这里所说的程序是指对外提供tcp/ip交互协议的服务性程序。网络程序性能分析很重要,比如随着网络请求流量越来越大,我们需要知道已部署的服务能不能满足需求。这里采用对网络服务程序进行建模的方法分析影响程序性能的各要素,并计算相关性能值,它不够精确,但对我们使用其它工具对网络程序进行性能测试提供很好的理论指导。
1.网络请求
![]()
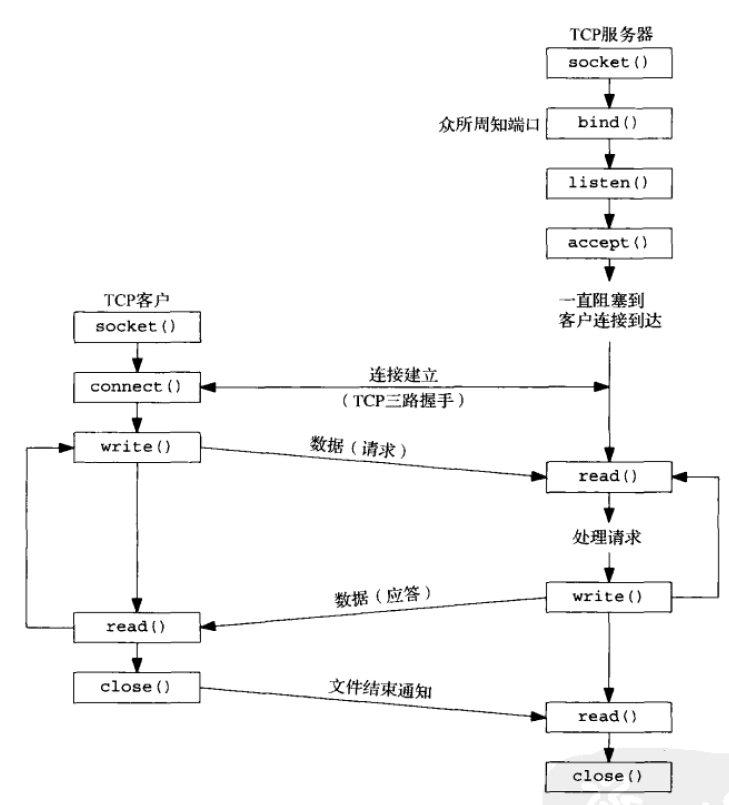
图1
什么是网络请求?如图1是《UNIX 网络编程》一书中表示网络交互过程的一幅图,整个请求是指从客户端到服务端 write->read->write->read的一个过程。对于服务端需要关心的是read-处理-write的过程。
connect相关操作在此是忽略的,因为其对服务端性能并没有什么影响。
一个请求中,在服务端read可能进行多次,如http协议中,我们可能先要读取头部信息,然后再读取一次数据实体,对于一个请求更为精确的定义是:
把相邻的操作都合并,如多次连续read合并为一个,从一个read开始到下一个read开始的过程即为一个请求。
在一个长连接里就可以发生多个请求,因为有多个read-处理-write过程
服务端的请求处理过程总结如下:
1.从网络接口读取数据
2.处理请求
3.将处理结果发送至网络接口
2.性能指标
这里参考<<High Performance MySQL>> 一书 38页对于相关性能值的解释说明,本人即看此书看到这里时想到要写本文。
吞吐量:每秒处理的请求数(事务数),请求定义见上节
响应时间(延迟):请求处理响应时间,对于服务端来说即一个read-处理-write流程的时间。下面会使用响应时间和延迟两种说法,意义一样。
并发度:某一刻处于请求处理过程的请求数。如图2所示,不同请求处于不同的处理过程,竖着的红线表示当前时刻的时间线,与时间线相交的请求数目即为并发度。
可伸缩性:作者的意思应该是别把系统的所有资源用到极限,要留有一定余地,以使整个系统具有可伸缩性,预防可能突然增大的请求流量。接下来的性能值计算都以极限值为标准,但实际使用过程中,不能让服务的性能值处于极限值上。
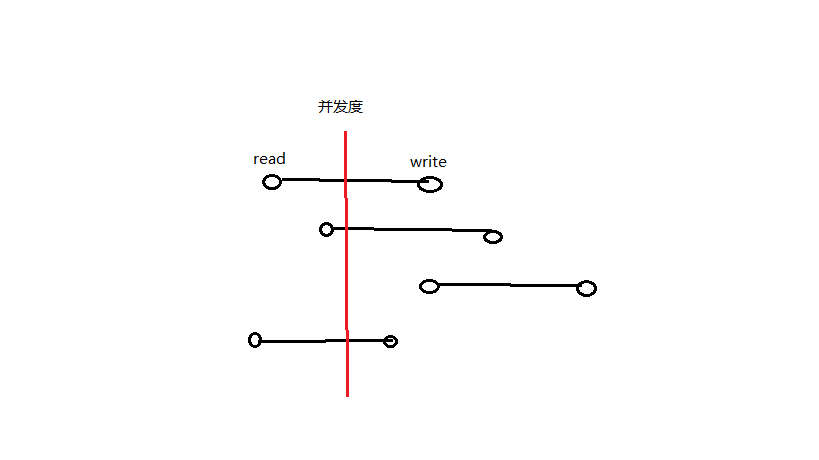
图2
3.性能函数表达式
吞吐量 = f1(CPU能力,CPU个数,磁盘IO能力,网络带宽能力,请求处理模型,网络流量,CPU计算时间,磁盘IO量,进程数)
响应时间 = f2(CPU能力,CPU个数,磁盘IO能力,网络带宽能力,请求处理模型,网络流量,CPU计算时间,磁盘IO量)
并发度 = f3(客户请求量,请求处理模型, 吞吐量,响应时间)
红色:正相关
绿色:负相关
硬件变量: CPU能力,CPU个数,磁盘IO能力,网络带宽能力(难以控制)
软件变量:请求处理模型,网络流量,CPU计算时间,磁盘IO量(控制难度中等)
参数变量:进程数,系统软件参数(较易控制)
对于任一单一变量来说,在其它变量值固定的情况下,它都有一个最大(小)值,超过这个最大(小)值,性能计算指示的值不随它的值变大(小)而变化,这是其它某个变量达到了瓶颈值,例如I/O能力有限的情况下,再怎么提高进程数对吞吐量也没用,我们将这种情况称为软限制。另外一些变量有一些限制值,该变量的值不可能超过该值,比如同时运行的进程数受限于CPU的个数,我们将这种情况称为硬限制。软限制由硬限制引起,当然对于某一组变量来说不存在如上限制的情况。
网络延时及连接队列长度不会影响性能量度,因为这两个变量从逻辑上讲跟网络服务程序的处理过程无关。网络延时是请求开始及完成后中间的信息传输过程,连接队列只是请求正式开始前一个暂存的机制。
4.硬件建模
相关硬件一个时刻只能给一个进程使用,除非有多个硬件设计如CPU才能实现同一时刻的并发,资源不够时需要等待。
CPU:每一个进程顺序执行指令,多个CPU可以并发。CPU使用率达到100%,进程可能有等待。
磁盘I/O : 多个进程I/O需要进行排队。假设需要的时间只根据读取或写入的数据量有关,不考虑寻道时间等。有可能出现IO等待
网络I/O: 多个进程I/O需要进行排队,也假设网络I/O的时间只跟要读取或发送的数据量有关。有可能出现IO等待
内存: 对于性能影响较小,往往只是作为磁盘的缓存来使用,加速磁盘I/O,对性能分析无益,可以忽略。
| 硬件 |
能力值 |
单位 |
| CPU |
H1 |
指令/s |
| CPU个数 |
N1 |
个 |
| 磁盘I/O |
H2 |
K/s |
| 网络带宽 |
H3 |
K/s |
5.软件数据
对于每一个请求来说,相关数据量如下:
| 请求 |
值 |
单位 |
| 执行指令数 |
S1 |
个 |
| 磁盘I/O量 |
S2 |
K |
| 网络I/O量 |
S3 |
K |
6.请求处理模型
最普通的请求模型是,每个进程从队列取得连接,然后等待读取数据,然后执行CPU计算,然后进行I/O处理,然后写回数据,CPU计算与磁盘I/O往往是交叉进行,不过将其统一成两个不两阶段,不影响性能值计算,另外网络的读写也合并在一起。
各执行阶段可用图表示如下:
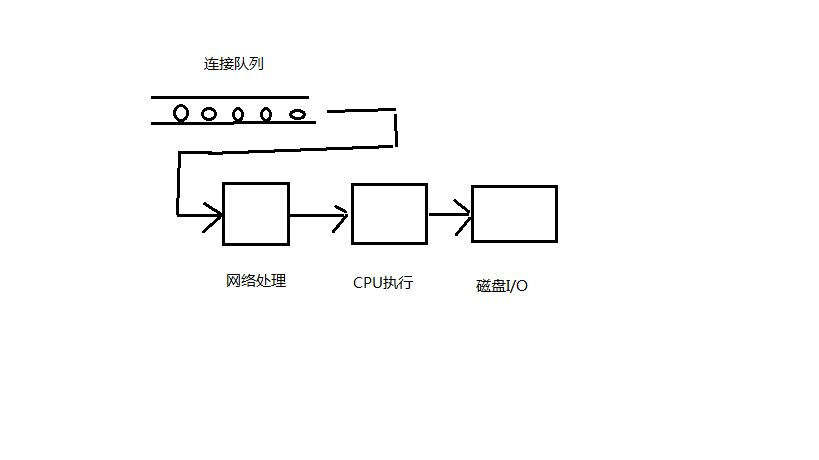
图3
我们还有一些基本假设:
1.连接队列总有有可以读取的连接,即让客户端请求的吞吐量大于或等于服务端的吞吐量,以测试服务端的极限性能,让客户端的请求不至于成为瓶颈。
2.每个请求都是完全相同的,这是为了简化性能计算,并且不影响分析结果。
3.从连接列表获取连接后,马上进行读数据,读取时间只跟网络整体带宽有关。
7.如何计算并发度
基本计算规则: 根据并发度的定义,以其中一个请求为标准,并发度即该请求从开始到结束期间,从连接队列新拿到的连接数(只要离开了连接队列,我们就认为其进入了read-write处理中,跟上述假设3是吻合的)。抽象成公式如下:
并发度 = 请求处理时间*吞吐量
再以图形描述下上面的公式。如下图,横线的表示一个请求处理过程,长度为处理时间,假设A点表示处理起始点,B点是结束点,随着时间进行,所有横线以一定速度往右行走,左结点穿过B线表示相应请求完成,那横线左结点穿过B竖线的速度即为吞吐量,再假设吞吐量在处理各阶段保持不变,那横线进入A竖线的速度也应该等于吞吐量,于是一个请求的时间内进入A竖线的请求数为 :请求处理时间*吞吐量
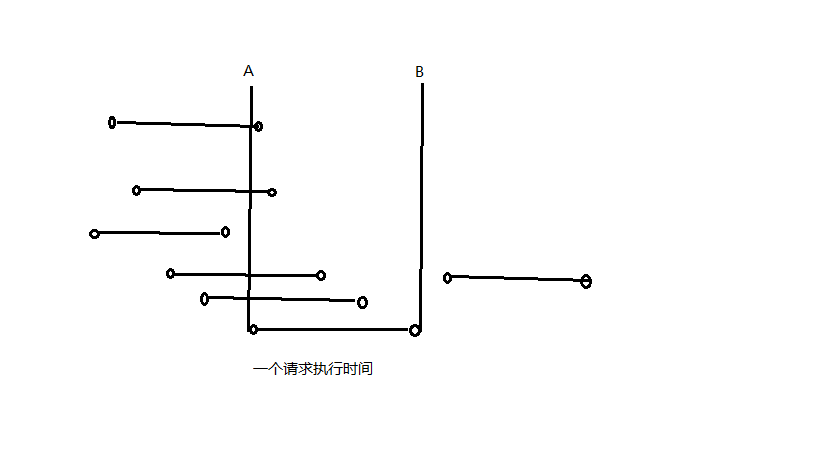
图 4
但如果各个处理阶段吞吐量不同的话,吞吐量取最大值,更精确的公式如下:
并发度 = 请求处理时间* max(吞吐量1,吞吐量2…吞吐量n)
8.如何计算进程数
基本计算规则: 类似于并发度的计算规则,对于同一处理类型的进程来说,以某一个进程为标准,从开始到结束期间,新进入的需要处理的事件即需要的进程数。如果对一个请求有不同类型的处理阶段,且由不同进程处理,所需要的进程数是不同阶段进程数相加:
进程数 = 阶段1处理时间*阶段1吞吐量+阶段2处理时间*阶段2吞吐量+…阶段n处理时间*阶段n吞吐量
如果一个请求完全由一个进程处理,即两者完全绑定,则: 进程数 = 并发度
9.如何计算延时
延时是不同处理阶段延时的相加,如之前所述的三个阶段:
请求总的耗时 = 网络耗时+CPU执行耗时+磁盘I/O耗时
网络耗时: 根据网络距离、数据传播速度计算网络耗时在这里显得没有意义,我们只想得出各变量之间的关系,所以我们定义单位带宽单位数据量的耗时为X,可以得出网络耗时为 X*S3/H3
这里有个前提是接入带宽越高,同一请求的数据传播也越快,事实上这也跟整个网络的带宽有关。
CPU执行耗时: 即使有多个CPU,也不能对同一个请求进行并发处理,所以执行耗时为 S1/H1
磁盘I/O执行耗时: 在没有等待情况下的耗时为 S2/H2
10.如何计算吞吐量
基本计算规则:一个请求各个处理阶段吞吐量的最小值,实际就是系统处理瓶颈决定整个的吞吐量。
吞吐量 = min(网络吞吐量,CPU吞吐量,磁盘I/O吞吐量)
各阶段吞吐量计算如下:
网络吞吐量: H3/S3
CPU吞吐量: N1*H1/S1
磁盘I/O吞吐量: H2/S2
11.性能值具体的计算
我们根据之前的规则计算各性能值
吞吐量:
请求处理分为多个过程,整理处理的能力跟最小处理过程有关,这是请求的处理瓶颈所在,如图5所示,即
吞吐量 = min(H3/S3,N1*H1/S1,H2/S2)
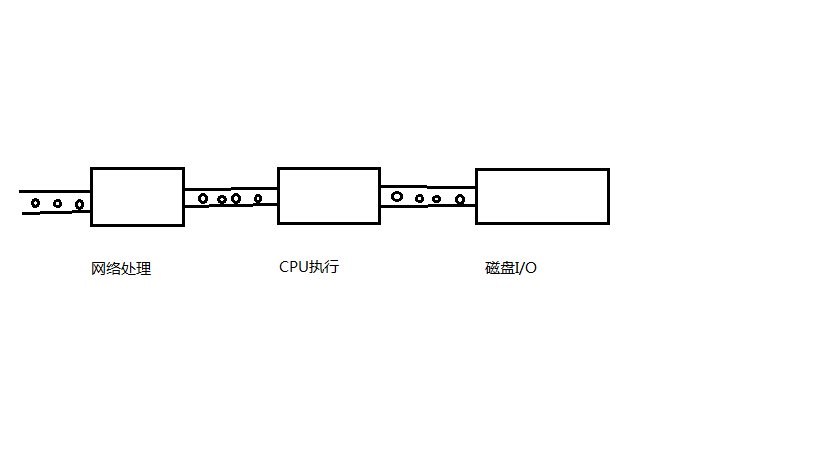
图5
延时:
设网络处理与CPU执行之间的队列为Q1,CPU执行与磁盘I/O之间的队列为Q2
分两种情况分析,第一种请求到达的速率小于等于吞吐量,这时内部的队列中应该是没有累积数据的,队列Q1,Q2保持为空。将各阶段耗时相加即为:
延时 = X*S3/H3+S1/H1+S2/H2
我们定义这种待处理队列为空的状态为H-S-E状态,而有积累数据直到队列满的状态为H-S-F状态,当请求到达速度大于吞吐量时即可到达H-S-F状态。H-S-F状态下的延迟计算如下:
假设Q1的长度为L1,Q2的长度为L2,单个请求的延迟相对于H-S-E状态的延迟只是多了队列中等待的时间,计算出它即可,我们假设H3/S3 > N1*H1/S1 > H2/S2,当前一个处理阶段吞吐量大于后一个时,队列中才可能积累数据。
队列等待时间 = Y*L1*(S1/H1)+ L2*(S2/H2)
H-S-F下的延迟 =X*S3/H3+S1/H1+S2/H2+ L1*(S1/H1)+L2*(S2/H2)
队列长度越大,延迟越大,在请求速度没有控制的情况下,请求的延迟将会变得巨大。
需要注意的是,CPU运算对各进程的调度是按时间片来分的,并不是等一个进程完全执行完再执行另一个,这可以防止进程饥饿,并且将等待时间平摊,所以我们计算的CPU等待时间要加个计算系数,即Y*L1(S1/H1)。
并发度:
根据并发度的定义,在队列中的请求都算是正在处理中请求。根据计算规则,为处理时间乘以吞吐量,H-S-E的并发度为
min(H3/S3,N1*H1/S1,H2/S2)* (X*S3/H3+S1/H1+S2/H2)
H-S-F的并发度为:
min(H3/S3,N1*H1/S1,H2/S2)*(X*S3/H3+S1/H1+S2/H2+L1*(S1/H1)+L2*(S2/H2))
在H-S-E状态下,随着请求速度提高,并发度同时提高,而处理延迟并不会增加,而一旦到了H-S-F状态,并发度升高会导致严重的请求延迟增加,往往这是一个很坏的状态。
进程数
假设一个请求跟一个进程是绑定的,即一个进程只有在处理完一个请求后才会处理另一外,所以所需要的进程数跟并发度是相等。当然可能还有一些其它特殊功能的进程,往往较少,可以忽略。
如之前所述,为了防止进程饥饿,CPU调度进程采用时间片法,每个进程轮流一个小的时间片,这就涉及到进程切换,在CPU计算密集型请求中,这个切换也是一个较大开销,所以启动并发度数目的进程CPU执行的吞吐量达不到N1*H1/S1,我们应该要将进程数减少到一个适当的程度以获得最大吞吐量,这个只能通过实际测量获得最佳进程数。
以上情况说明对进程数的控制很重要,不能无限制随着请求数目增加进程,这会导致系统吞吐量下降以及延迟的增加,apache的模型类似这种,所以在极端情况下它的性能并不高。
之前讨论的H-S-F状态下,Q1,Q2队列可能会满,实际上我们可以在应用层增加一个队列,让Q1,Q2保持为空的状态,从连接队列获取连接后,将其放进这个队列,然后启动固定数目的进程从该队列中获取读或写事件进行处理。将队列从操作系统内核移至应用层的队列,不但有更大的控制灵活性,如控制队列长度,也能够很好控制启动的进程数目,在这种情况下,我们也能保证所有事件都能得到处理。
当然,将队列由应用层实现,并不会提高系统整理吞吐量以及延迟,只是更方便控制了。那队列设置多长合适呢?一般来说处理延迟不应该超过客户端的超时时间,设队列长度为L,超时时间为T,由此可得出如下式子:
L*( X*S3/H3+S1/H1+S2/H2) < T
L < T*(X*S3/H3+S1/H1+S2/H2)
12.请求处理模型优化
公平对待等待中的连接,优化应用层队列
在之前的性能计算中,我们提到增加应用层队列,以实现对进程数的控制,但实际上与我们之前的一个假设有冲突,将连接从队列中拿出来后放到另一个队列,这样这个连接并不能立即进行读数据的操作,我们可以优化一下,所有进入这个队列的连接都可以立即进行读数据的操作,这并不是平常我们所说的 “队列”了,是一种特殊的数据结构,我们往往通过系统调用select或epoll 来实现,所以拿到的连接都可以进行数据操作,这实现了一种事件驱动的模式,这种模式一定程序减少了应用层队列等待时间,它避免了前一个连接因传输慢而导致后一个连接不能传输数据的情况,当然因为我们的进程数因为是控制在一定数量的,仍然可能会有“队列”等待的情况,延迟值计算跟之前是一样的。
这种“队列”,更像一种竖着的队列,进入队列中的连接都可以进行接下来的处理流程,如图6所示。
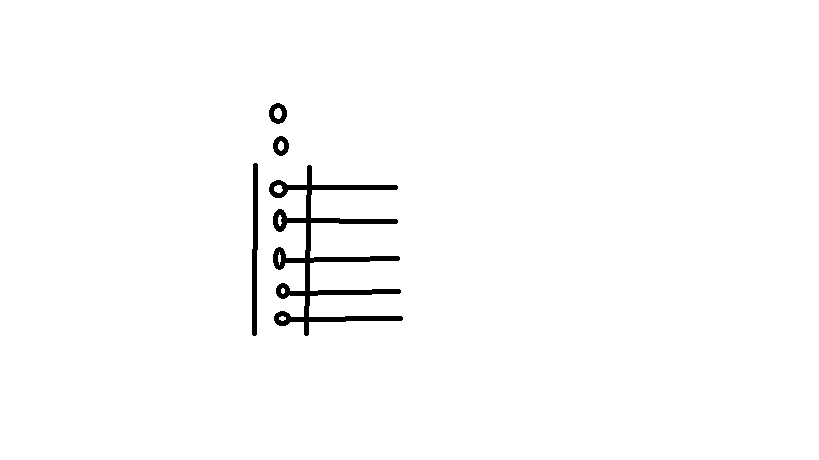
图6
如果将所有的到来的请求都放入“队列”,这是一种事件驱动模式,如之前所述,这可能会导致所有请求延迟增加。
缓冲各阶段吞吐量性能差,增加新的应用层队列
一般来说网络数据读取的吞吐量是高于CPU处理的吞吐量,之前的模型只有最前端有队列,整体吞吐量受限于最小吞吐量,不过我们可以在网络数据读取与CPU处理间建立新的应用层队列,让网络数据处理以更高的吞吐量运行,如图7所示,当然积累的待处理请求不能超过新的队列长度。
将应用队列放在最前端的延迟值为:
L*( X*S3/H3+S1/H1+S2/H2)
增加新的队列后延迟值为:
X*S3/H3+L’*(S1/H2+S2/H2)
在队列长度相同的情况下,增加新的应用层队列后请求延迟值会降低,当然整体吞吐量不会改变。
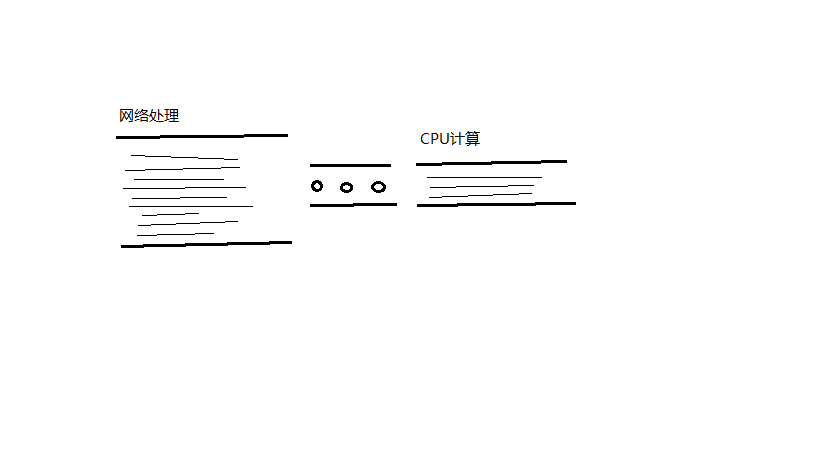
图7
解绑请求与进程,减少所需进程数
之前对需要的进程数计算是基于进程跟请求完全绑定的,这种情况进程在等待I/O时会进入睡眠状态,这其实是对进程资源的一种浪费,如果将请求与进程解绑,让一个进程在等待某种I/O请求时不是去睡眠,而是继续去干其它事,于是我们可以以更少的进程数完成我们的吞吐量及延迟要求。
如果进程一直在“干活”而不会“睡觉”那应该需要多少进程数呢?进程一直干活需要使用CPU,所以这是跟CPU个数有关系的,在这种情况下需要的进程数是:
Z*N1
N1是CPU个数,Z是一个系数,一般应该在1到2之间。
解绑请求与进程是比较复杂的,也根本没有一种方法拆分让进程完全不“睡觉”,例如有些数据读取到一个进程中后总不能让另一个进程去处理的,数据在不同进程间不能共享,这也是Z系数会大于1的原因。
对一个请求拆分越细致对进程资源的浪费就越小,但编程就越复杂,也可能会导致增加CPU计算时间,这是需要衡量的问题,具体不再展开,具体编程是一个很复杂的问题。
13.CPU密集型和I/O密集型对性能值的影响
之前我们讨论的是三阶段情况下各性能值的计算,现实情况有些是CPU密集或I/O密集型的服务,即极端化下的两阶段,即只有网络请求和CPU计算或只能网络请求和I/O处理。简单讨论下这种两阶段服务计算性能时特别的地方。
CPU密集型
只有网络处理和CPU计算两个阶段。
吞吐量及延迟的计算一样,只是少了一个阶段。
因为只有CPU计算,不用对请求进行复杂的拆分,只需要启动少量进程,如跟CPU个数一样,即可以达到最佳的吞吐量值。模型优化第三条可以不采用了。
另外CPU密集型服务处理时间会相对较短,网络数据处理时间占总体时间会较大,需要使用模型优化第二条。
也适宜事事件驱动的方式,并发度会很高,延迟不会增加特别厉害。
I/O密集型
只有网络处理和I/O读写两个阶段(CPU的时间小到忽略不计)
同样的,吞吐量及延迟的计算一样,只是少了一个阶段。
请求拆分以避免进程睡眼是较难的,这时启动的进程数应该跟如下公式相关
min(H3/S3,H2/S2)* (X*S3/H3+S2/H2)
这将远远多于CPU的个数。
另外I/O密集型服务处理时间会相对较长,模型优化第二条也一般不采用,因为其带来的延迟减少占总延迟比是很小的,增加一个队列反而增加了编程复杂度,而且队列相关的CPU时间可能甚至要高于网络处理延迟减少的时间,导致得不偿失。
不适宜事件驱动的方式,因为I/O处理耗时长,会让请求延时急剧上升。
14.多系统性能值计算
之前我们讨论的值计算都是基于单一系统,而现实中是一个请求可能要经过多个不同的系统,如一个http请求,先经过nginx,再经过php,最后到mysql,如图8所示
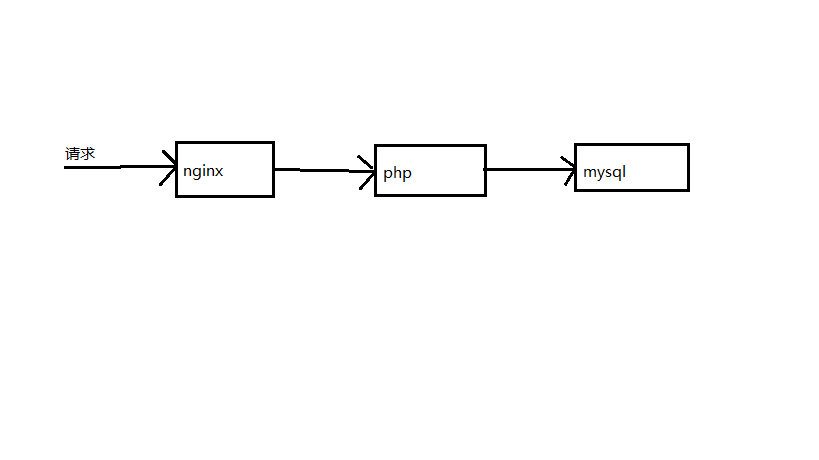
图8
这种情况下性能值有什么不同呢?计算与单个系统各阶段计算类似
吞吐量
是各系统的最小吞吐量值
延迟
各系统延迟值相加
并发度
吞吐量*总的延时
事件驱动模式可以提高并发度,但一般我们只在第一个接入系统实现事件驱动模式就可以提高整个系统的并发度,所以我们无须在所有后续都实现事件驱动,如php或mysql,在后续系统实现事件驱动的一个坏处是后面系统的到达处理极限不能很好的反应到前面的系统,导致并发度越来越大,而导致整个系统的延迟极高。
php的进程模型里就没有网络处理与CPU计算中间的应用层队列,当PHP模块吃紧时会很快反应到nginx模块。
进程数
各个系统的进程数可以依照之前公式算出来,我们关心的一个问题是,A系统调用B系统时,A系统应该启动多少进程。假设B系统的吞吐量为吞吐量B,每个请求的耗时为耗时B
为了使B系统达到相应吞吐量,则A系统发起的请求吞吐量也必须达到相同值,所以调用方进程数在同步调用(进程可能投入睡眠状态)下计算如下
A系统进程数 = A系统吞吐量*耗时A
A系统吞吐量 = B系统吞吐量
耗时A =耗时B
可得:
A系统进程数 = B系统吞吐量*耗时B
15.如何进行性能测试
现实世界比我们之前说的几个简单公式远远复杂多了,不可能有一个精确的公式可以描述出来,所以性能值我们也不能说填充几个参数就可以像算数学题一样算出来,再加上我们面对的系统都是多个系统组合而成,直接算更不可能了,那些简单公式只是指导致我们进行测试。对于一个系统来说,真正的性能值需要通过工具测试出来,如用siege工具。
用工具进行测试的思路
吞吐量是一个比较固定的值,先观测它。根据之前的公式
A系统进程数 = B系统吞吐量*耗时B
得
B系统吞吐量 = A系统进程数/耗时B
可知为了观察到最大的吞吐量应该不断提高工具的并发进程数,直到吞吐量不再上升。
当吞吐量不再上升时说明已到了之前说所的H-S-F状态临界点,如果进一步提高客户端的并发,延时将会上升,这时我们可以得出延时的最小值。
客户端的并发度与待测系统的并发度不一定相同,但可以肯定的是他们是正相关关系。
当延时处于最小值,吞吐量处于最大值时,这时得出的并发度是最佳并发度。最佳并发度不代表最大并发度,最大并发度对于事件驱动模型来说,甚至是无限的,只要不超过客户端超时时间,但过长的时间不是我们能接受的。首先我们定义一个可以接受的最大延时,然我进一步提高客户端的并发度,直到延时达个这个值,这时得到的服务器的并发值才是有实际意义的最大并发度值。
性能测试工具siege
Ben: $ siege -u shemp.whoohoo.com/Admin.jsp-d1 -r10 -c25
..Siege 2.65 2006/05/11 23:42:16
..Preparing 25 concurrent users for battle.
The server is now under siege...done
Transactions: 250 hits
Elapsed time: 14.67 secs
Data transferred: 448000 bytes
Response time: 0.43 secs
Transaction rate: 17.04 trans/sec
Throughput: 30538.51 bytes/sec
Concurrency: 7.38
Status code 200: 250
Successful transactions: 250
Failed transactions: 0
Transaction rate 指吞吐量
Response time 指延时
Concurrency 指并发度
如何寻找瓶颈
有时我们需要找到整个系统的瓶劲,以提高性能值。首先我们应该找到整个系统是哪个子系统的的处理出现了瓶劲,是nginx,php还是mysql。然后研究一个子系统,是网络读取,CPU还是磁盘I/O出现了瓶颈,或是进程数启得少了,或是我们要优化自己的程序。具体操作比较复杂,可另成文,不展开讨论。
参考资料
1. UNIX 网络编程
2. High Performance MySQL