缩小main decoder和辅助decoder之间的差异

为了避免使用主编码器的初始噪声预测,Wu沿着高斯曲线从零开始上升到一个固定的权重λu。具体地,在每次训练中,有无标签的样本数量是相同的

Note:无标签的loss不反向更新main-decoder,只有有标签的才会用来训练main-decoder
Prediction based perturbations.
Feature based perturbations
F-Noise:

F-Drop:

Prediction based perturbations.
Guided Masking:
使用掩码将检测到的object或者上下文mask掉

Guided Cutout (G-Cutout):

Intermediate VAT (I-VAT):
注入对抗扰动

Random perturbations.

Practical considerations
在每次迭代训练中,label 和 unlabel 采样数量相同,并且在label的数据上迭代的次数更多,因此过拟合的风险更大
Avoiding Overfitting.
作者发现在训练中逐渐释放监督信号有助于性能提升
将output表示为在像素上的分布概率
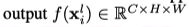
作者仅使用分布概率小于某一阈值的,
在训练期间逐渐增大阈值

Exploiting weak-labels
使用一些弱标签样本,比如image-level label,来进一步增强特征编码器H
引入了一个分类分支,使用一个pooling层,然后接一个分类器,使用binary CE loss在分类任务上预训练encoder
预训练的encoder和分类分支可用于生成pixel-level 伪标签

Cross-Consistency Training on Multiple Domains



