名词解释
参见文章cnblogs-什么是SAD,SAE,SATD,SSD,SSE,MAD,MAE,MSD,MSE?
PSNR的计算
较为标准的MSE计算公式和PSNR计算公式如下:
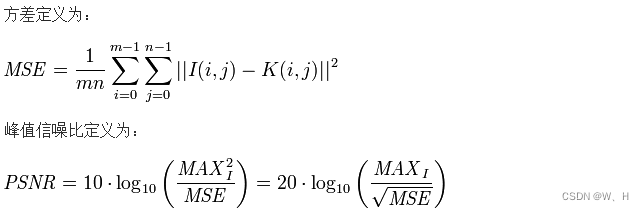
引用链接:CSDN-图像的峰值信噪比(PSNR)的计算方法
这里需要注意的是,PSNR的计算公式中,应该使用的是MAX(更标准),而不是常见的255,因为255是针对8bit的数据。
对于10bit的数据,不同的工具可能有不同的计算方式,大概在
2
10
−
1
2^{10}-1
210−1附近。
VTM中maxval的计算方式如下:
const uint32_t maxval = /*useWPSNR ? (1 << maximumBitDepth) - 1 :*/ 255 << (maximumBitDepth - 8);
// fix with WPSNR: 1023 (4095) instead of 1020 (4080) for bit depth 10 (12)
对应的10bit是
255
∗
4
=
1020
255*4=1020
255∗4=1020
对应的12bit是
255
∗
16
=
=
4080
255*16==4080
255∗16==4080
YUV-PSRN的计算
VTM中YUV-PSNR的计算并不是三个分量通过加权计算得到的,而是对各个分量的MSE进行加权计算得到的,进而计算得到YUV-PSNR。具体的权重计算分析见代码注释
void calculateCombinedValues(const ChromaFormat chFmt, double &PSNRyuv, double &MSEyuv, const BitDepths &bitDepths)
{
MSEyuv = 0;
int scale = 0;
//计算maximumBitDepth
int maximumBitDepth = bitDepths.recon[CHANNEL_TYPE_LUMA];
for (uint32_t channelTypeIndex = 1; channelTypeIndex < MAX_NUM_CHANNEL_TYPE; channelTypeIndex++)
{
if (bitDepths.recon[channelTypeIndex] > maximumBitDepth)
{
maximumBitDepth = bitDepths.recon[channelTypeIndex];
}
}
//计算maxval
#if ENABLE_QPA
const uint32_t maxval = /*useWPSNR ? (1 << maximumBitDepth) - 1 :*/ 255 << (maximumBitDepth - 8); // fix with WPSNR: 1023 (4095) instead of 1020 (4080) for bit depth 10 (12)
#else
const uint32_t maxval = 255 << (maximumBitDepth - 8);
#endif
//计算分量数
const uint32_t numberValidComponents = getNumberValidComponents(chFmt);
//遍历各个分量,计算对应的MSE
for (uint32_t comp=0; comp<numberValidComponents; comp++)
{
const ComponentID compID = ComponentID(comp);
//下面会对函数getComponentScaleX部分单独
const uint32_t csx = getComponentScaleX(compID, chFmt);
const uint32_t csy = getComponentScaleY(compID, chFmt);
const int scaleChan = (4>>(csx+csy)); //权重的计算
//注意8bit和10bit的计算方式不同
const uint32_t bitDepthShift = 2 * (maximumBitDepth - bitDepths.recon[toChannelType(compID)]); //*2 because this is a squared number
//计算分量对应的MSE
const double channelMSE = (m_MSEyuvframe[compID] * double(1 << bitDepthShift)) / double(getNumPic());
//累加权重
scale += scaleChan;
//加权
MSEyuv += scaleChan * channelMSE;
}
//平均
MSEyuv /= double(scale); // i.e. divide by 6 for 4:2:0, 8 for 4:2:2 etc.
//计算YUV
PSNRyuv = (MSEyuv == 0) ? 999.99 : 10.0 * log10((maxval * maxval) / MSEyuv);
}
对于权重的计算函数,参见:
static inline uint32_t getComponentScaleX (const ComponentID id, const ChromaFormat fmt) { return getChannelTypeScaleX(toChannelType(id), fmt); }
static inline uint32_t getComponentScaleY (const ComponentID id, const ChromaFormat fmt) { return getChannelTypeScaleY(toChannelType(id), fmt); }
深入调用
static inline uint32_t getChannelTypeScaleX (const ChannelType id, const ChromaFormat fmt) { return (isLuma(id) || (fmt==CHROMA_444)) ? 0 : 1; }
static inline uint32_t getChannelTypeScaleY (const ChannelType id, const ChromaFormat fmt) { return (isLuma(id) || (fmt!=CHROMA_420)) ? 0 : 1;
计算流程
SSD -> MSE -> PSNR
MSE的计算代码实现:
const uint32_t size = width * height;
MSEyuvframe[comp] = (double)uiSSDtemp / size;
SSD的计算代码实现
const uint64_t uiSSDtemp = xFindDistortionPlane(recPB, orgPB, useWPSNR ? bitDepth : 0, ::getComponentScaleX(compID, format), ::getComponentScaleY(compID, format));
uint64_t EncGOP::xFindDistortionPlane(const CPelBuf& pic0, const CPelBuf& pic1, const uint32_t rshift
#if ENABLE_QPA
, const uint32_t chromaShiftHor /*= 0*/, const uint32_t chromaShiftVer /*= 0*/
#endif
)
{
uint64_t uiTotalDiff;
const Pel* pSrc0 = pic0.bufAt(0, 0);
const Pel* pSrc1 = pic1.bufAt(0, 0);
TCHECK(pic0.width != pic1.width , "Unspecified error");
TCHECK(pic0.height != pic1.height, "Unspecified error");
if( rshift > 0 )
{
#if ENABLE_QPA
const uint32_t BD = rshift; // image bit-depth
if (BD >= 8)
{
const uint32_t W = pic0.width; // image width
const uint32_t H = pic0.height; // image height
const double R = double(W * H) / (1920.0 * 1080.0);
const uint32_t B = Clip3<uint32_t>(0, 128 >> chromaShiftVer, 4 * uint32_t(16.0 * sqrt(R) + 0.5)); // WPSNR block size in integer multiple of 4 (for SIMD, = 64 at full-HD)
uint32_t x, y;
if (B < 4) // image is too small to use WPSNR, resort to traditional PSNR
{
uiTotalDiff = 0;
for (y = 0; y < H; y++)
{
for (x = 0; x < W; x++)
{
const int64_t iDiff = (int64_t)pSrc0[x] - (int64_t)pSrc1[x];
uiTotalDiff += uint64_t(iDiff * iDiff);
}
pSrc0 += pic0.stride;
pSrc1 += pic1.stride;
}
return uiTotalDiff;
}
double wmse = 0.0, sumAct = 0.0; // compute activity normalized SNR value
for (y = 0; y < H; y += B)
{
for (x = 0; x < W; x += B)
{
wmse += calcWeightedSquaredError(pic1, pic0,
sumAct, BD,
W, H,
x, y,
B, B);
}
}
// integer weighted distortion
sumAct = 16.0 * sqrt ((3840.0 * 2160.0) / double((W << chromaShiftHor) * (H << chromaShiftVer))) * double(1 << BD);
return (wmse <= 0.0) ? 0 : uint64_t(wmse * pow(sumAct, BETA) + 0.5);
}
#endif // ENABLE_QPA
uiTotalDiff = 0;
for (int y = 0; y < pic0.height; y++)
{
for (int x = 0; x < pic0.width; x++)
{
Intermediate_Int iTemp = pSrc0[x] - pSrc1[x];
uiTotalDiff += uint64_t((iTemp * iTemp) >> rshift);
}
pSrc0 += pic0.stride;
pSrc1 += pic1.stride;
}
}
else
{
uiTotalDiff = 0;
for (int y = 0; y < pic0.height; y++)
{
for (int x = 0; x < pic0.width; x++)
{
Intermediate_Int iTemp = pSrc0[x] - pSrc1[x];
uiTotalDiff += uint64_t(iTemp * iTemp);
}
pSrc0 += pic0.stride;
pSrc1 += pic1.stride;
}
}
return uiTotalDiff;
}