Hive数仓:使用桶表
文章目录
- Hive数仓:使用桶表
- 实验环境
- 实验步骤
- 1.点击"命令行终端",打开新窗口
- 2.启动MySQL
- 3.指定元数据数据库类型并初始化Schema
- 4.启动Hadoop
- 5.启动hive
- 6.创建名为dolphin的数据库
- 7.创建分桶表
- 8.查看分桶表具体信息
- 9.测试分桶表导入本地数据
- 10.查看表bucket数据
- 11.新建分桶表和过渡表
- 12.插入数据到分桶表
- 13.查询bucket_2的信息
- 14.hive中查询分桶表中的数据
- 15.修改桶表中bueket数量
- 15.分桶表的抽样查询
- 16.删除分桶表bucket_2
- 实验总结
实验环境
Linux Ubuntu 16.04
前提条件:
1)Java 运行环境部署完成
2)Hadoop2.7.6的单点部署完成
3) MySQL数据库安装完成
4) Hive单点部署完成
上述前提条件,我们已经为你准备就绪了。
###实验内容
使用Hive完成以下实验:
- 创建分桶表
- 导入数据
- 抽样查询
- 删除分桶表
现在开始我们的学习吧!
实验步骤
1.点击"命令行终端",打开新窗口
2.启动MySQL
本实验平台已经提前安装好了MySql(账户名root,密码123456),这里只需要启动MySql服务即可
sudo /etc/init.d/mysql start
3.指定元数据数据库类型并初始化Schema
schematool -initSchema -dbType mysql
4.启动Hadoop
进入/apps/hadoop/bin目录
cd /apps/hadoop/sbin
执行启动脚本
./start-all.sh
注意,如果终端显示Are you sure you want to continue connecting (yes/no)? 提示,我们需要输入yes,再按回车即可。
检验hadoop是否启动成功
jps
5.启动hive
hive
此时,终端显示hive>,表明已经进入hive的命令行模式。
6.创建名为dolphin的数据库
create database if not exists dolphin;
显示并使用新建的dolphin数据库
show databases;
use dolphin;
7.创建分桶表
创建桶表的语法:clustered by 后面加的列一定是在表中存在的列
后面接的是桶的个数,4意味着一次上传数据会根据id的hash值再与4取模,根据这个值决定这条数据落入那个文件中。
create table bucket(id int, name string) CLUSTERED BY (id) INTO 4 BUCKETS row format delimited fields terminated by ','lines terminated by '\n'stored as textfile;
执行后显示如下:

8.查看分桶表具体信息
输入如下命令,回车
desc formatted bucket;
执行后显示如下:
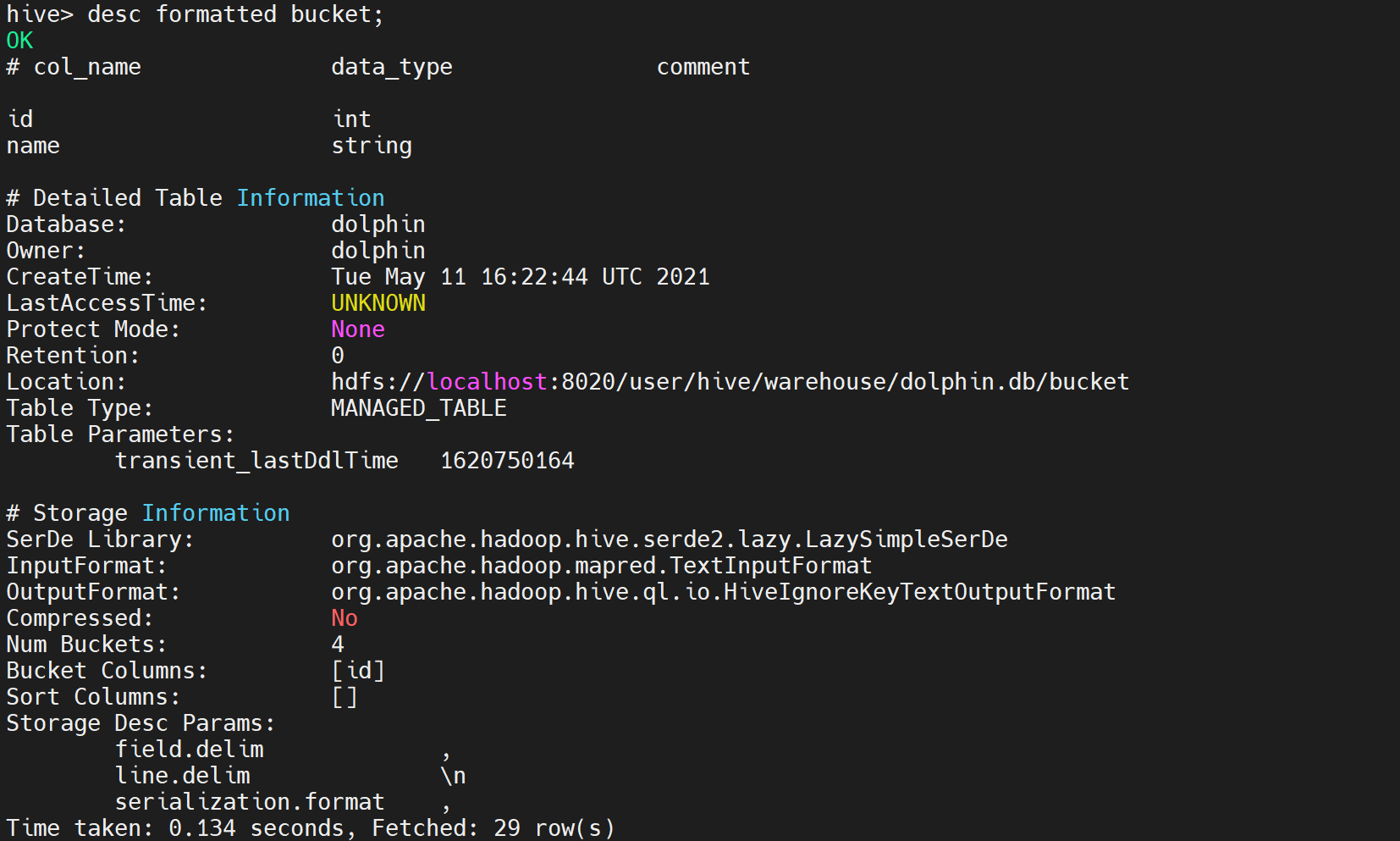
我们从上面观察表的基本结构,列,属性,存储位置,导入导出依赖,分桶数量,等等
9.测试分桶表导入本地数据
设置强制分桶机制来保证reducer数量和桶的数量一致
set hive.enforce.bucketing = true;
尝试直接上传一个数据
我们已经在桌面为大家准备好数据集bucket.txt,打开文件后观察数据
load data local inpath '/home/dolphin/Desktop/bucket.txt' overwrite into table bucket;

执行后显示如下:

10.查看表bucket数据
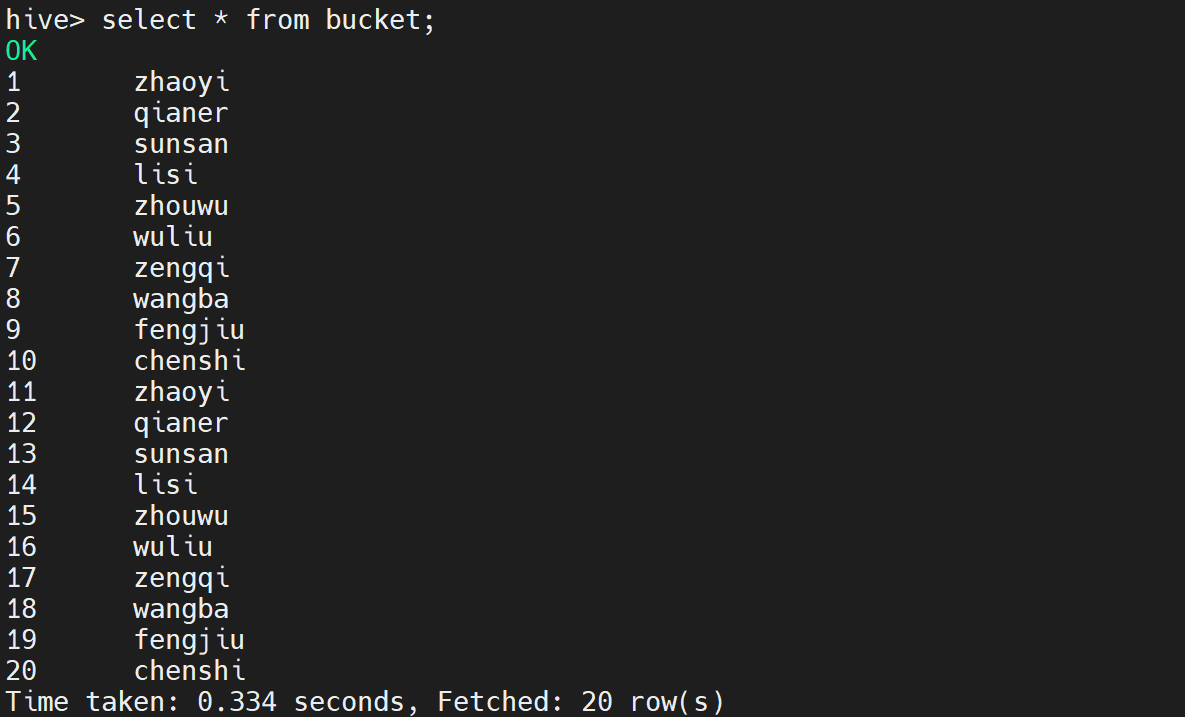
首先查看bucket中的数据
select * from bucket;
执行后部分日志显示如下:
查看数据在HDFS上的分布
新打开一个命令行终端,输入如下命令
hadoop fs -ls /user/hive/warehouse/dolphin.db/bucket
执行后部分日志显示如下:

我们看到虽然设置了强制分桶,但实际bucket表下面只有一个bucket.txt一个文件
分桶也就是分区,分区数量等于文件数,所以上面方法并没有成功分桶。
结论:桶表不能通过load的方式直接加载数据
11.新建分桶表和过渡表
创建新的分桶表
create table bucket_2(id int, name string) CLUSTERED BY (id) INTO 4 BUCKETS row format delimited fields terminated by ','lines terminated by '\n'stored as textfile;
创建过渡表
create table dome(id int, name string)row format delimited fields terminated by ',';
执行后显示如下:

12.插入数据到分桶表
现在,我们用插入的方法给另外一个分桶表传入同样数据
首先上传数据到过渡表dome
load data local inpath '/home/dolphin/Desktop/bucket.txt' overwrite into table dome;
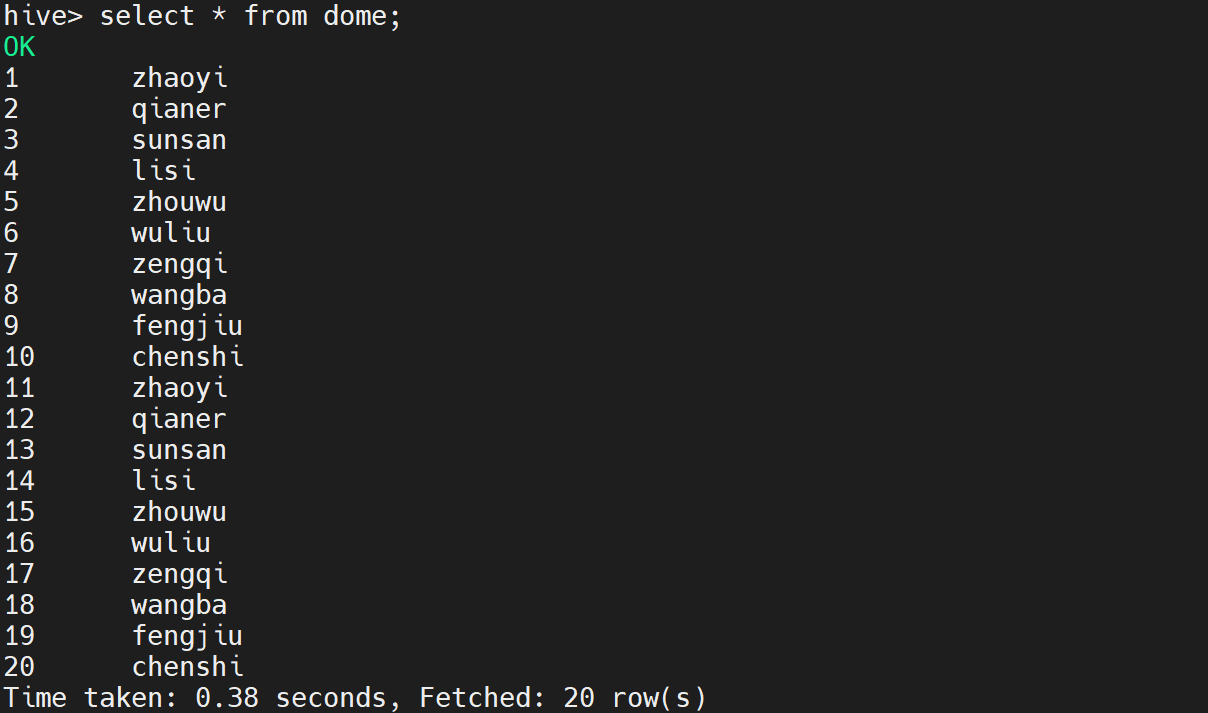
查看数据是否导入成功
select * from dome;
执行后显示如下:
将过渡表中的数据插入新建的分桶表
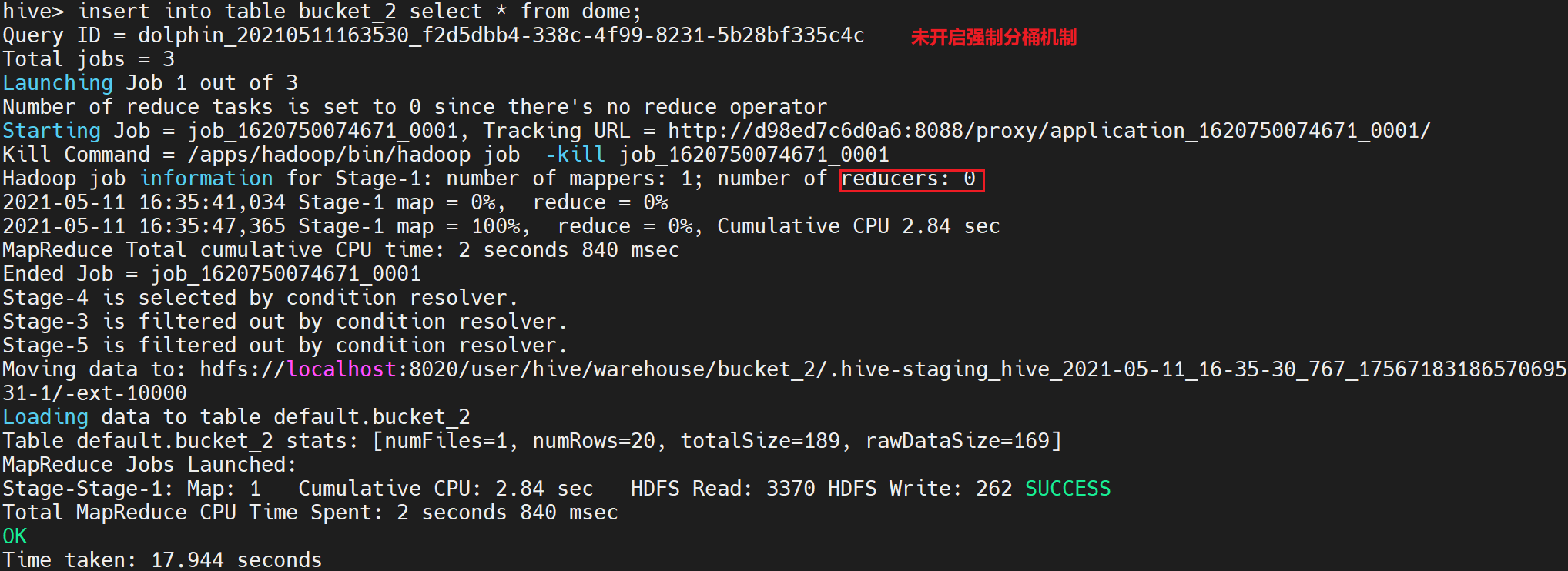
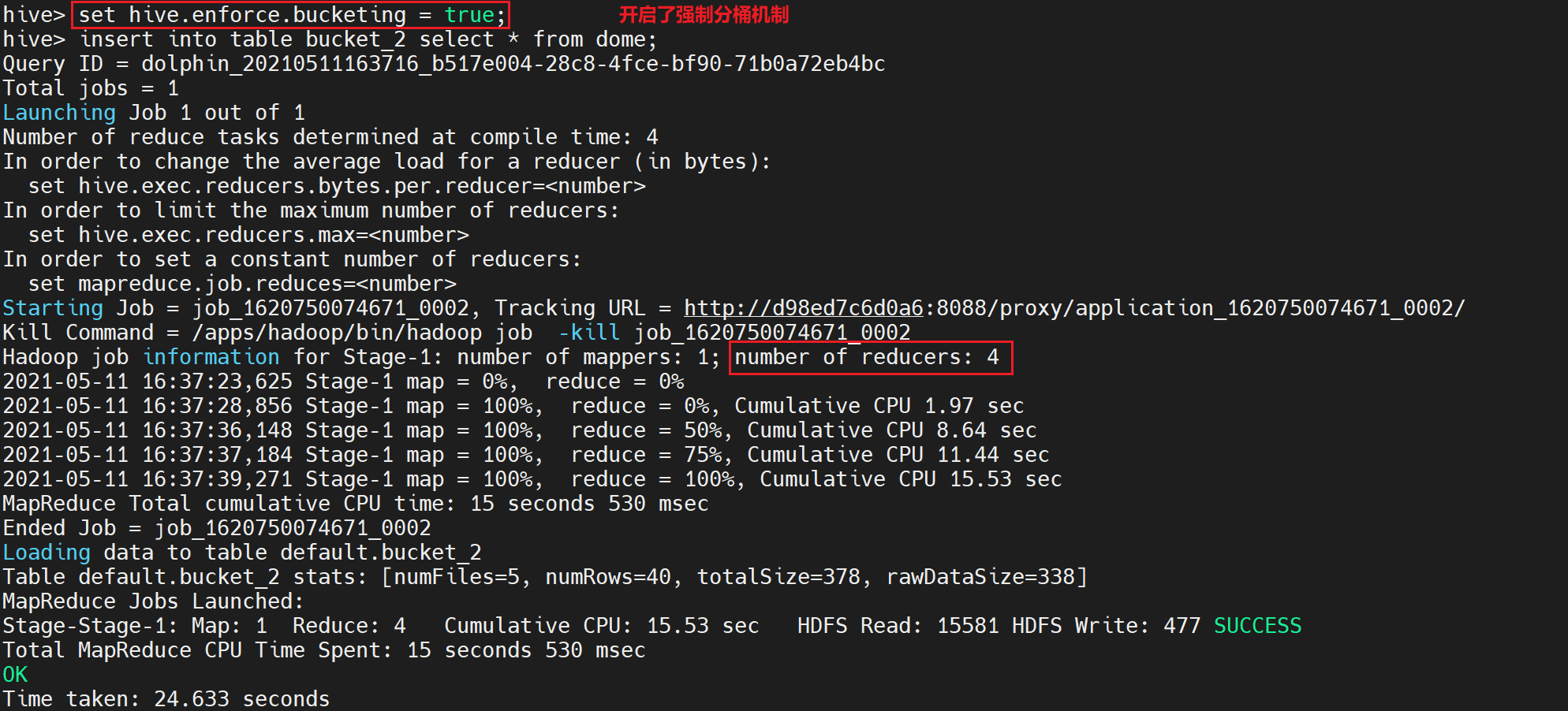
insert into table bucket_2 select * from dome;
执行后部分日志显示如下:
由于我们设置了强制分桶机制,在这里我们可以看到MarReduce任务中启动了4个Reduce
13.查询bucket_2的信息
查看bucket_2数据在HDFS上的分桶文件
重新打开一个命令行终端,输入如下命令,回车
hadoop fs -ls /user/hive/warehouse/dolphin.db/bucket_2
执行后显示如下:

查看bucket_2中的分桶中的数据
hadoop fs -cat /user/hive/warehouse/dolphin.db/bucket_2/000000_0
执行后部分日志显示如下:

14.hive中查询分桶表中的数据
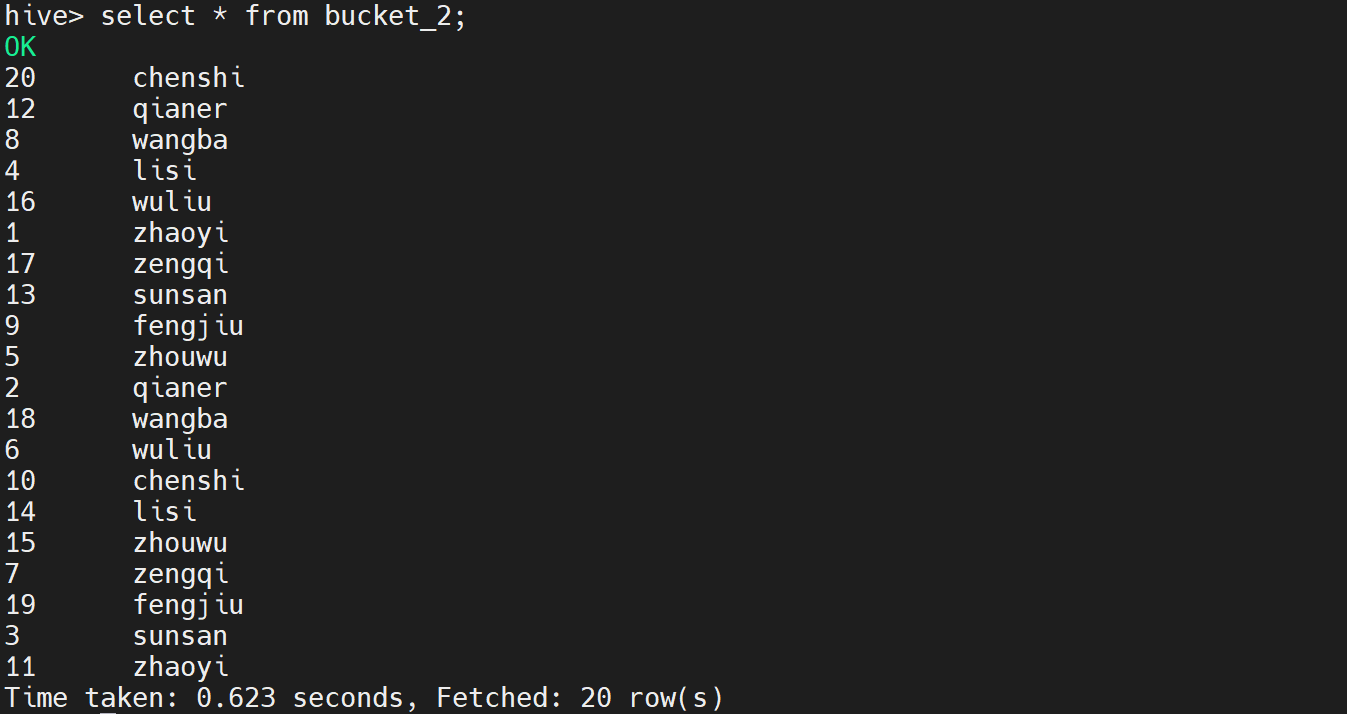
查看bucket_2中的数据
select * from bucket_2;
执行后显示如下:
15.修改桶表中bueket数量
重新将bucket_2表中的数据按id,name分成20个桶,并用id排序
alter table bucket_2 clustered by(id,name) sorted by(id) into 20 buckets;
执行后部分日志显示如下:
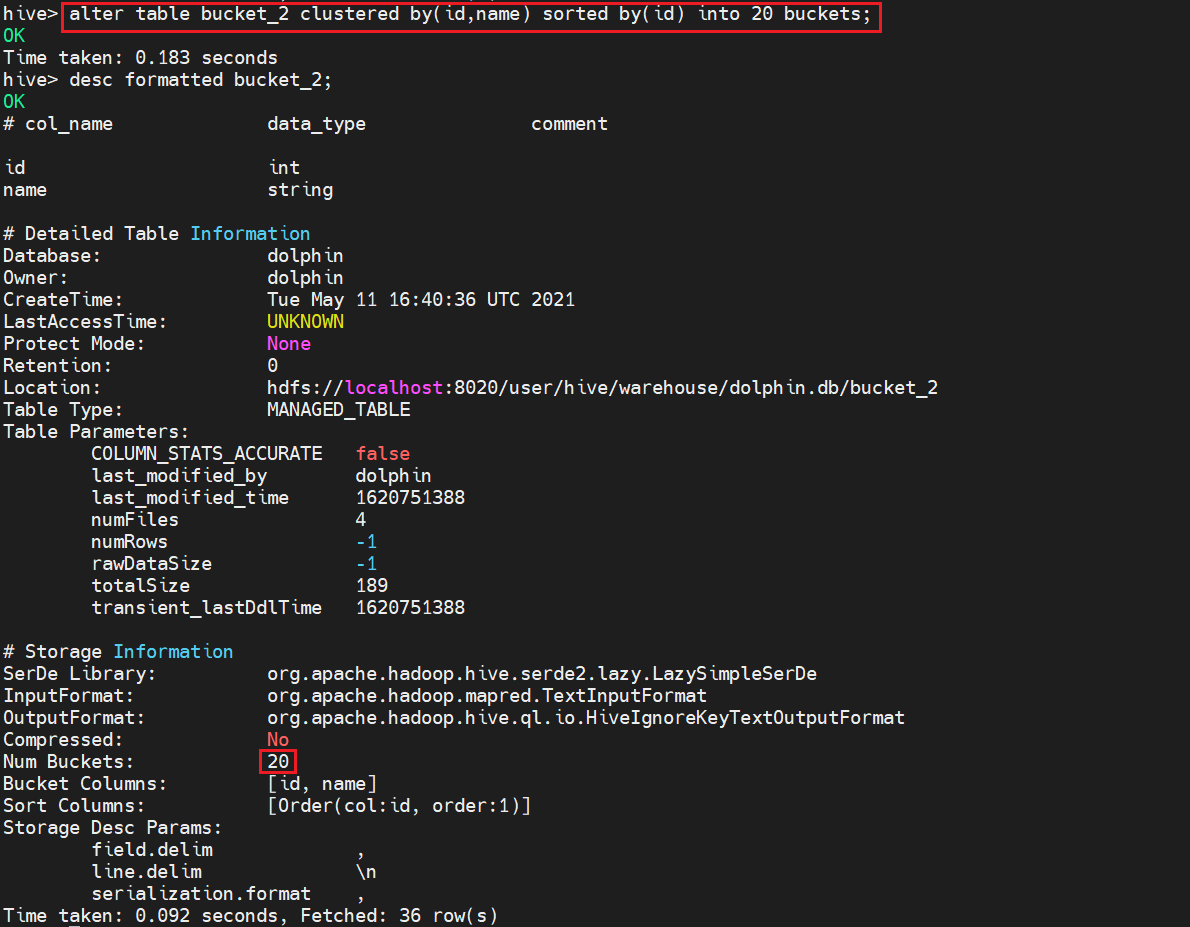
观察日志发现,表格已经分成20个桶
15.分桶表的抽样查询
语法:
select * from table_name tablesample(bucket X out of Y on field);
X表示从哪个桶中开始抽取,Y表示相隔多少个桶再次抽取。
Y必须为分桶数量的倍数或者因子
select * from bucket_2 tablesample(bucket 2 out of 4 on id);
执行后部分日志显示如下:

16.删除分桶表bucket_2
输入如下命令,回车
drop table bucket_2;
执行后显示如下:

实验总结
- 桶表是对某一列数据进行哈希取值以将数据打散,然后放到不同文件中存储。
- 在hive分区表中,分区中的数据量过于庞大时,建议使用桶。
- 在分桶时,对指定字段的值进行hash运算得到hash值,并使用hash值除以桶的个数做
取余运算得到的值进行分桶,保证每个桶中有数据但每个桶中的数据不一定相等。
做hash运算时,hash函数的选择取决于分桶字段的数据类型 - 分桶后的查询效率比分区后的查询效率更高
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)