前言:哈喽小伙伴们好久不见,也是顺利的考完试迎来了寒假。众所周知,
不怕同学是学霸,就怕学霸放寒假
,假期身为弯道超车的最佳时间,我们定然是不能懒散的度过。
今天我们就一起来学习数据结构初阶的终章——
七大排序
。
本文所有的排序演示都为升序排序
。
目录
一.为什么要排序
二.七大排序
1.冒泡排序
2.选择排序
3.堆排序
4.插入排序
5.希尔排序
6.快速排序
7.归并排序
三.总结
一.为什么要排序
我们知道,数据结构的诞生是为了存放和管理众多的数据。而
排序
,就是
最常用也是必不可少的数据管理方式
,能够帮助我们更加轻松和方便的去找到自己想要的结果。
二.七大排序
数据结构中常用的排序有七种:
-
冒泡排序
-
选择排序
-
堆排序
-
插入排序
-
希尔排序
-
快速排序
-
归并排序
下面我们就来一一讲解这七大排序的
排序方式及其性能优劣
。
1.冒泡排序
冒泡排序相信有很多小伙伴在学习C语言的时候就已经有所了解了,如下图所示,冒泡排序是
从一组数据的第一个元素开始
,
两个两个紧挨着进行比较,如果前者大于后者就进行交换
,这样便可以使
每排序一次就可以将最大值置于数据末尾
。
注意,这里紧挨着排序是指,
1和2排完之后,2紧接着和3排
。
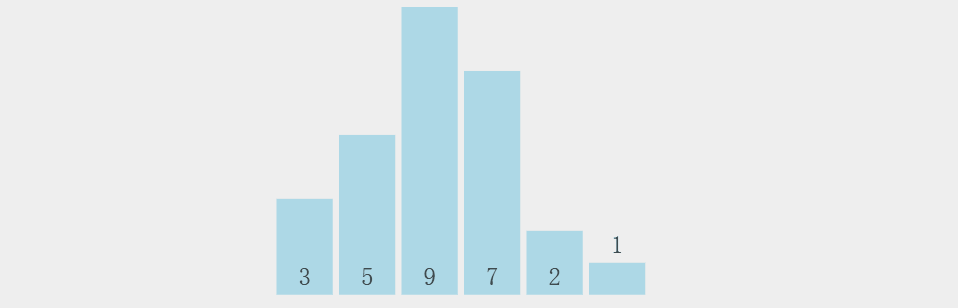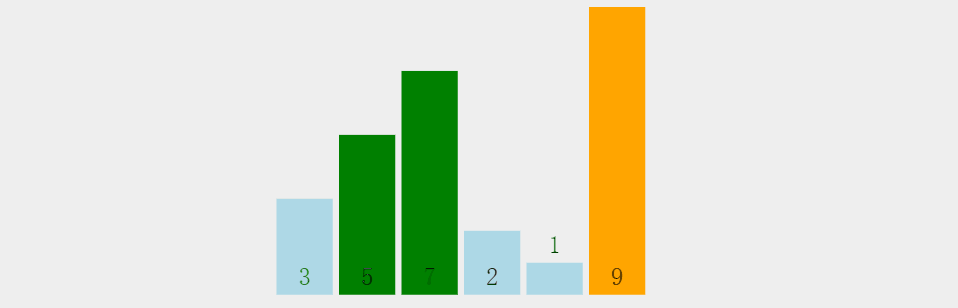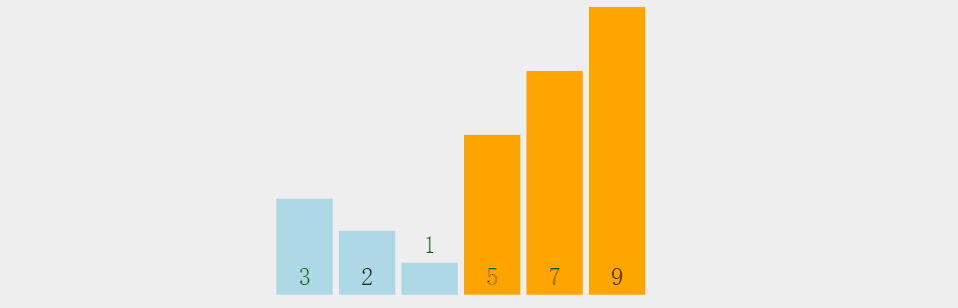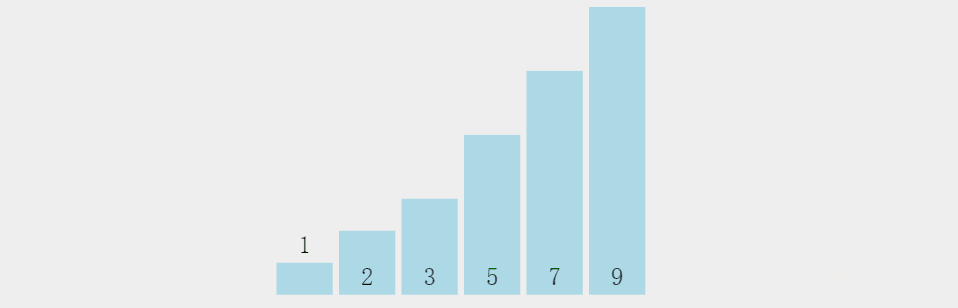
冒泡排序的原码如下:
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; j++)
{
bool flag = false;
for (int i = 0; i < n - 1 - j; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
flag = true;
}
}
if (flag == false)
break;
}
}
能够看出,冒泡排序需要
两层循环
控制,
内层循环控制单趟排序,外层循环控制总排序次数
。
n表示数据个数
,所以
总共需要排序n-1次
,即
外层循环的次数,同样也是n个数据之间两两比较的次数
。
因为
每经过一轮排序,我们都能排好最大值,所以每下一次排序都比上一次少一个数据
,所以我们通过
i < n - 1 - j
的方式就可以完美实现这一点。当然你也可以定义一个新变量去控制,但是这样会扩大空间复杂度。
冒泡排序的时间复杂度和空间复杂度:
在数据本来就有序的情况下,冒泡排序的最优时间复杂度为:O(N)
,即仅仅比较了数据大小,没有进行交换,所以我们可以设计一个
“探子”flag
去打探数据是否交换,
如果进行一次内循环发现没有交换,就说明数据本来就有序,便直接退出外循环,节省时间
。
2.选择排序
选择排序相较于冒泡排序,它是能够一次确定
头尾两个位置元素
的排序方式:
先定义begin和end两个标志点,分别代表要排序数据的头和尾,然后默认一段乱序数据的第一个元素同时为最小值min、最大值max
,然后
从第二个数据开始分别去和它们比较,更小的值替换min,更大的值替换max
,循环一次便能找到当前序列的最大值和最小值,然后
再去分别和头尾元素交换
,如此循环便可得出有序序列。
原码如下:
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mini = begin;
int maxi = begin;
for (int i = begin + 1; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[begin], &a[mini]);
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}
不难看出,
内层循环每进行一次,就能确定最大值和最小值
,
同时标志点begin和end向内移动,直到两者相遇,说明排序已经完成
。
值得注意的是,如果
恰好第一个数据就是最大值
,那么
maxi将得不到最大值的下标
,而此时我们
先交换了最小值和头元素,作为头元素的最大值的下标便变成了mini
。
所以要进行一次判断,如果最大值是头元素,就在交换了头元素和最小值之后,将mini赋值给maxi
。
选择排序的时间复杂度和空间复杂度:
3.堆排序
我们知道堆有
大堆和小堆
两个特性,而我们的堆排序则采用
大堆化小堆
来进行排序。
我们
默认一个堆按从上到下,从左到右的顺序为排序的顺序
,这就要求我们要
将更大的数据往堆的右下角去移动
,所以要
建小堆
,但是单纯只是建个小堆,可能会
出现下一层的元素大于上一层的情况
。
所以我们要
先建大堆
,这样
可以使根节点为为最大值,然后再将根节点与堆的最右下角元素交换
,然后
再将剩下的元素继续调整为大堆
,如此循环往复的去交换,便可实现排序。
源码如下:
//堆向下调整
void AdjustDown(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] > a[child])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* a, int n)
{
//建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//排序
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
堆排序的时间复杂度和空间复杂度:
4.插入排序
插入排序的原理是
从第二个数据开始
,
依次去和它前边的数据比较,如果前边的数据比它大,就进行交换,并继续向前比较,直到前边的数据比它小为止
。

源码入下:
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
break;
}
a[end + 1] = tmp;
}
}
插入排序的时间复杂度和空间复杂度:
5.希尔排序
希儿排序实际上是对插入排序的一种优化:先选定一个
整数n
,
把待排序数据分成个若干组,所有距离为n的数据在同一组内,并对每一组内的数据进行排序
。然后,
取更小的整数n重复上述分组和排序的工作
。直到当
n == 1
时,
所有数据在同一组内进行一次插入排序
。

源码如下:
void ShellSort(int* a, int n)
{
int gap = n;
//gap > 1是预排序,目的是让数据接近有序
//gap = 1是直接插入排序,目的是让数据有序
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}
gap即为所需要的整数
,一般情况下,
先让他等于数据长度,然后每次排序时都除以3再+1
。这个并不固定,只要能保证最后gap要为1即可。
希尔排序的时间复杂度和空间复杂度:
-
时间复杂度:平均为O(N^1.3)
-
空间复杂度:平均为O(1)
6.快速排序
先来看动图:

默认第一个元素为key位
,然后
头尾两个“先锋兵”开始行动,其中R先向左移动,去找到比key小的值并停下,然后L开始向右移动,找到比key大的值并停下,然后交换L和R所在位置的值,并让R开始继续移动,重复上述操作
,
直到R和L相遇,交换相遇点与key的值,并让相遇点成为新的key
。
如此操作之后,我们不难看出
最后key的左边的值都比key小,而右边的值都比key大
。这样我们
就唯一确定了key的位置。随后我们就需要去分别排序key的左半段和右半段了
,很显然,这需要用到
递归
。
源码如下:
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int left = begin;
int right = end;
int key = begin;
while (left < right)
{
while (left < right && a[right] >= a[key])
{
right--;
}
while (left < right && a[left] <= a[key])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[key]);
key = left;
QuickSort(a, begin, key - 1);
QuickSort(a, key + 1, end);
}
快速排序的时间复杂度和空间复杂度:
-
时间复杂度O(N*logN)
-
空间复杂度O(N*logN~O(N))
7.归并排序
先看动图:
不难看出,归并排序也是
类似于一组一组的排完序后再整体进行排序
。
假设我们将数据不断拆分为4组,每个小组内部先进行排序,而后1,2组排序,3,4组排序,最后排完序的两组在整体排序
。
很显然,
这样的排序方式同样需要用到递归,而且用一个数组是无法完成的,所以我们需要新建一个数组进行排序,再将排好的数据拷贝回去
。
源码如下:
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("MergeSort->malloc");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
定义mid将数据拆分为两组
,
进行两组之间的排序,将排好的顺序记录在新数组tmp中
,最后再
利用memcpy拷贝回数组a中
。
值得注意的是,在每个子递归函数中,
所递归的数据的头都是begin,尾是end
,所以
拷贝时要注意地址以及长度的写法
。
归并排序的时间复杂度和空间复杂度:
-
时间复杂度:O(N*logN)
-
空间复杂度:O(N)
三.总结
七大排序的基础知识到这里就介绍完啦,而
数据结构初阶的知识到这里也全部落下帷幕啦
。
喜欢博主文章的小伙伴记得
一键三连
哦!
点关注不迷路,博主带你玩转编程!