博弈树作为传统AI领域的一个传统又经典的算法,有着广泛的应用,尤其是棋类AI。记得曾经刚学C语言的时候,用控制台写了一个五子棋的程序。后来突发奇想,给它增加可以人机对战的AI,设计了一个简单的根据当前局面判断最优落子的AI。但是只能想到两手棋。为了提高AI的智商,学习了博弈树这个数据结构,现在给大家分享一下。
一、背景
本文拿棋类游戏的AI设计作为背景,详细介绍AI的设计过程,引入一种叫做博弈树的数据结构,以及α-β剪枝在博弈树它上面的应用。
博弈树主要应用在涉及双方互相博弈、对抗的游戏中。既然在游戏AI里面应用广泛,接下来我们结合具体游戏,来介绍。
二、极大极小树(Min-Max Tree)
首先介绍一个基本的数据结构,叫做极大极小树(Min-Max Tree)。
在设计对抗AI的游戏过程中,通常假设双方都是智商顶级的高手。因此,默认敌我双方都能够根据当前的局面,做出对自己一方最有利的决策。
然而,博弈通常是双方对抗,甚至是零和的博弈。也就是说,对对方最有利的决策,反过来就是对我方最不利的局面。在轮到我们做出决策的时候,我们通常希望最大化我们的收益,叫做极大层,此时树的节点叫做极大层节点;在对手做决策的时候,对手希望最小化我们的收益,叫做极小层,此时树的节点叫做极小层节点。由于双方是交替做出决策,因此极大层、极小层通常是交替出现,这样的数据结构就叫做极大极小树(Min-Max Tree)。
假设我们已经有一个评价每种决策的收益的估值函数。对于极大层节点,如果我们知道了它的每一步决策的收益值,那么它总是会选择收益最大的那个决策,作为它的节点的收益值;反过来,对于极小层节点,它总是会选择收益最小的(对我方收益最小,就是对方收益最大)那个决策。
举个最简单的例子,分硬币游戏。
游戏规则是:一堆硬币,双方轮流将它分成大小不能相等的两堆,然后下一个人挑选任意一堆继续分下去,双方交替游戏,直到其中一个人无法继续分下去,则对方获得胜利。
假设我们刚开始有一堆7枚硬币,轮到我方先分。我需要找到我当前应该怎么样分这堆硬币。或者说,需要找到当前能够获得最优收益的决策,我们通过构造出一棵极大极小树来做到。
首先,我们穷举所有的可能的状态。用矩形代表轮到我方做决策的极大层节点,用圆形代表轮到对方做决策的极小层节点,列举出所有的状态:
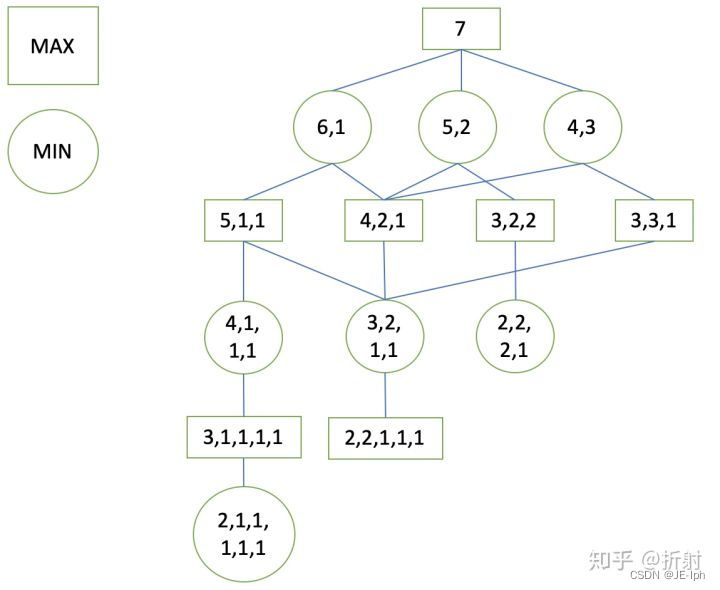
注意,到这里我们还没有进行估值 ,因此这还不算是极大极小树。下面我们来设计这个游戏的估值函数,很简单,如果当前局面,我们已经赢了,那么收益为+1,如果我们输掉了,那么收益为-1,这个游戏没有平局,所以只可能有这两种收益值。
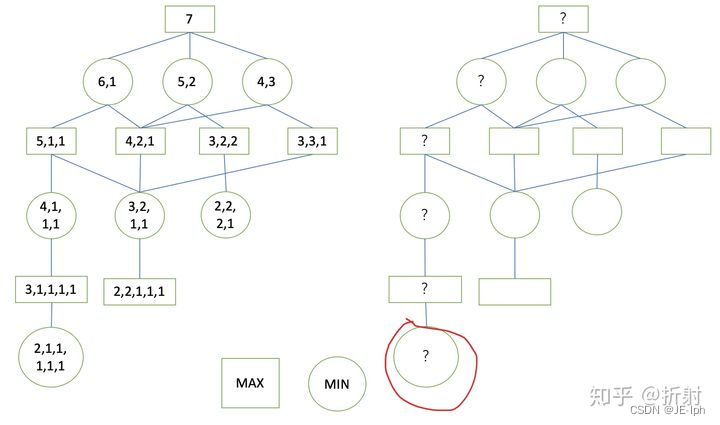
刚开始估值的时候,我们还位于根节点,我们对于整棵树是一无所知的,就像下面这样:
我们想要获得根节点的估值,需要对根节点的子节点进行遍历,首先对第一个子节点进行遍历,发现还是不能判断它的值,继续遍历(深度优先)它的子节点,直到到达叶子节点:
到了叶子节点,我们可以对它进行估值了,因为此时是极小层,需要对手进行决策,但是对手已经无法再继续分下去了。所以,它的收益值为+1:

这样获得了第一个叶子节点的估值,由于它的父节点只有唯一一个子节点,因此父节点的收益值也只能是+1,然后可以一直回溯上去,直到到达红色的节点
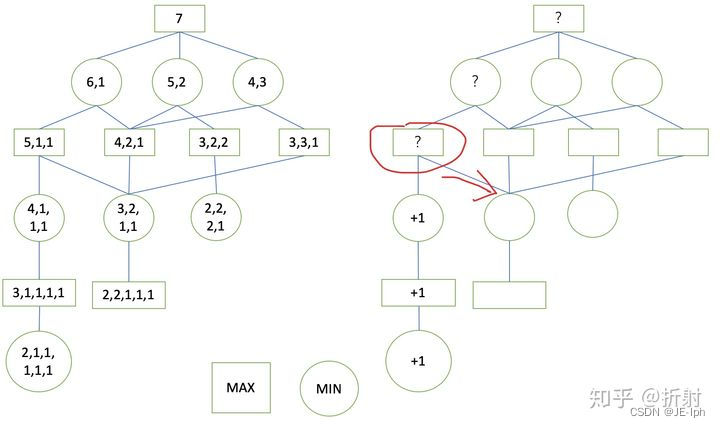
此时,我们不能直接给红色节点赋值了,因为它还有别的子节点,我们继续遍历它的子节点:
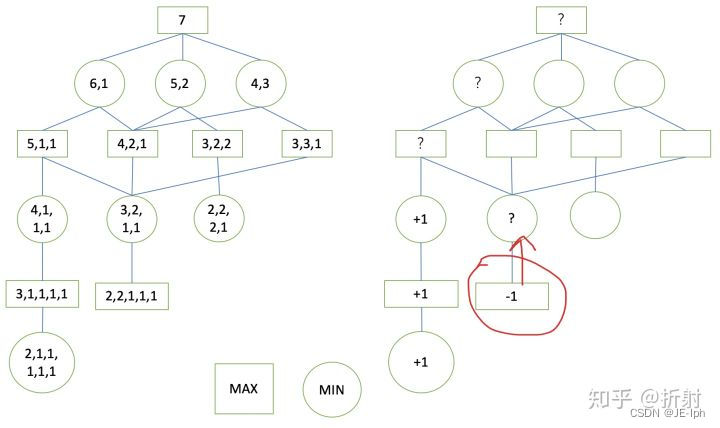
遍历到又一个叶子节点,发现它的收益是-1(我方失败),再回溯回去:
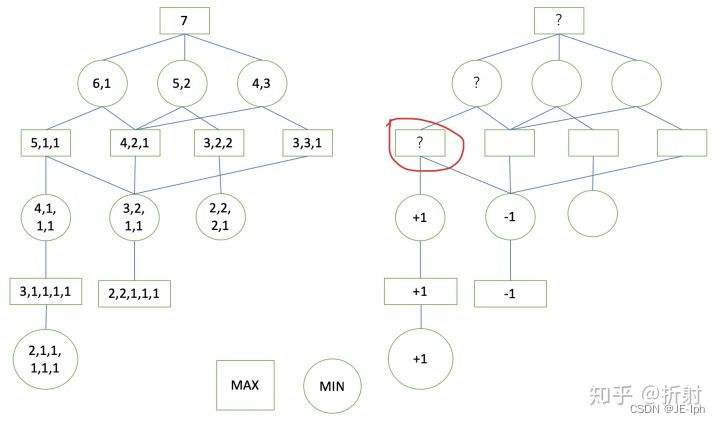
现在我们又回到了红色节点,现在它的所有子节点的收益值都已经获得了。注意,这个节点是一个极大层节点。我们说过,极大层节点总是会选择收益最大的子节点,它的子节点一个是+1一个是-1,因此,它的值应该是最大的那个+1。我们继续按照深度优先的顺序遍历:
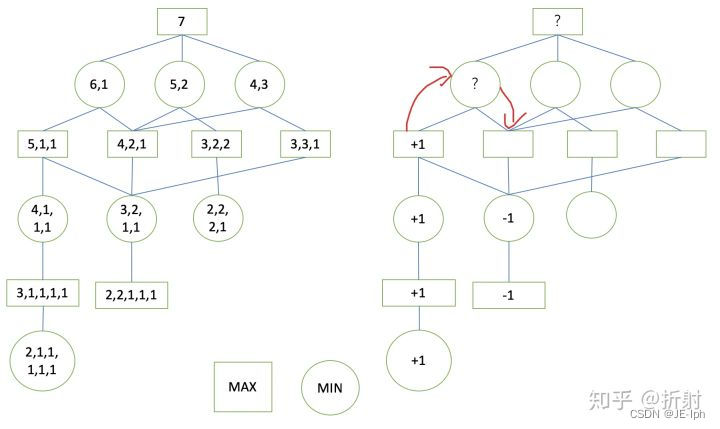
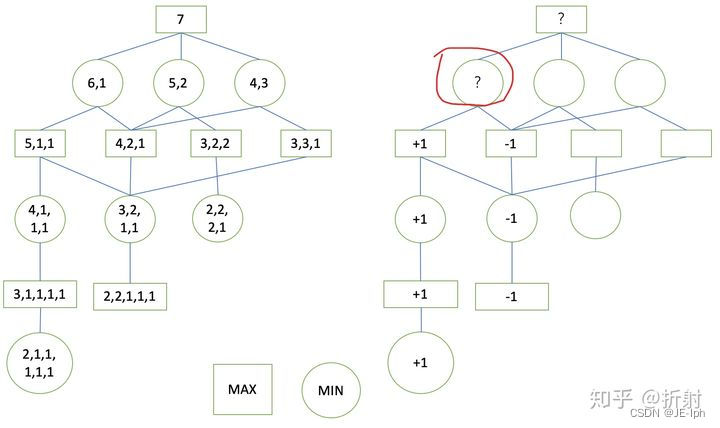
到这里,当前红色的节点是一个极小层节点,它总是选择收益最小的决策,因此它的收益值是-1。 接下来,我们继续按照这个思路进行遍历,中间的过程我就省略了,最后的结果如下所示:、
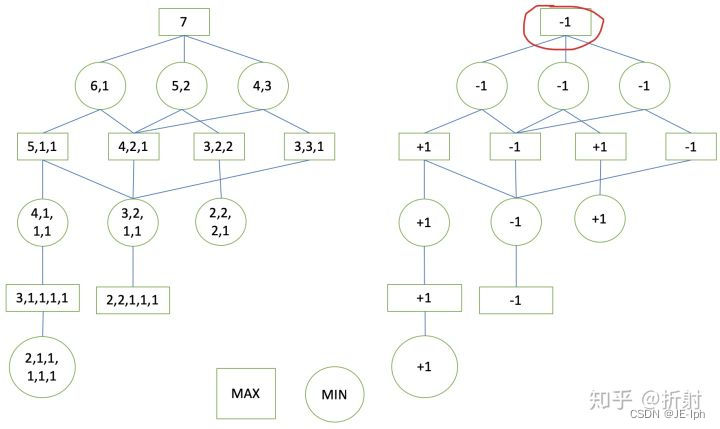
到这里,我们的极大极小树已经构建完成了。
我们发现,当前的根节点的收益值居然是-1,也就是说,只要对方够聪明,我们无论如何都无法取胜。
这就很绝望了,但是仔细想想,我们假设的前提是,对方是聪明绝顶,不犯错误的高手。
我们知道无论如何都会失败,那可不可以赌对方会犯错呢。
这样一想,其实3种必败的决策还是有一定的优劣性的。比如,最右边那个子节点,它的所有子树跟子树的子树收益都是-1,也就是说,对方就算乱下,我们都必输;而中间跟左边那个子节点,如果对手下错了,还有一一定几率能够通往+1的叶子节点的。因此,左边两个决策要比最右边的决策要相对好那么一点儿。因此,在发现我们已经必败的时候,依然能够在决策中做一个取舍,选择败得不明显的那种决策。