JIRA SoftWare
在升级或者迁移系统之前,我们需要对系统的数据进行备份。创建一份完整的JIRA Software系统数据备份,需考虑备份的内容包括:
(1)JIRA Software备份导出的XML压缩文件;
(2)附件目录下的所有文件;
(3)数据库数据备份文件;
这些备份文件的创建方法参见下面文档说明。
1.1.1 相同版本同一服务器的备份与恢复
备份
具体操作步骤如下:
(1)以系统管理员身份登录JIRASoftware系统;
(2)选择JIRA管理-系统;
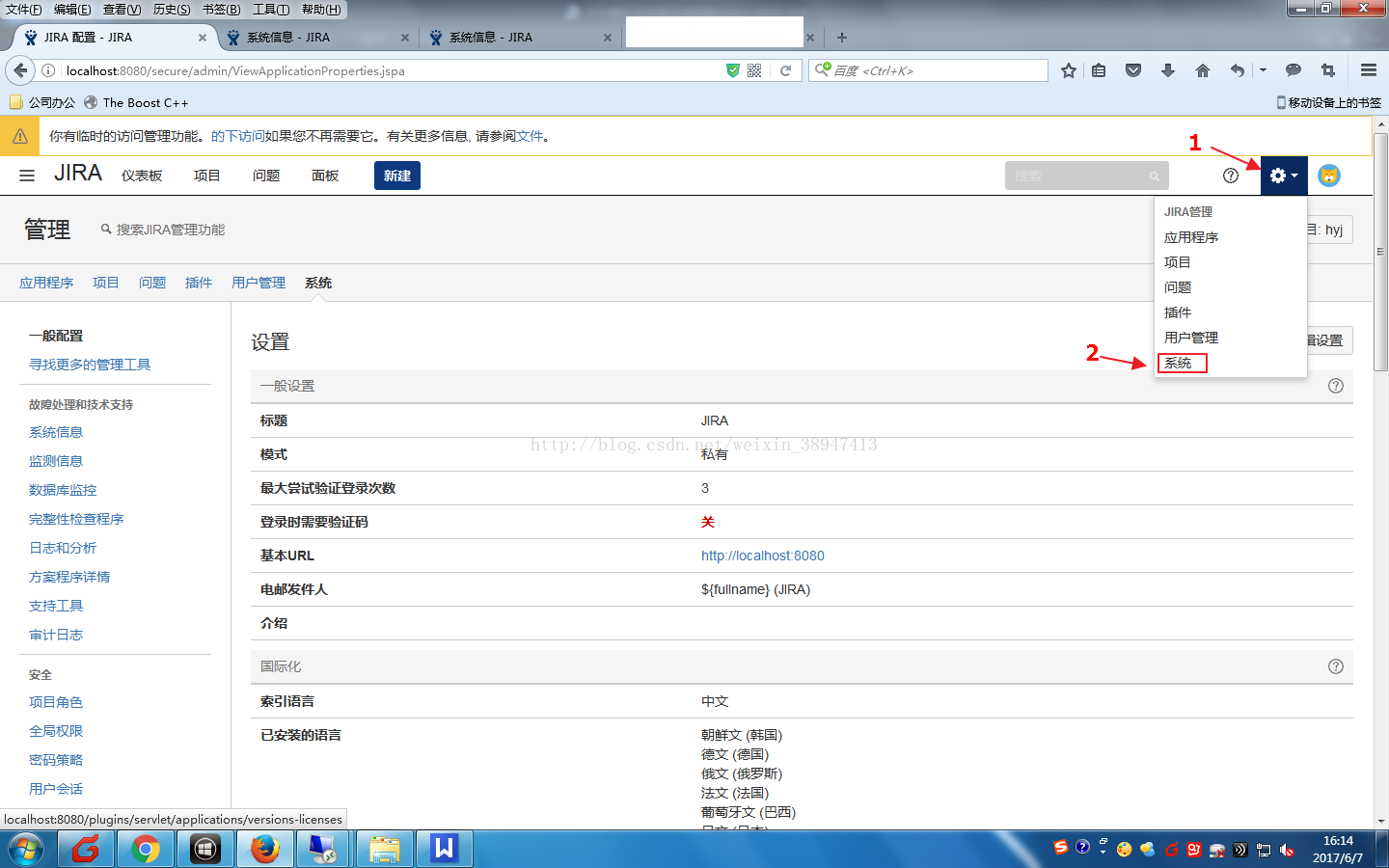
(3)选择“导入和导出”中的“备份数据”,设置备份文件名称后,点“备份”开始数据备份为XML格式
(4)如下图所示,4为备份文件路径,5为备份文件名。
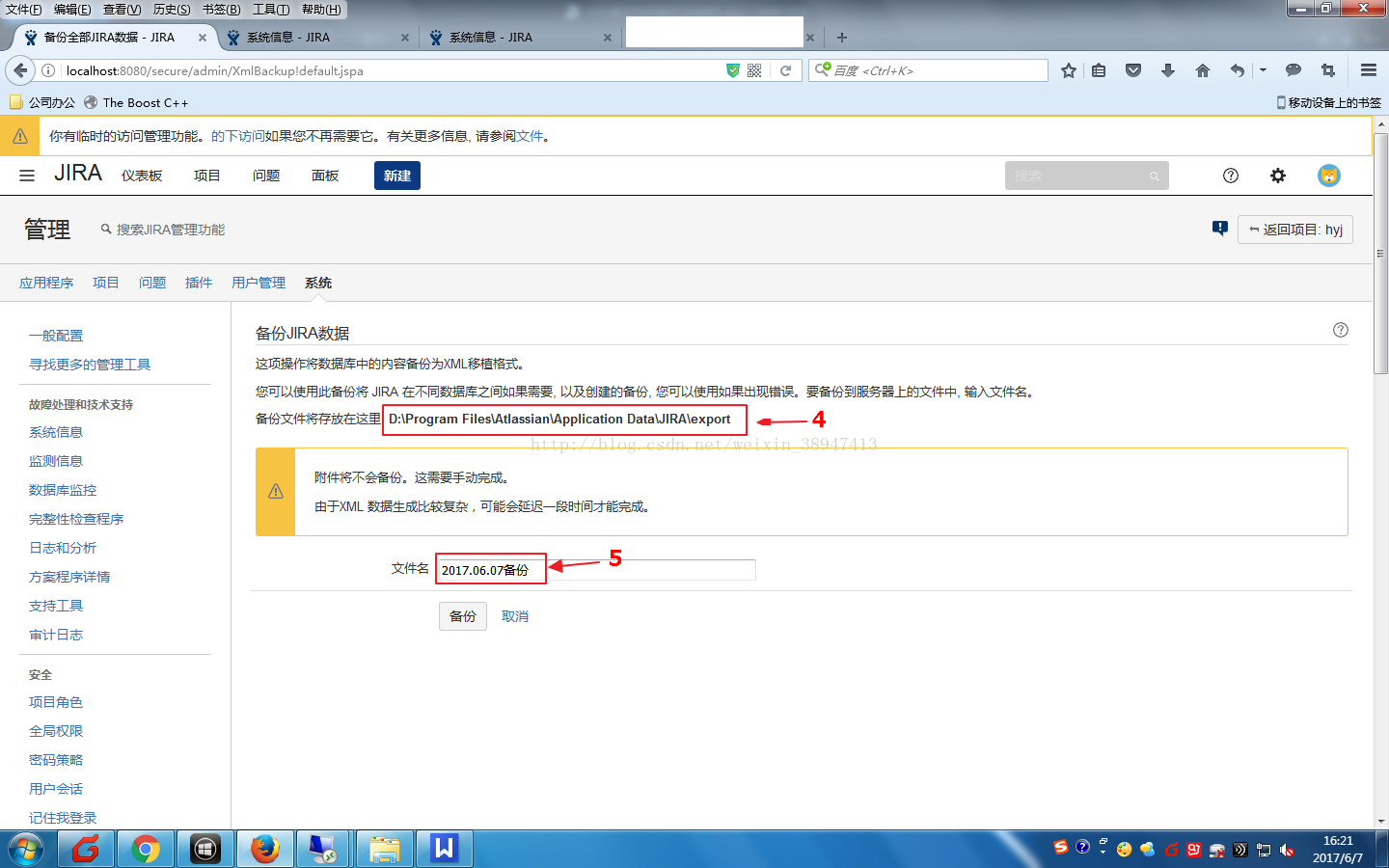
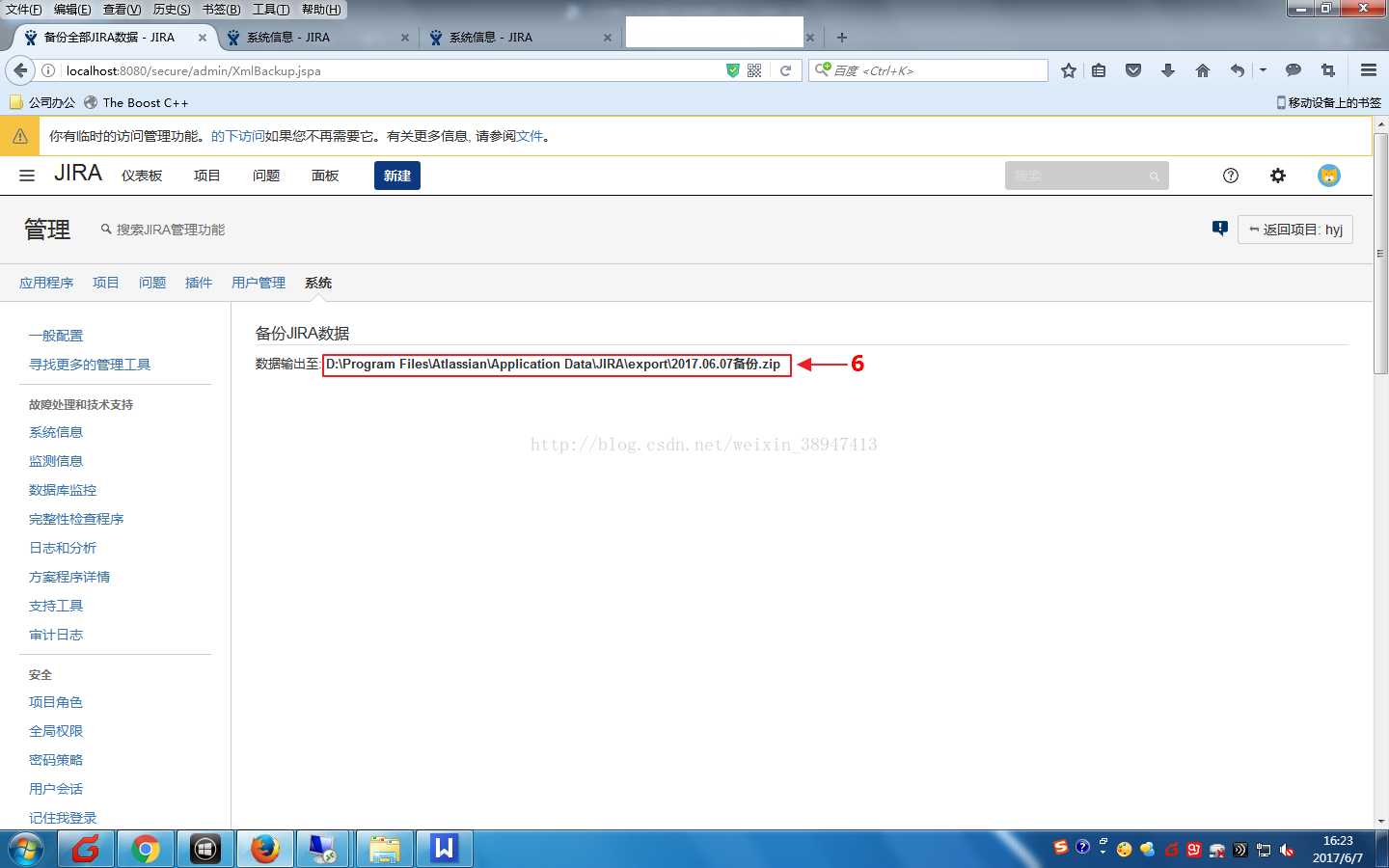
(5)备份完成后整个路径。
恢复
具体操作步骤如下:
(1)以系统管理员身份登录JIRASoftware系统;
(2)选择JIRA管理-系统;
(3)选择恢复系统;
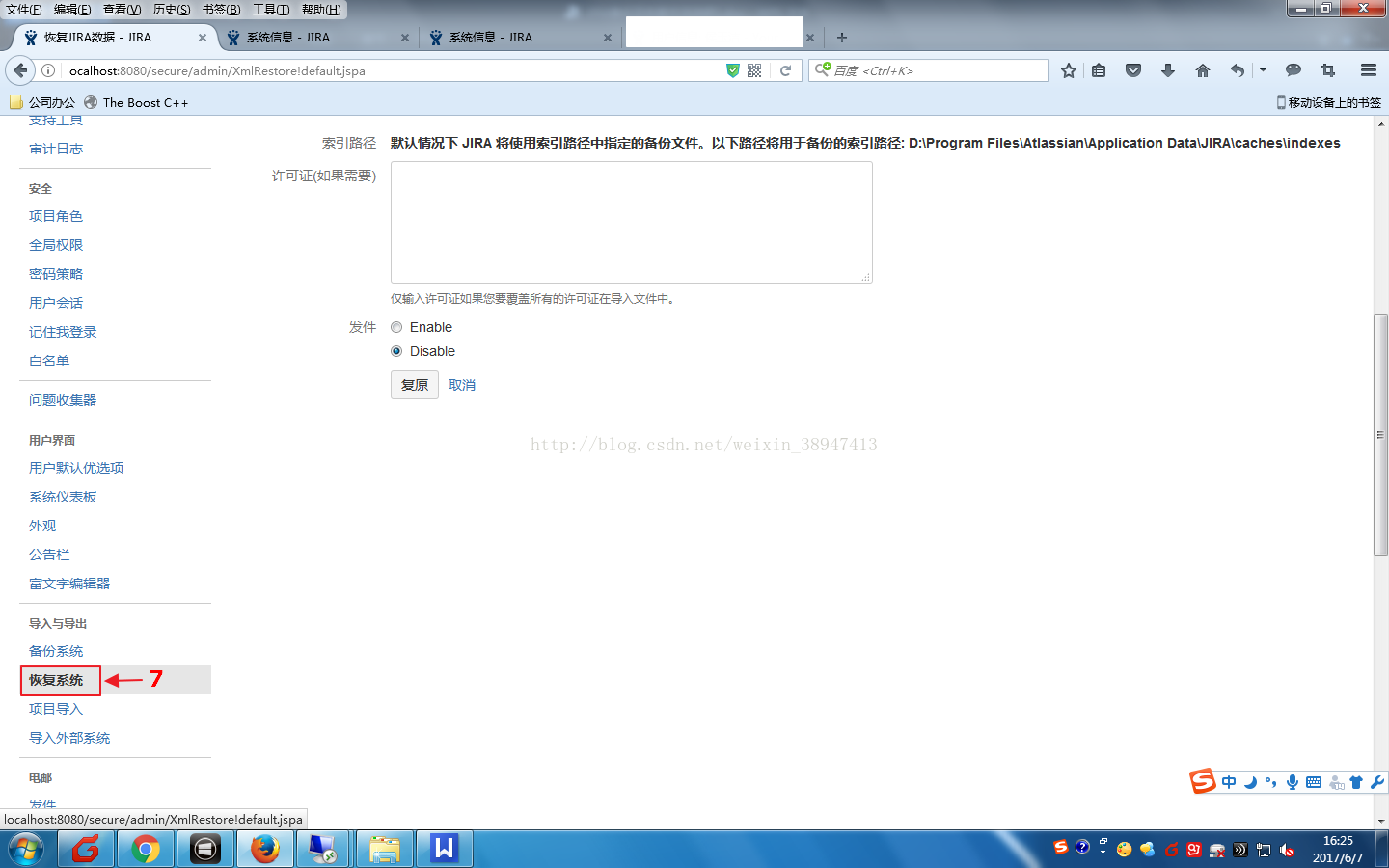
(4)根据路径选择复制备份的压缩文件;
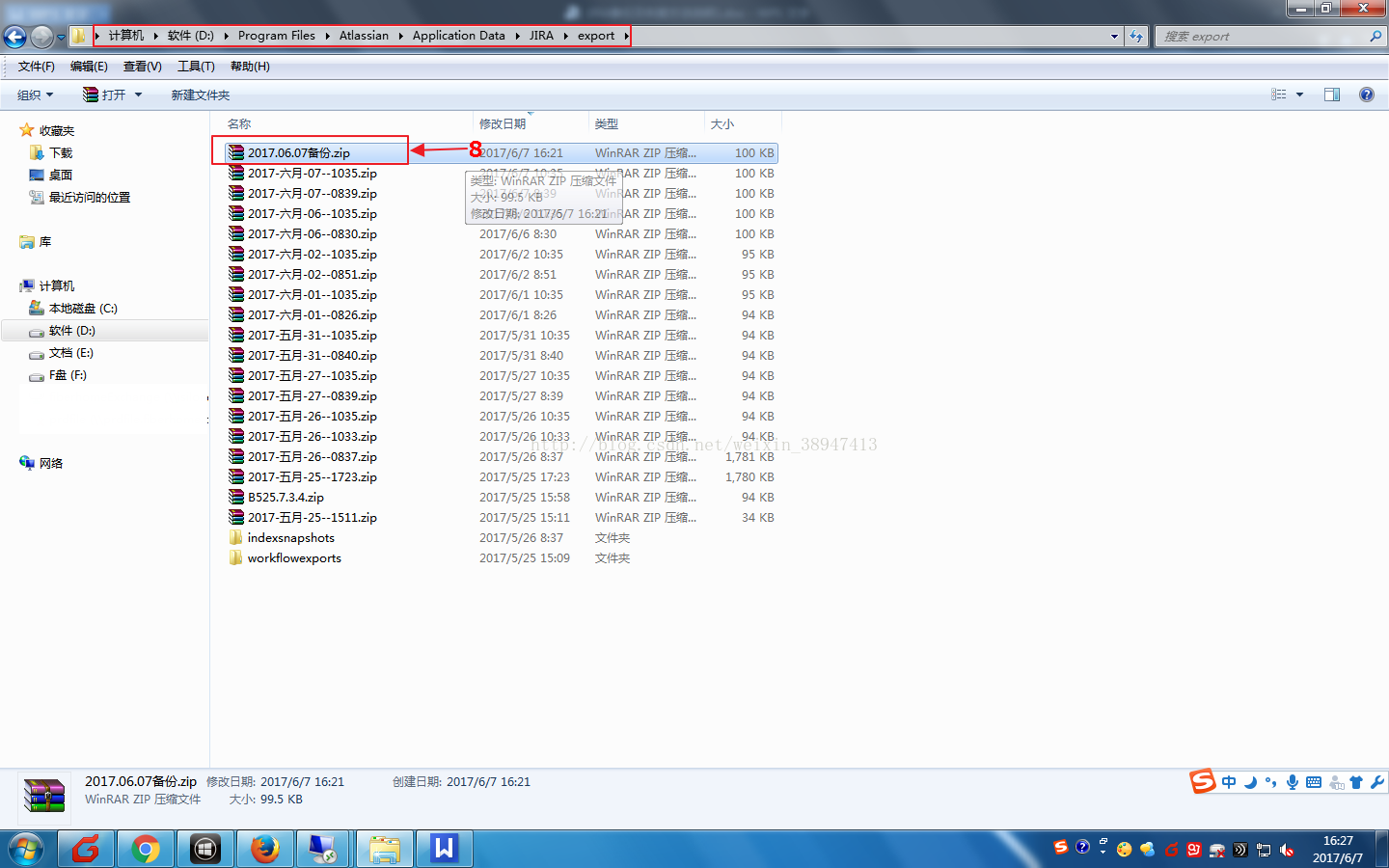
(5)将复制的压缩文件粘贴到import路径;
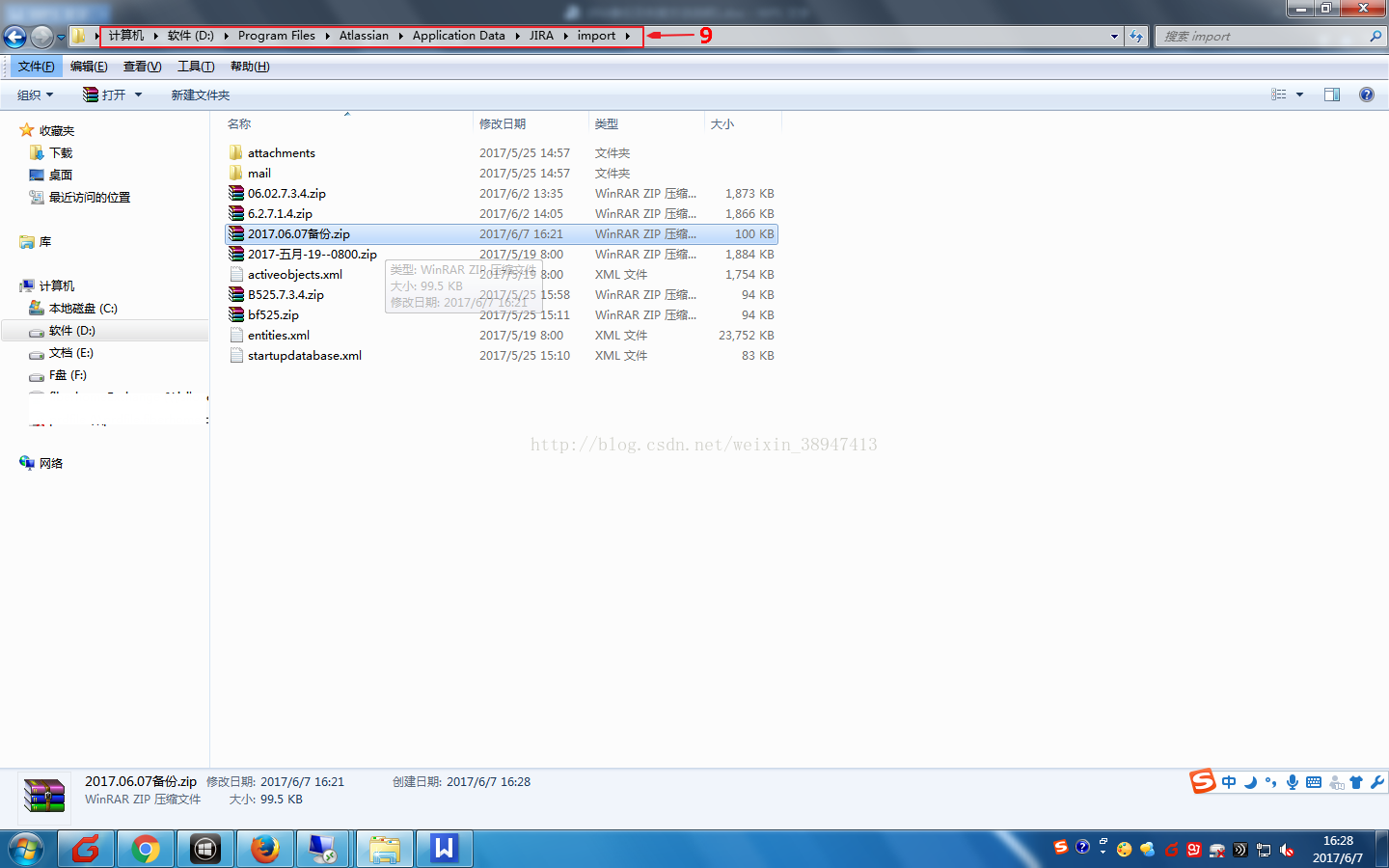
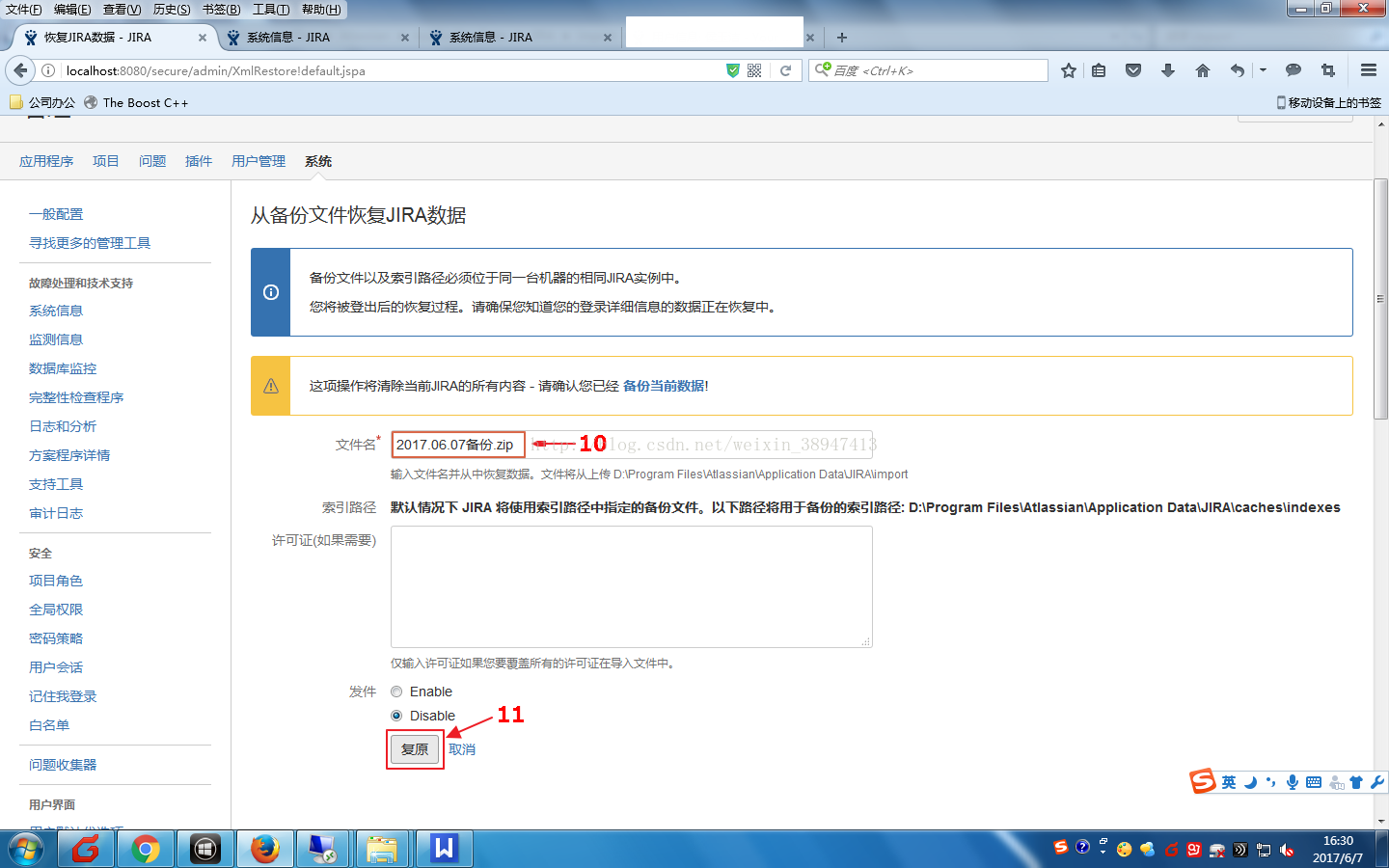
(6)输入备份的文件名点击复原
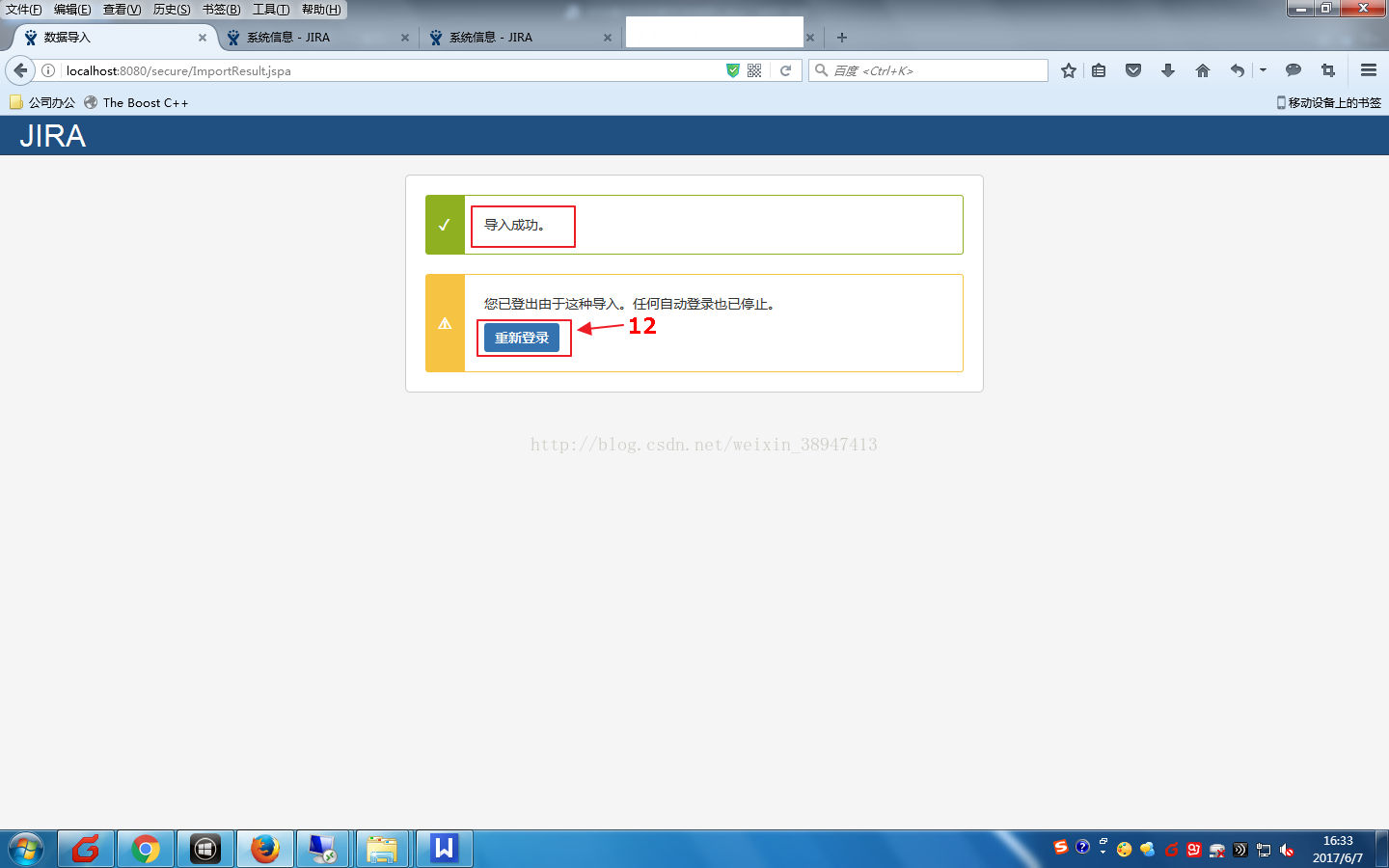
(7)文件恢复完毕之后如下图所示,再重新登录账号密码即可;
1.1.2 相同版本不同服务器的备份与恢复
一、备份
在迁移系统之前,我们需要对系统的数据进行备份。创建一份完整的JIRA Software系统数据备份,需考虑备份的内容包括:
(1)阻止用户更新JIRA数据
(2)JIRA Software备份导出的XML压缩文件;
(3)附件JIRA目录下的所有文件;
(4)备份JIRA安装目录;
二、安装
在新的服务器下安装相同版本的JIRA应用程序,安装完毕后需要操作以下事情:
(1)将您备份的JIRA目录下的所有文件覆盖到您新安装的目录下;
(2)将您的JIRA应用程序的新版本连接到一个新的空数据库
(3)将您现有的JIRA应用程序配置迁移到您的新安装
除了上面的文件之外,还应该考虑或执行以下配置过程的一部分;
(1)集成单点登录,请记住配置crowd以授予JIRA的新主机/ip访问权限
(2)插件配置,与旧版本相同
(3)字符编码,确保字符编码在新的情况下是相同的
这些备份文件的创建方法参见下面文档说明。
三、启动新的服务器的JIRA,开始导入旧服务器上的数据
在启动新的JIRA安装之后,JIRA启动它的安装向导。这是在JIRA里发生的从一个空数据库开始。从这里,您可以导入备份文件并填充数据库使用您的XML备份数据,恢复数据请参考上面恢复步骤。
注:版本为7.1.4 迁移到不同服务器
迁移到不同服务器:
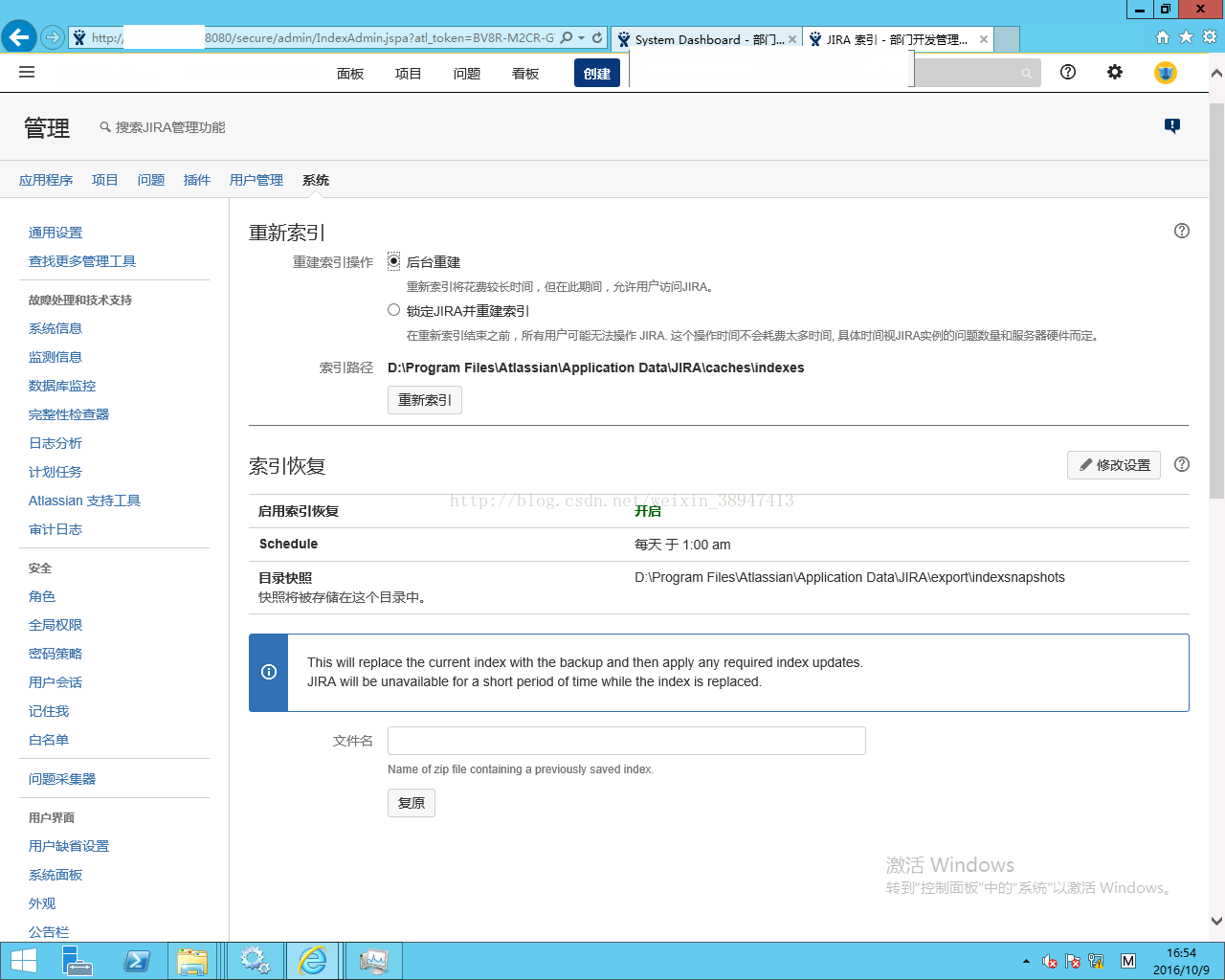
下图中D:\Program Files\Atlassian\Application Data\JIRA\是JIRA Software的数据目录,建议完整备份该目录中的数据。对于部分子目录中的内容说明如下:
(1)其中D:\ProgramFiles\Atlassian\Application Data\JIRA\caches目录中包含了索引数据,注意:建议在系统设置的“高级”-“索引”栏中设置如下;
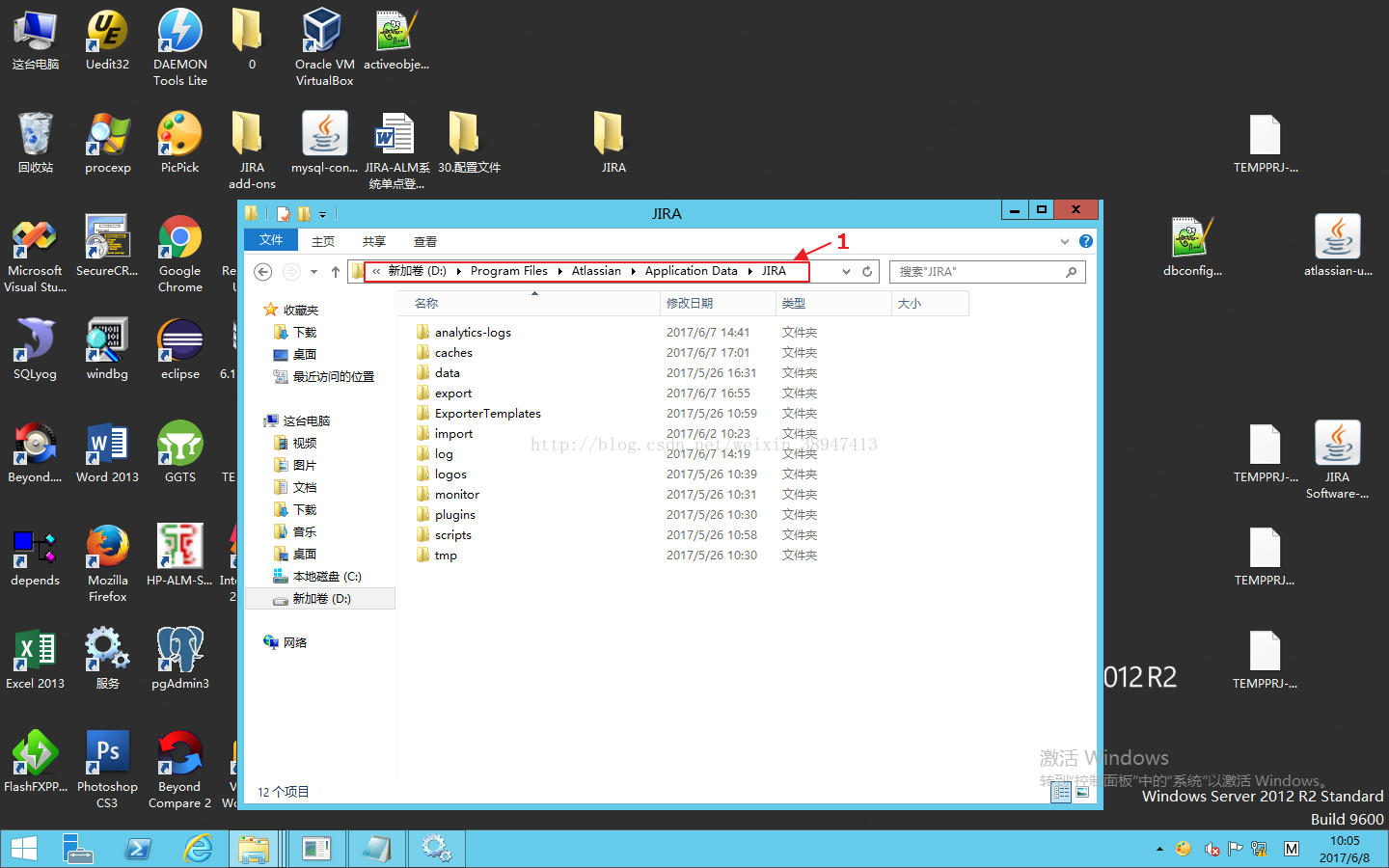
(2)D:\ProgramFiles\Atlassian\Application Data\JIRA\data\attachments为缺省的附件保存目录;
(3)D:\ProgramFiles\Atlassian\Application Data\JIRA\data\avatars为个人头像图片。
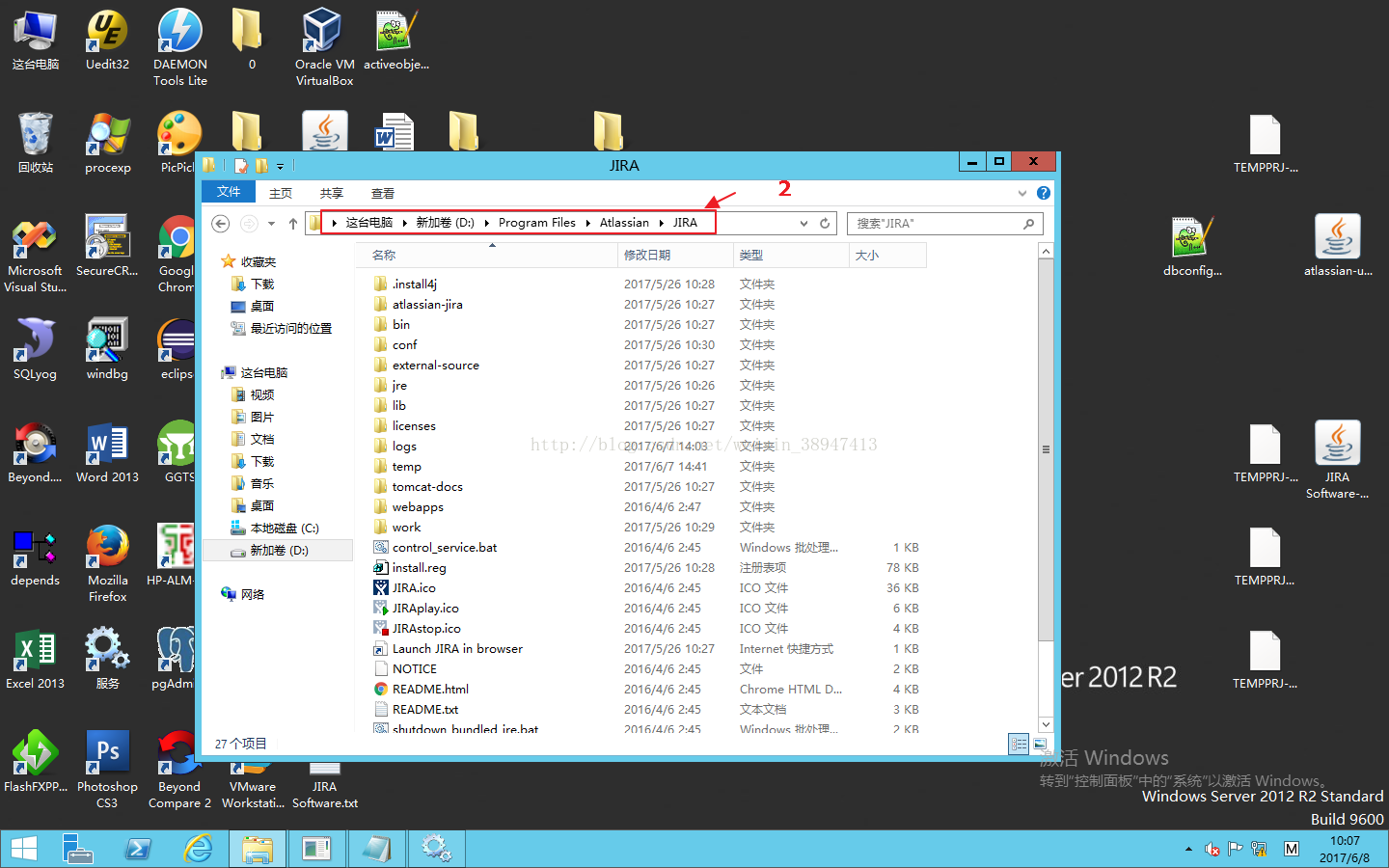
下图中D:\Program Files\Atlassian\JIRA\是JIRA Software的安装目录,建议完整备份该目录中的数据。
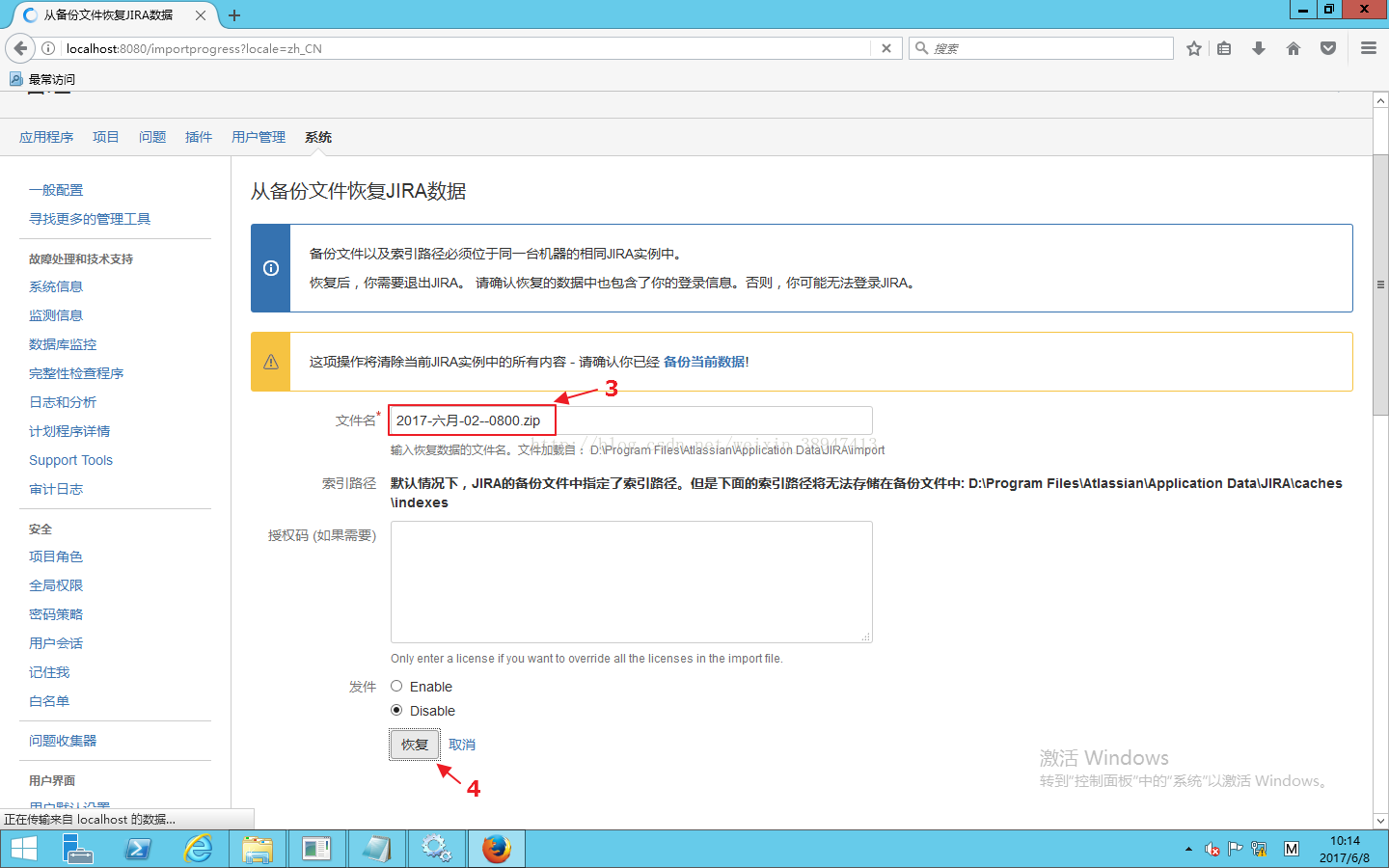
新服务器安装jira版本后,登录点击管理-系统-恢复系统,输入要恢复的压缩文件。
下图为所有数据导入成功的截图。
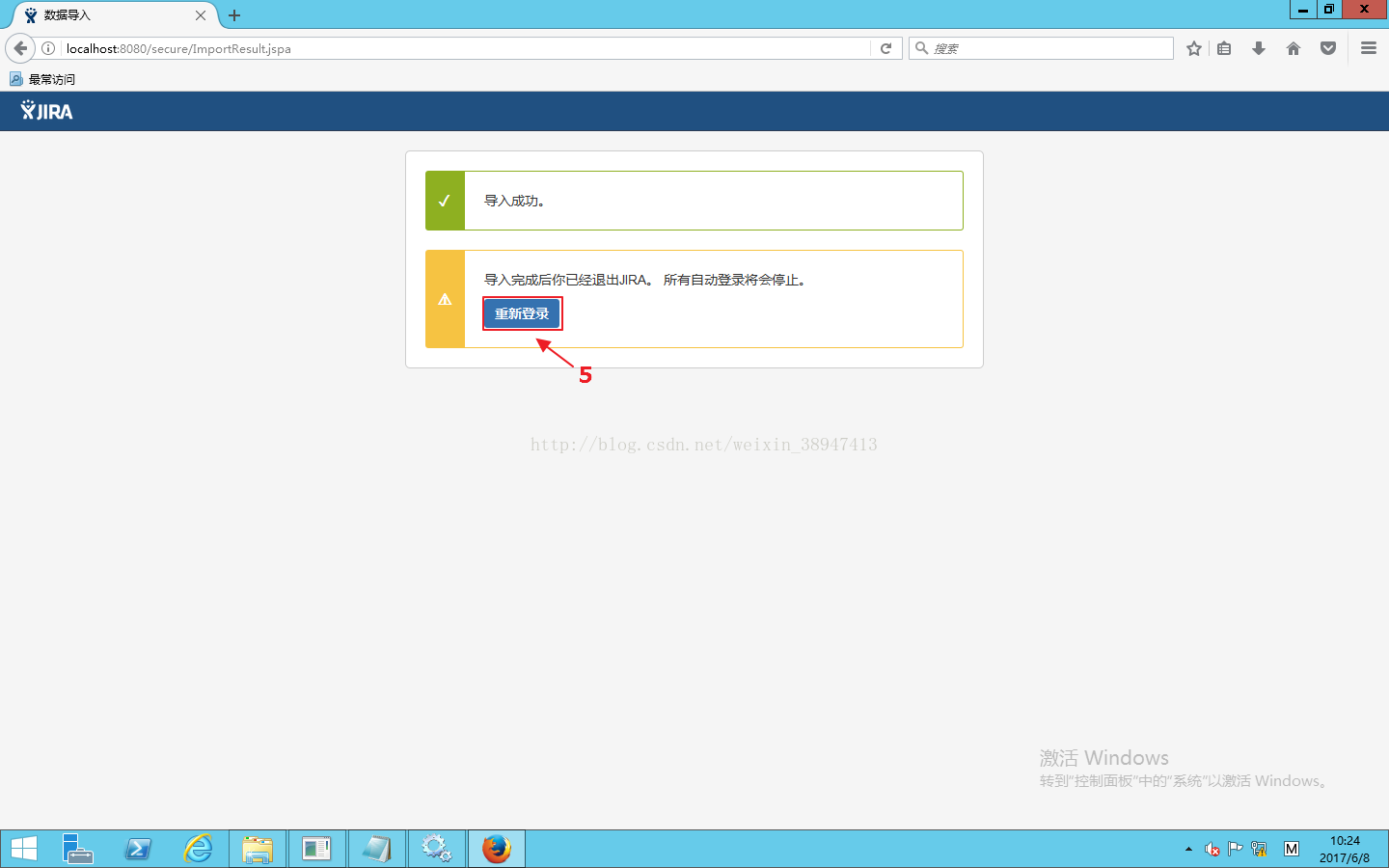
注:所有数据导入之后,我们以管理员身份登录,如图管理员登录后是以JIRA Internal Directory目录,实际上我们需要以Crowd Server目录登录,现在需配置单点登录(服务器地址需要一致)
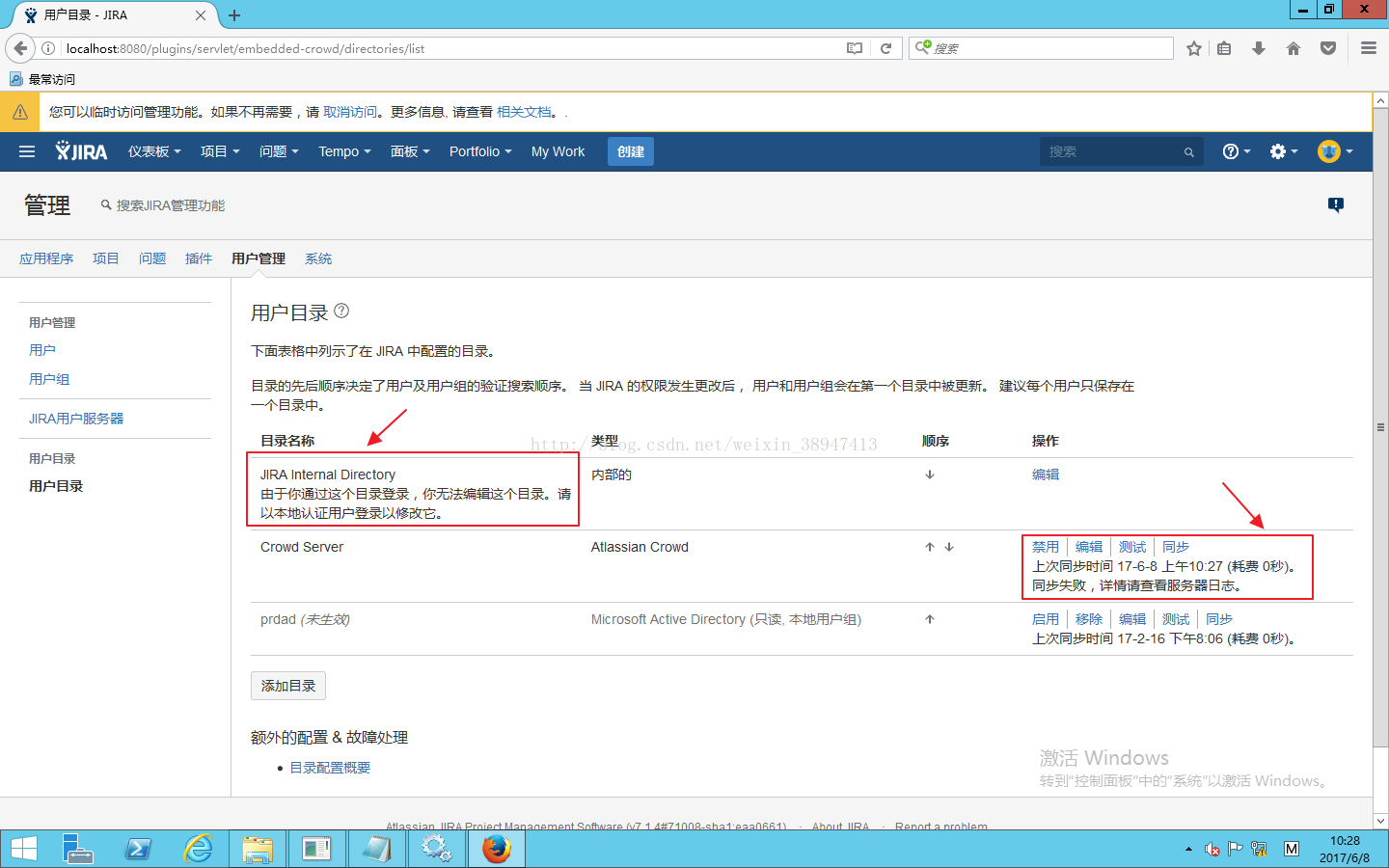
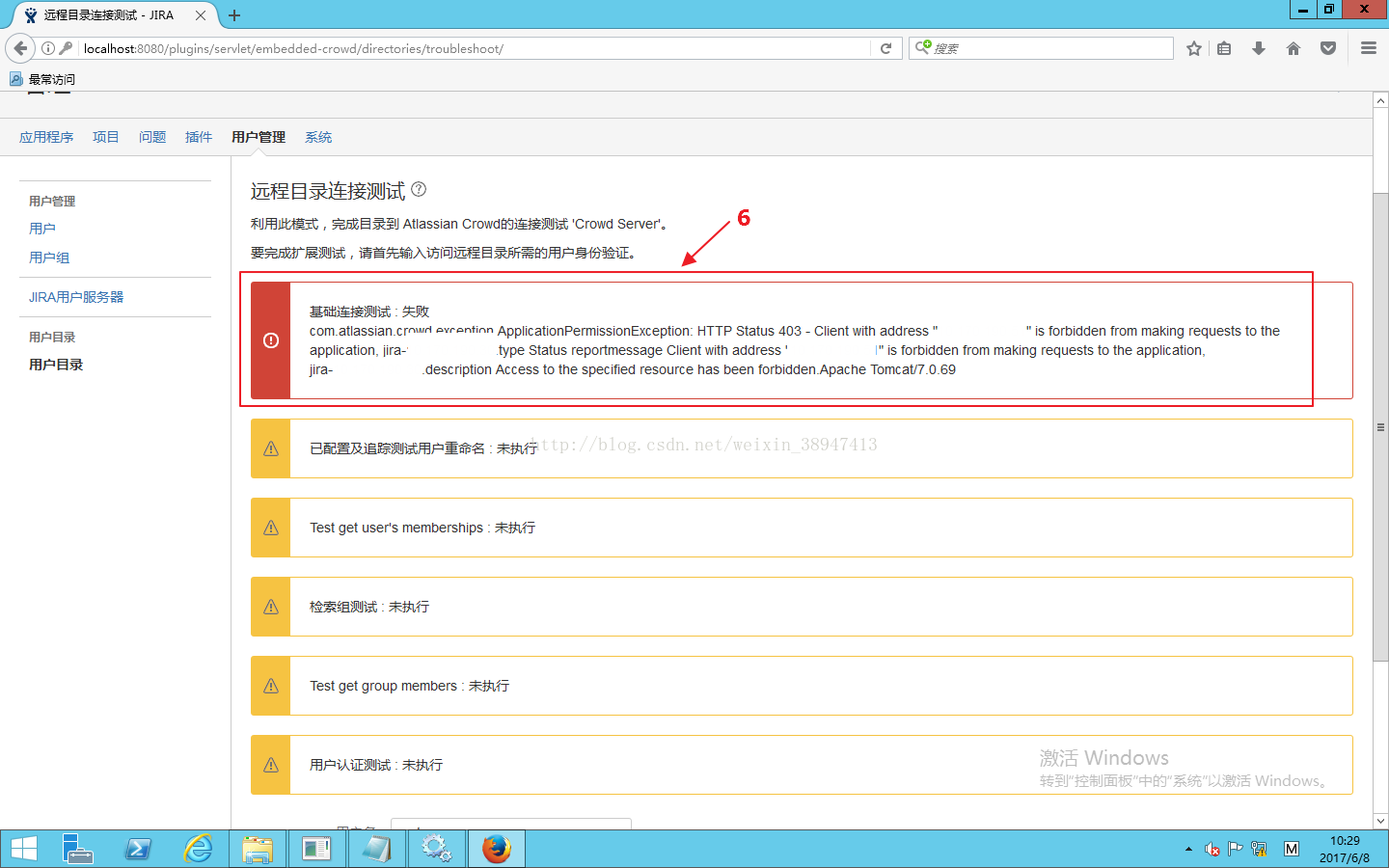
如下图所示,单点登录测试失败,因为服务器地址不匹配。
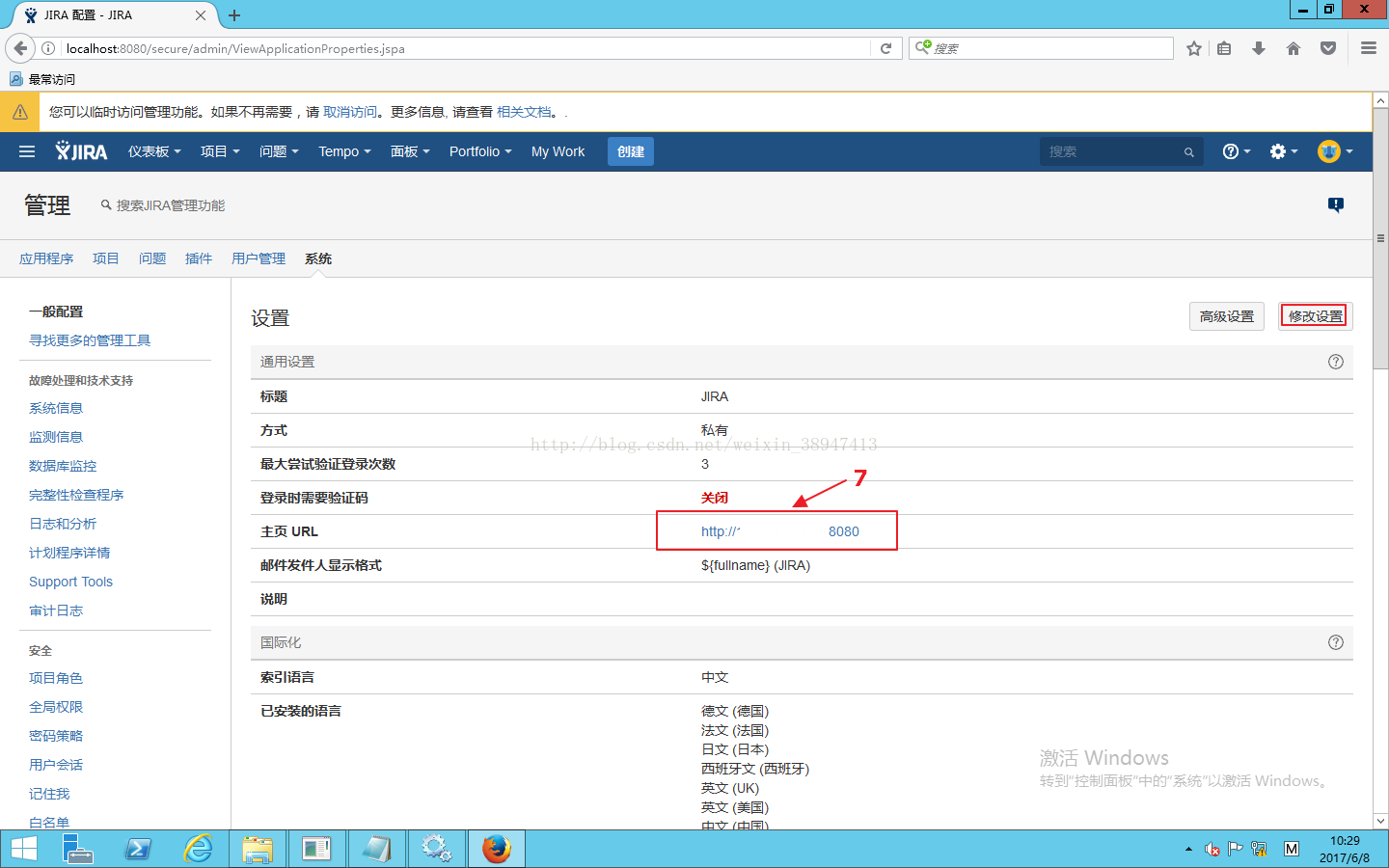
首先先修改系统信息,点击修改设置,将旧服务器IP改成新服务器上的IP
然后在用户管理-用户目录-crowd-编辑,将旧服务器IP改成新服务器上的IP。
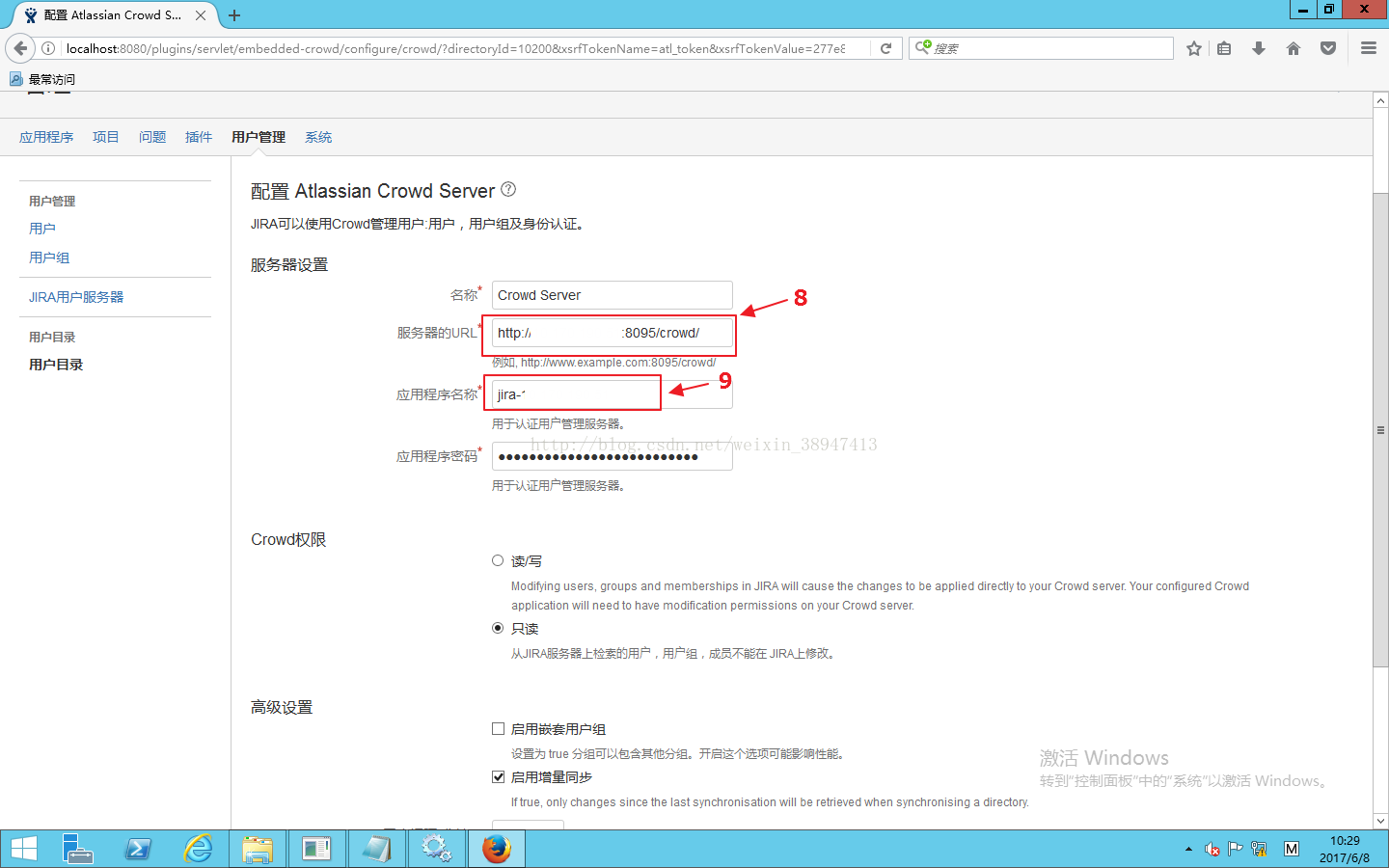
再点击测试,如下图所示测试成功。
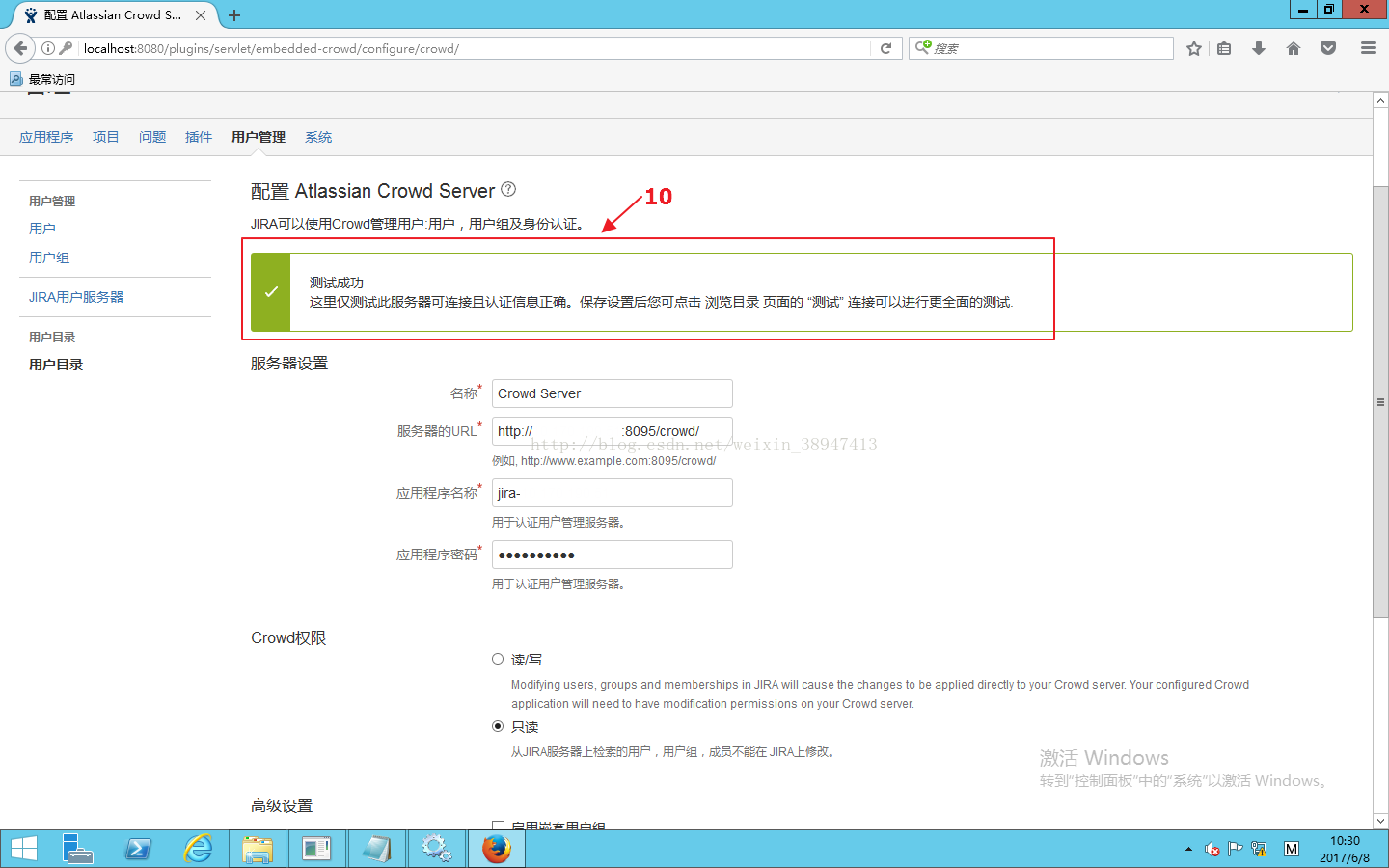
测试成功后,新服务器上所有用户均可成功登录。
注意事项:
(1)单点登录配置可参考官网CROWD。
恢复单个工程
导入单个项目之前,需要准备如下工作:
(1)创建同样的项目名且数据为空;
(2)在项目里配置好相关的自定义字段;
(3)配置同样的工作流;
(4)安装同样的插件;
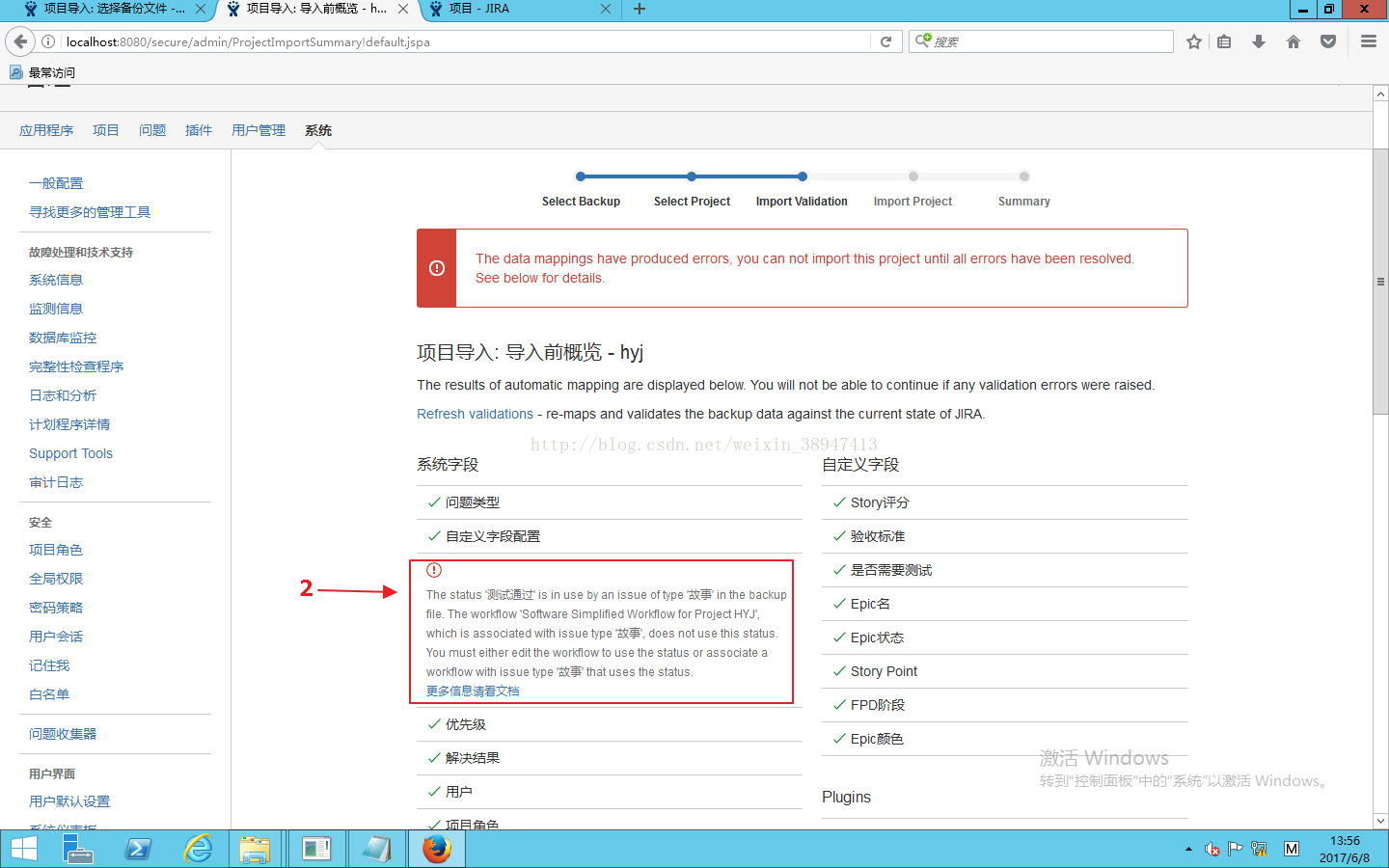
以管理员身份登录,点击管理-系统-项目导入,选择对应的项目。
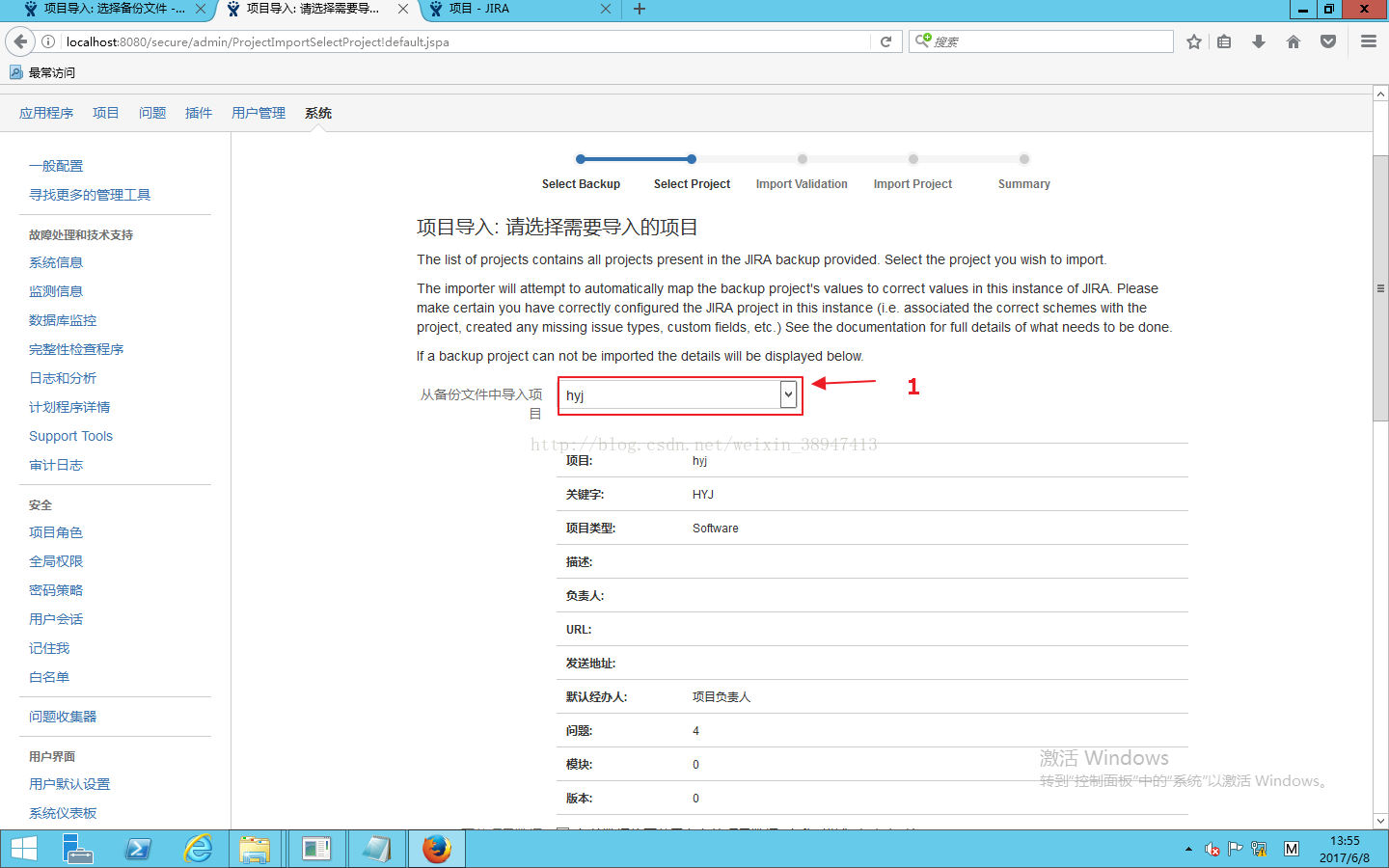
如下图所示,工作流不一致时会映射错误,所以必须配置同样的工作流。
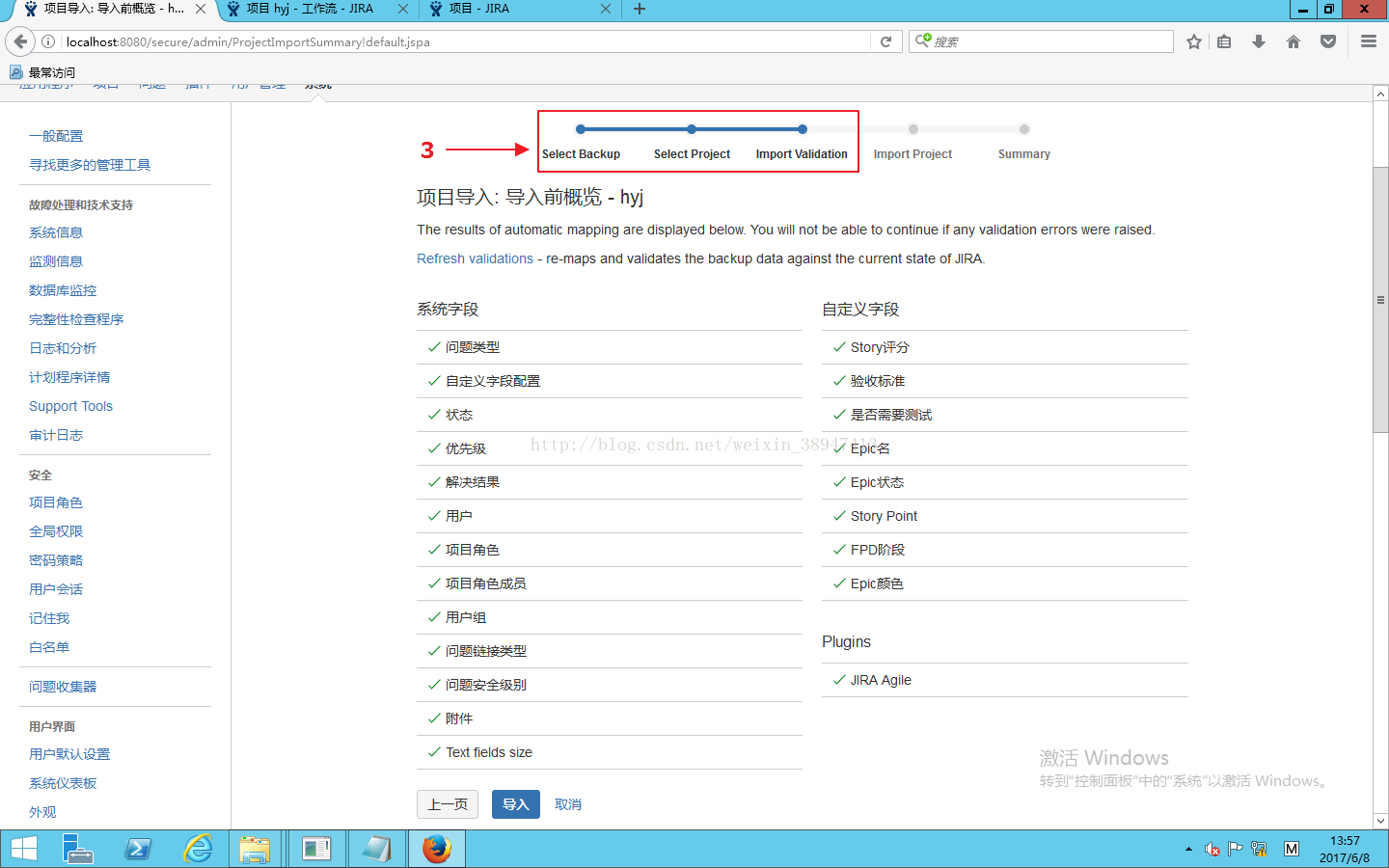
配置相同后,可看到所有字段映射成功,点击导入即可。
单个项目已经导入成功。
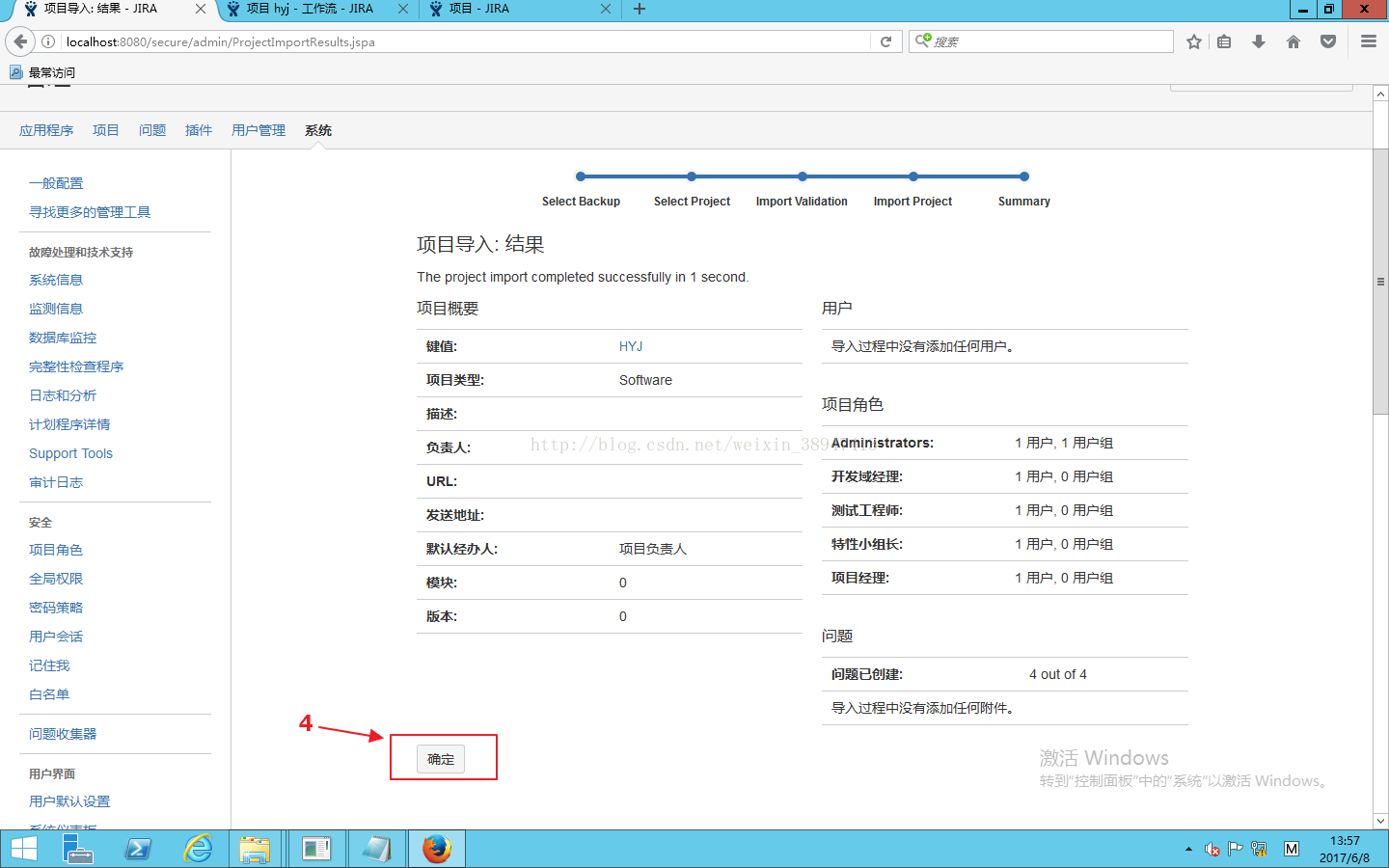
如下图所示,有关的epic和story均已成功导入。
这里需要注意恢复数据将会删除JIRA Software系统现有数据库中的所以数据(包括用户账户信息)。
恢复数据主要步骤如下:
(1)从备份的XML文件中恢复数据;
(2)如果mysql数据恢复异常,则可以运行如下命令,将之前通过mysqldump工具备份的数据库数据进行恢复:
1.2.1 不同版本同一服务器的备份与恢复
温馨提示:为安全起见,先备份旧版本的所有数据及安装文件。
卸载旧版本的JIRA,在服务器上安装新版本的JIRA,配置好所有文件后,以系统管理员的身份登录,选择管理-系统-恢复系统。
系统数据成功导入后具体操作请参考上面1.1.2以系统管理员身份登录后,配置单点登录信息即可。
1.2.2 不同版本不同服务器的备份与恢复
1.2.2.1 恢复整个数据
如官网未说明需要中转版本,只需在新的服务器上安装新版本的JIRA,再以系统管理员身份选择管理-系统-恢复系统,导入旧版本的所有数据即可。
注意事项:
(1)所有插件必须为最新版本才能与新版本的JIRA相匹配。
1.2.2.2 恢复单个工程
强调:不同版本单个工程不能直接导入,会因为版本不同出现构建数字不匹配,如图
必须为同版本的数据才可成功导入,可以在相同版本升级数据后再导入单个工程。
如:7.1.4所有数据恢复到7.3.4版本中,7.1.4数据自然升级为7.3.4版本。
注意事项:项目里所用的插件必须为最新版,不然插件不匹配无法成功导入数据。
1.2.3不同版本同一服务器直接升级
1.在Atlassian-JIRA-bin-shutdown.bat里面关闭旧版本的服务
2.安装所需要的新版本
3.选择在已安装的目录上升级,注:安装之前有关旧版的服务及进程都需要关闭才能保证新版本正常安装。
4.安装过程中,新版本会自动修改部分插件及增加相关插件,如下图所示。
5.点击升级。
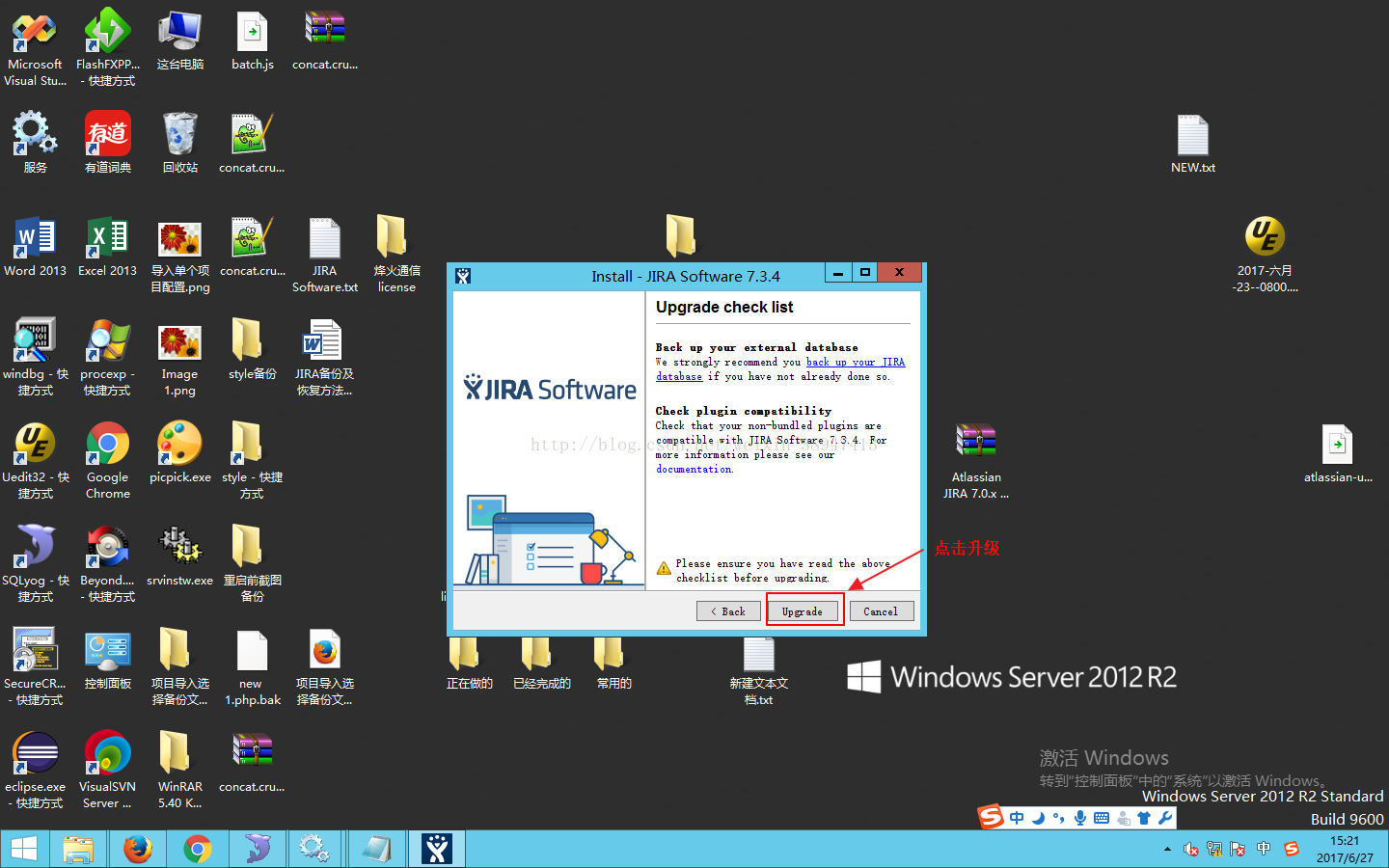
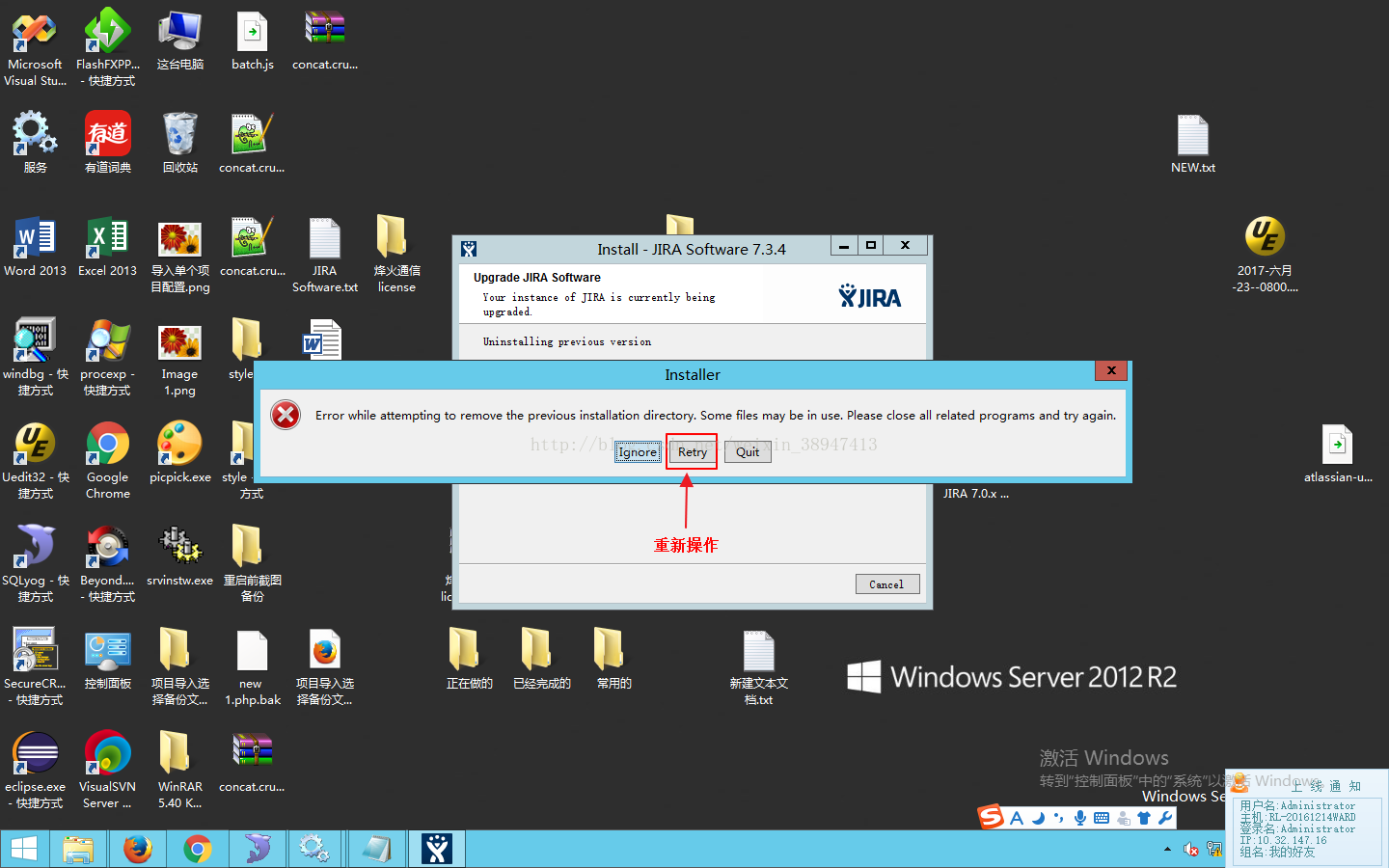
注:如旧版本相关进程未完全关闭的情况下会显示以下提示,当关闭旧版本所有进程后再点击Retry
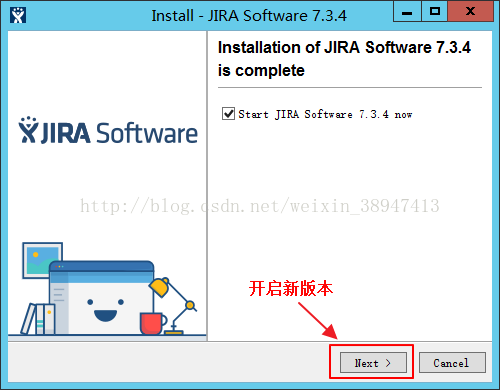
6.升级完成后,会弹出以下窗口。
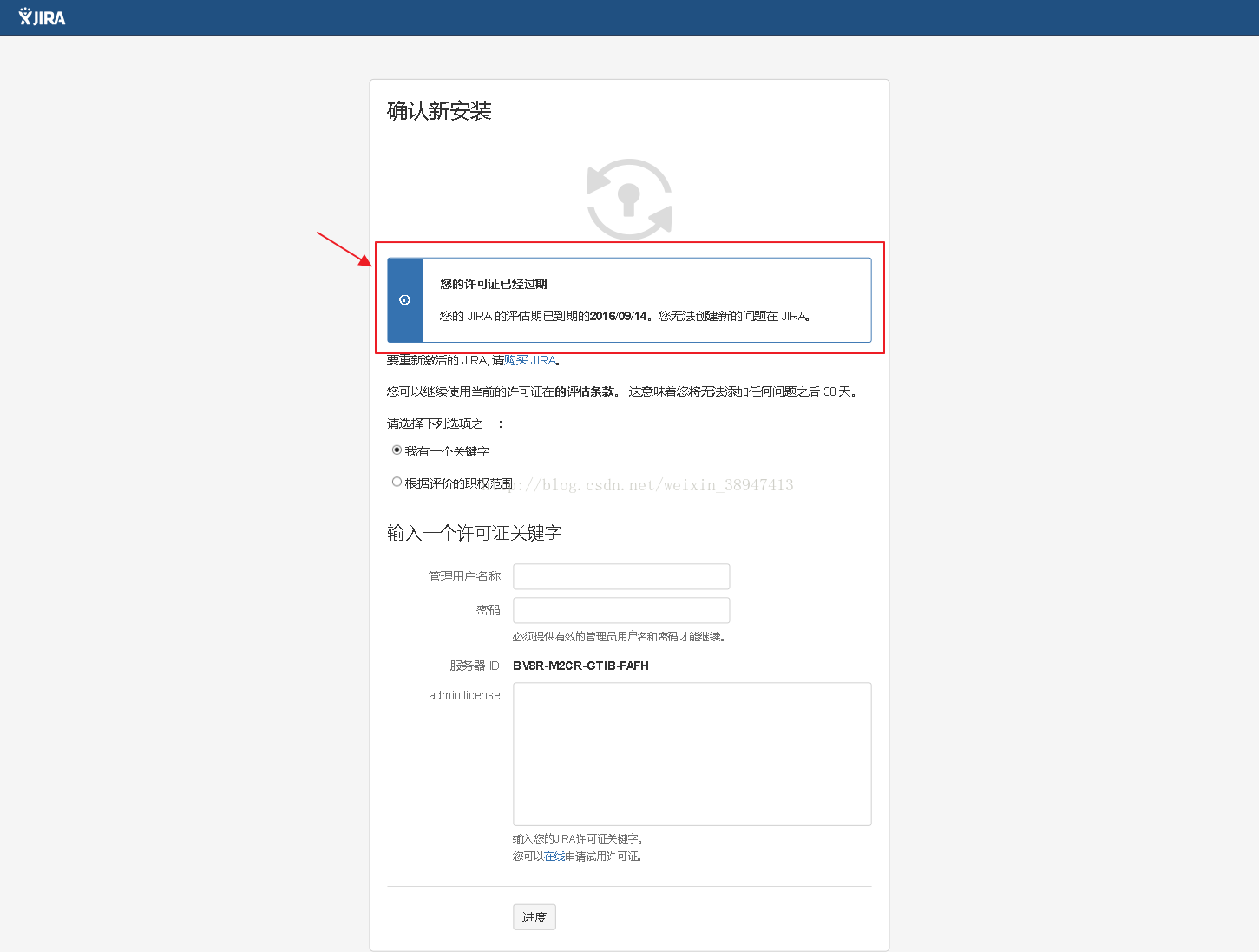
7.开启服务后会看到许可证过期(如下图所示),此时应该关闭服务,将版本及插件的破解包更换再开启服务。
8.升级完毕关闭服务后在Atlassain\JIRA\atlassian-jira\WEB-INF\lib目录下备份atlassian-extra-3.2.jar,再将破解版atlassian-extra-3.1.2.jar包导入目录下,名字改成atlassian-extra-3.2.jar替换原有的即可。
9.升级完成后系统编码格式默认为GBK,此时需要将格式更改为utf-8。修改注册码方式如下:
1、点击Windows系统的“开始”-“运行”,输入regedit32.exe执行,对于32位/64位系统,找到如下入口:
32位: HKEY_LOCAL_MACHINE >>SOFTWARE >> Apache Software Foundation >> Procrun 2.0
64位: HKEY_LOCAL_MACHINE >>SOFTWARE >> Wow6432Node >> Apache Software Foundation >>Procrun 2.0
在Options配置项中增加/确认包含如下数据:
-Dfile.encoding=utf-8
破解包更换后及修改字符编码格式重启服务即可,本地升级完毕!