Deep-Learning-YOLOV4实践:ScaledYOLOv4 数据集制作
Deep-Learning-YOLOV4实践:ScaledYOLOv4环境配置与demo编译运行
Deep-Learning-YOLOV4实践:ScaledYOLOv4模型训练自己的数据集调试问题总结
说明:
硬件:rtx2060
error1: CUDA out of memory
RuntimeError: CUDA out of memory. Tried to allocate 88.00 MiB (GPU 0; 6.00 GiB total capacity; 4.08 GiB already allocated; 22.63 MiB free; 4.20 GiB reserved in total by PyTorch)
原因:
bach_size设置过大
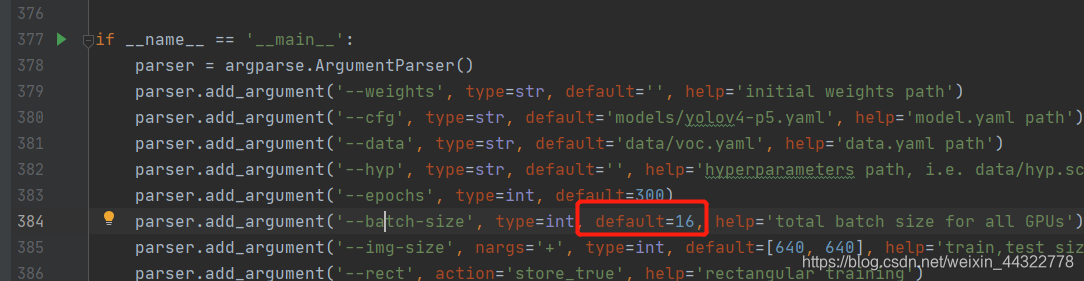
解决办法:
直接将default设置成1:
error2:TypeError: can’t convert cuda:
TypeError: can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
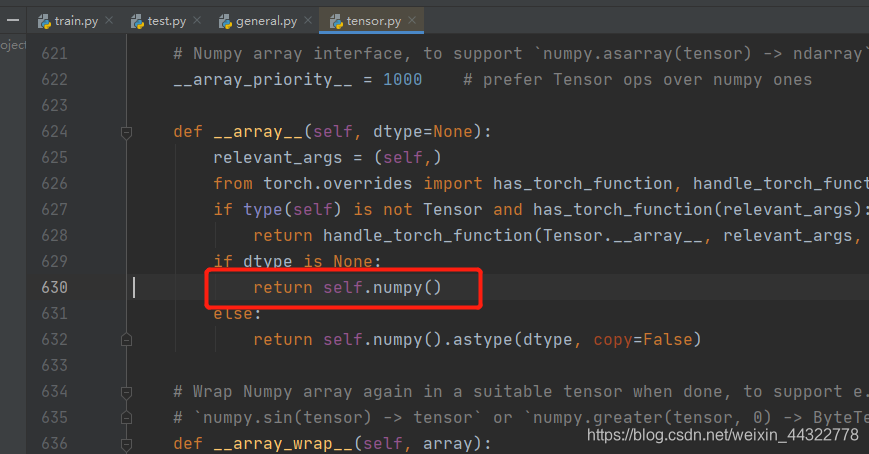
原因:
原来Pytorch代码运行在cpu中,所以这么写实对的。
后来改用GPU中代码运行,因为numpy在cuda中没有这种表达,需要将cuda中的数据转换到cpu中,再去使用numpy。
解决方案: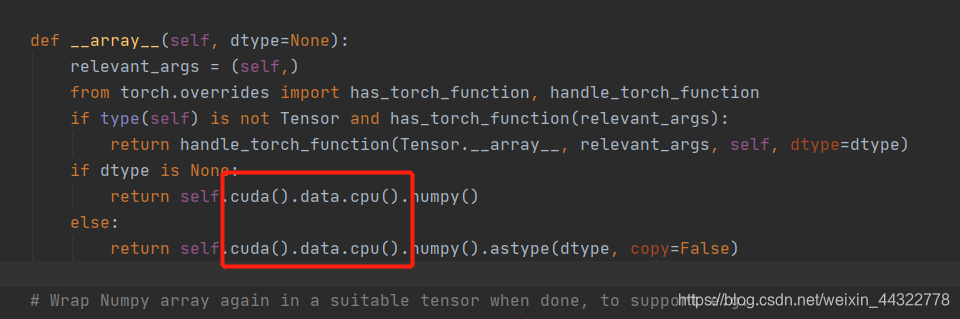 模型自带代码:
模型自带代码:
if dtype is None:
return self.numpy()
else:
return self.numpy().astype(dtype, copy=False)
模型修改之后的代码:
if dtype is None:
return self.cuda().data.cpu().numpy()
else:
return self.cuda().data.cpu().numpy().astype(dtype, copy=False)
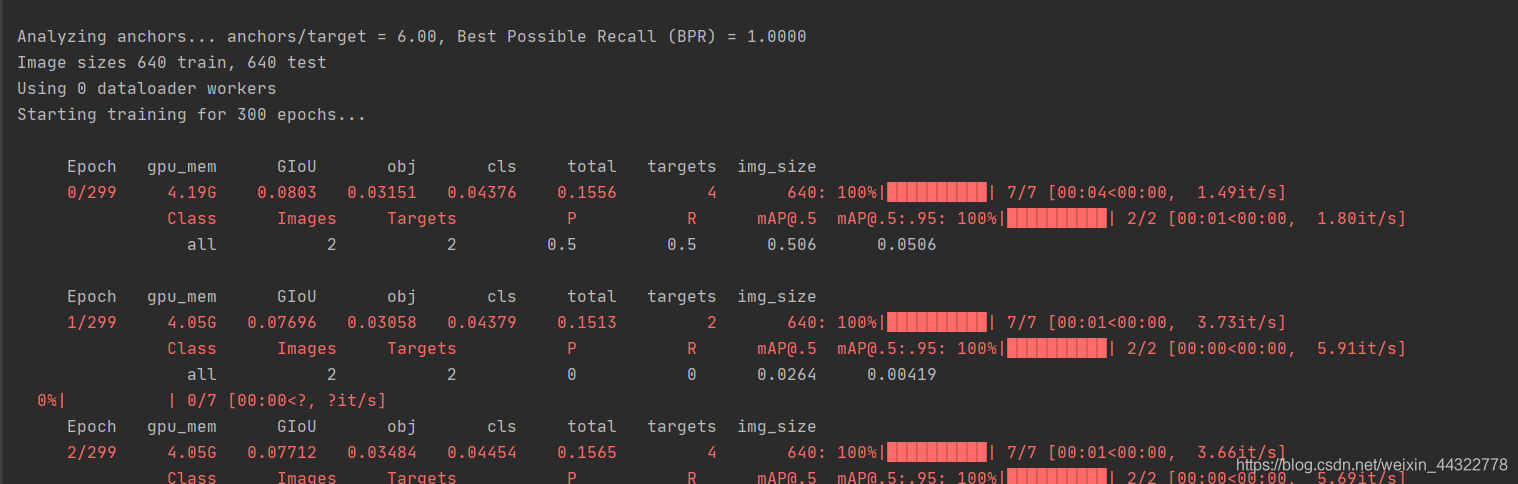
error
【说明】
此错误出现于:ScaledYOLOv4-yolov4-csp改进型模型的训练测试过程
TypeError: not all arguments converted during string formatting
参考链接:
解决方案:将yolov4-csp.cfg中的注释内容去除