在 GPU 上使用 Video Codec SDK,CV-CUDA 和 TensorRT 加速现代云上视频应用
本文视频来源为NVIDIA GTC大会详细链接如下:https://register.nvidia.cn/flow/nvidia/gtcspring2023/registrationcn/page/sessioncatalog/session/1666233352698001A01c
前言
人工智能技术广泛应用于云和 on-prem 数据中心的短视频和直播应用当中,覆盖了超分辨率,直播视频特效,旧视频修复,自动像素化,视频内容理解等。然而,当部署这些应用程序时,传统视频处理管线混合了 CPU 和 GPU 负载,其性能将受到以下因素的限制: 1) h2d 和 d2h 内存拷贝,2) CPU 上的前处理和后处理,3) CPU 上的视频编解码,4) 未充分优化的 AI 推理框架。
针对以上限制, NVIDIA 提供了丰富的视频处理相关的 SDK,例如用于视频编解码的 Video Codec SDK,用于图像前处理/后处理的 CV-CUDA,以及用于加速 DL 模型推理的 TensorRT。如何在实践中高效地在云上使用这些工具是搭建基于人工智能的新式视频处理管线的关键。
基于现代AI的视频流水线架构与运用场景
常用的视频处理流水线包括以下几个部分:1.视频编解码器
。2.图像前后处理。3.AI智能分析模块。如下图所示: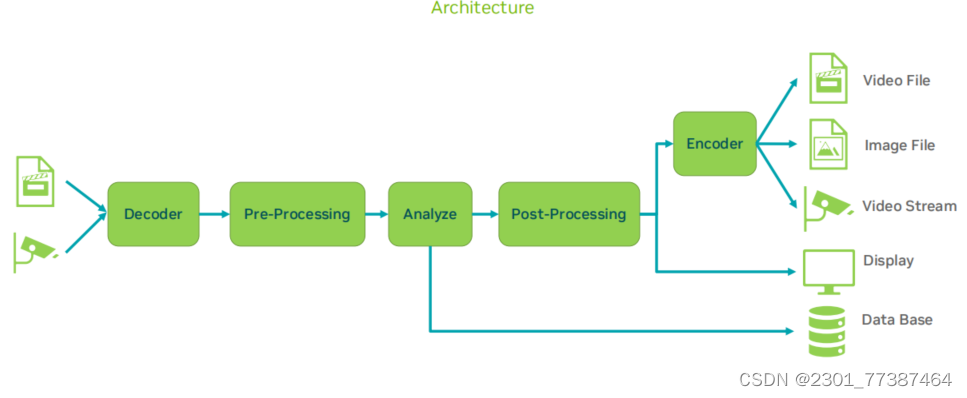
由于在此架构中存在GPU与CPU的数据拷贝以及没有使用加速会使流水线GPU的利用率不高
NVIDIA 视频处理的工具集
针对这个问题NVIDA提供了全流程的视频处理流水线工具集。
1.视频编解码工具
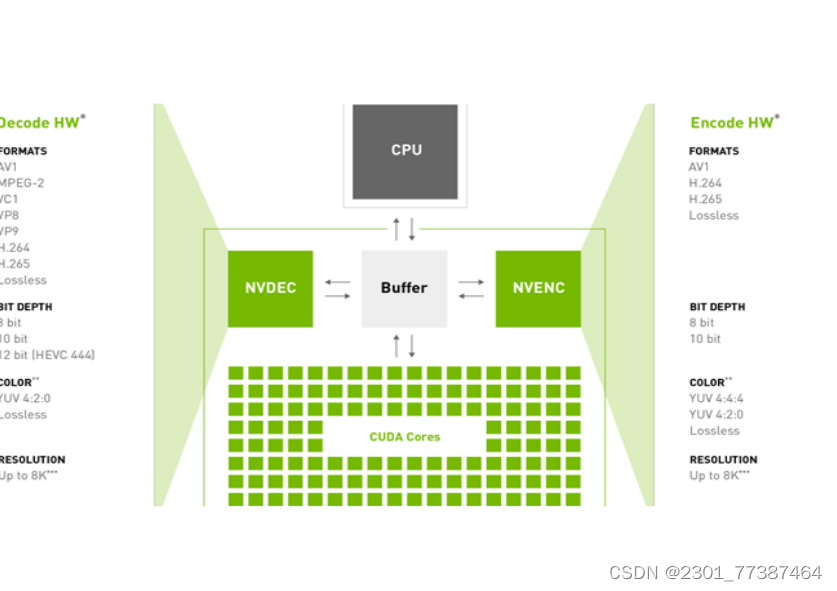
支持多种编码格式和色彩格式,应届编解码器与GPU上的CUDA Cores共享内存,减少大部分拷贝操作。与CUDA配合可以实现高效性能。并且支持Python API
2.前后处理部分-CV-CUDA
CV-CUDA是一个开源图像处理库,采用独立算子设置。
不仅支持相同分辨率的图像保存连续的显存,也可以支持,非连续显存保存不同分辨率的图像。与Python和C++,C的API,结果保证与OPencv对齐,也可以与Pytorch和TensorRT进行对接。
下面我们就来看一下CV-CUDA与Ope的对比效果:

可以看出Opencv无论是在CPU和GPU上性能都不及CV-CUDA
3.智能分析部分
NVIDAI提供了TensorRT
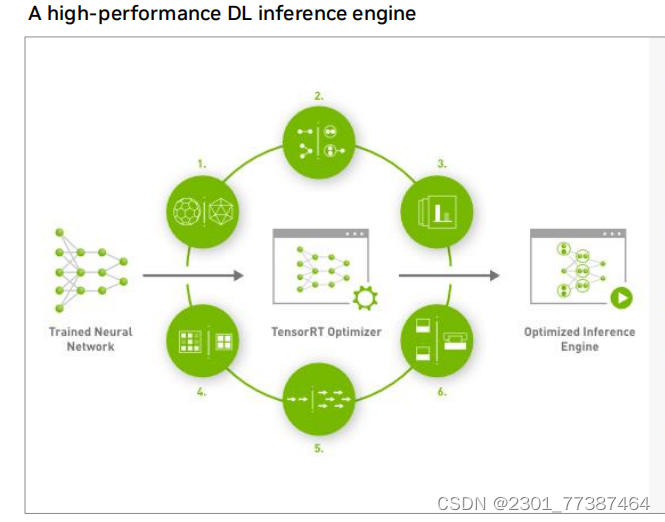
TensorRT推理引擎是目前在工业上应用最广泛的ai部署工具,支持多种训练框架训练的模型,并进行模型转化。在转化过程中TensorRT可以进行量化,算子融合,以及正对硬件自动优化,获得最佳精度性能和最少的精度衰减。
4.Decinfer
Decinfe可以最大化GPU利用率,充分利用GPU利用率.下图为Decinfer架构
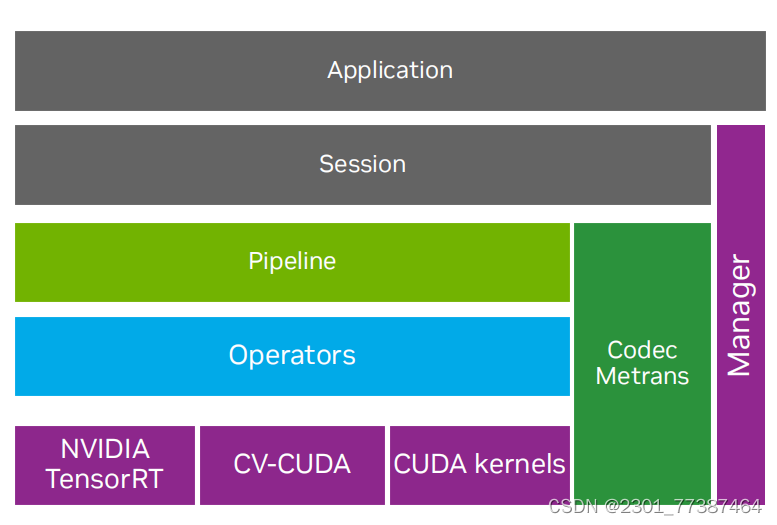
全GPU视频加速流水线的最佳实践
使用Decinfe可以将所有的算子迁移到GPU上,充分利用了GPU硬件加速和解码功能,以及高性能处理框架。
以下是使用Decinfe的demo的效果图:

Decinfe采用多线程并行和异步流并行,最大化利用GPU的硬件资源。
在没有并行时候系统的优化空间
如下图所示:
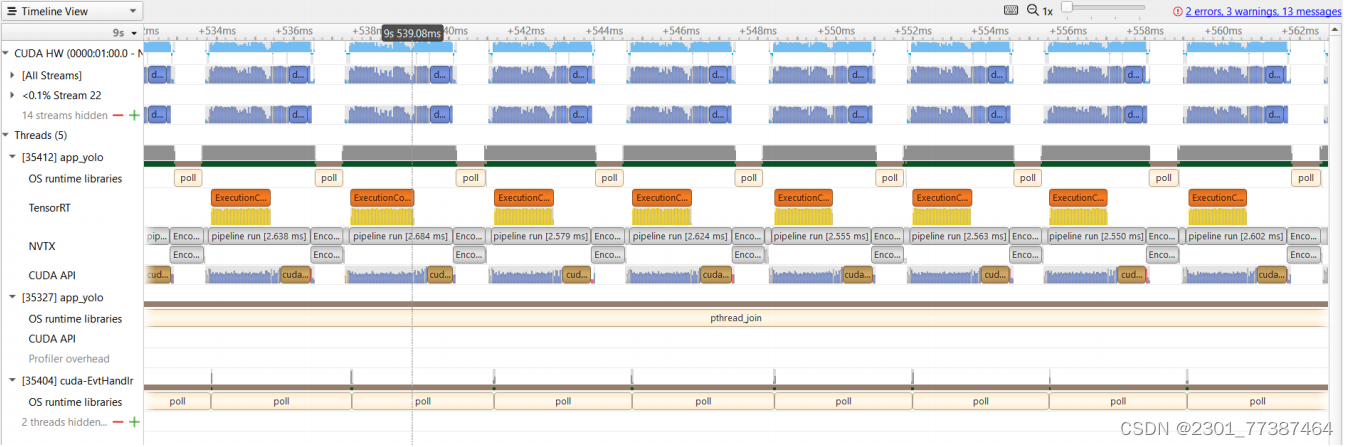
TensorRT为橙色,通过图可以看出,优化空间就是图中的空洞。
Decinfe采用多线程来进行优化:

优化效果时间轴:

可以看出GPU占用率还有空闲
于是Decinfe采用异步流并行技术,详细如下图:
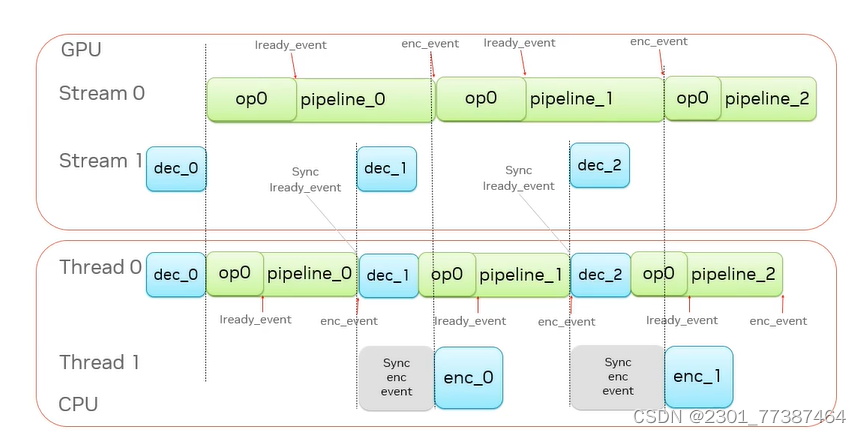
进过优化后的时序图:
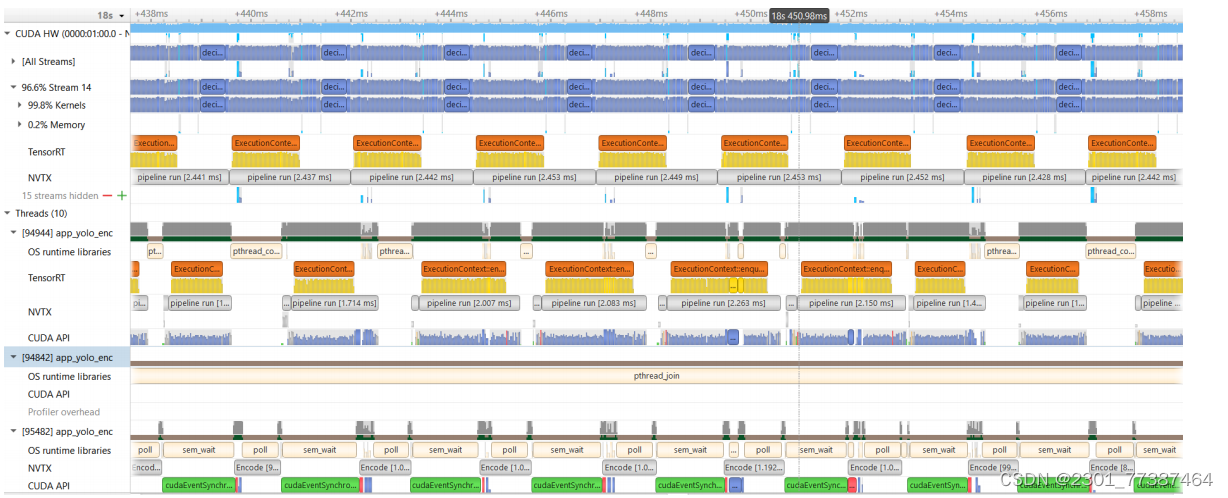
可以看出CUDA已经全部占满,GPU也全部占满。性能比串行流水线高了1.2倍。