1.什么是动态sql
sql的内容是变化的, 可以根据条件获取到不同的sql语句.
主要是where部分发生变化。
动态sql的实现, 使用的是mybatis提供的标签
2.为什么使用动态sql
使用动态sql可以解决某些功能的使用 例如使用条件查询某个商品 你输入价格,地区等等进行筛选,如果使用静态sql可能会查询出来的是一个空内容 但使用动态sql可以很好的解决这种问题 例如
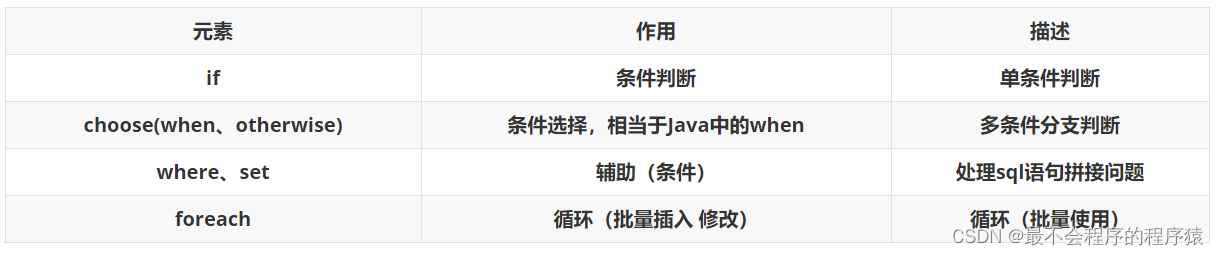
3.动态sql的标签
3.1 if标签-单条件判断
作用:筛选条件语句
dao层方法为:
public User findConditon(@Param("name")String name, @Param("email")String email);
mapper层
<!--如果姓名不为空则安姓名查找 如果姓名为空则按邮箱查找 否则查询全部-->
<select id="findConditon" resultType="com.wx.entity.User">
select * from tbl_user02
<where>
<if test="name!=null and name!=''">
and name = #{name}
</if>
<if test="email!=null and email!=''">
and email = #{email}
</if>
</where>
</select>
3.2 choose标签 多条件分支判断
public User findByCondition(@Param("name")String name, @Param("email")String email,
@Param("pwd")String pwd);
<select id="findByCondition" resultType="com.wx.entity.User">
select * from tbl_user02
<where>
<choose>
<when test="name!=null and name!=''">
and name = #{name}
</when>
<when test="email!=null and email!=''">
and email = #{email}
</when>
<otherwise>
and pwd = #{pwd}
</otherwise>
</choose>
</where>
</select>
3.3 where语句
如果不使用where语句 就要在where其他判断语句前加入1=1 如 select * from tbl_user02 where 1=1加其他的if判断语句 如果我们不加入这个1=1就可以直接使用where语句 上面的choose和if都搭配使用 使用where 语句 可以自动消除第一个条件中的and 且加上where 例子如上面两个标签中即可
3.4set标签
这个标签配合if标签一起用 一般用于修改语句 如果传递的参数为null 那么就不会修改该列的值
public int updateUser(User user);
<update id="updateUser" parameterType="User">
update tbl_user02
<set>
<if test="name!=null and name!=''">
name=#{name},
</if>
<if test="pwd!=null">
pwd=#{pwd},
</if>
<if test="email!=null">
email=#{email},
</if>
</set>
where id = #{id}
</update>
3.4foreach标签
循环标签 适用于批量添加、删除 和查询记录
3.4.1用于批量查询
查询id为1 3 5 的用户信息
正常sql语句为 select * from tbl_user02 where id in(1,3,5);
下面的为使用foreach遍历 循环查询
解释:
<foreach collection="集合类型" open="开始的字符" close="结束的字符"
item="集合中的成员" separator="集合成员之间的分割符">
#{item的值}
</foreach>
标签属性:
collection:表示循环的对象是数组还是list集合。如果dao方法的形参是数组,collection="array";
如果dao方法形参是list,collection="list";
open:循环开始的字符。sql.append("(");
close:循环结束的字符。sql.append(")");
item:集合成员,自定义的变量。Integer item = idList.get(i);
separator:集合成员之间的分隔符。sql.append(",");
#{item的值}:获取集合成员的值;
具体代码实现
dao层
public List<User> findByIds(Integer[] ids);
mapper层为
<select id="findByIds" resultType="com.wx.entity.User">
select * from tbl_user02 where id in
<foreach collection="array" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</select>
测试类为:
@Test
public void testFindByIds() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
Integer[] ids = {1,3,5};
List<User> user = userDao.findByIds(ids);
System.out.println(user);
session.close();
}
查询出三条记录

3.4.2用于批量删除
dao层
public int BatchDelete(Integer[] ids);
mapper层
<delete id="BatchDelete">
delete from tbl_user02 where id in
<foreach collection="array" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</delete>
测试类:
@Test
public void testBatchDelete() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
Integer[] ids = {1,3,5};
int row = userDao.BatchDelete(ids);
System.out.println(row);
session.commit();
session.close();
}

3.4.3用于批量添加
dao层
public int batchAdd(List<User> users);
mapper层
<!--注意 因为循环添加的为一个对象 所以下面添加的值就必须是users.name ...-->
<insert id="batchAdd">
insert into tbl_user02(name,pwd,email) values
<foreach collection="list" item="users" separator=",">
(#{users.name},#{users.pwd},#{users.email})
</foreach>
</insert>
测试类:
@Test
public void testBatchAdd() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
List<User> list = new ArrayList<User>();
list.add(new User("张三","123","zs@qq.com"));
list.add(new User("李四","123","ls@qq.com"));
list.add(new User("王五","123","ww@qq.com"));
int row = userDao.batchAdd(list);
System.out.println(row);
session.commit();
session.close();
}

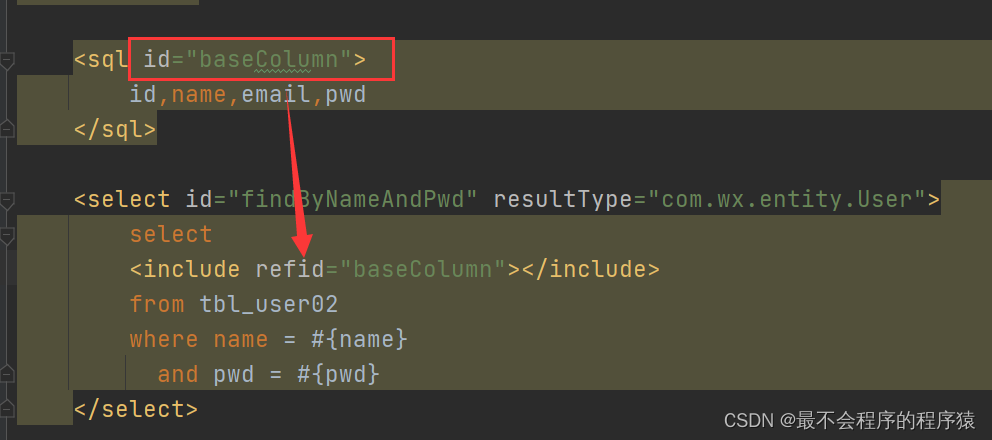
3.4.4sql片段
一般用于查询语句的时候 select * … 这种不推荐 所以用sql片段可以很好的解决这个问题
4.mybatis映射文件处理特殊字符.
当我们使用条件语句查询的时候 就比如在某个范围中使用条件如 money>100 and money<200
这个条件在mapper中无法直接写所以需要特殊处理,有两种解决办法:
第一种:转义标签 <
第二种: <![CDATA[sql]]>
<select id="findByMaxAndMin" resultType="com.ykq.entity.Account">
<![CDATA[select * from account where id >#{min} and id <#{max}]]>
</select>
第一种:转义字符处理
dao层
public User findByMaxAndMin(@Param("min") int min,@Param("max") int max);
mapper层
<select id="findByMaxAndMin" resultType="com.wx.entity.User">
select * from tbl_user02 where id >#{min} and id < #{max}
</select>
测试类
@Test
public void testFindByMaxMin() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
User user = userDao.findByMaxAndMin(1, 3);
System.out.println(user);
session.commit();
session.close();
}

第二种: <![CDATA[sql]]>
dao层
public User findByMaxAndMin01(@Param("min") int min,@Param("max") int max);
实体层
<select id="findByMaxAndMin01" resultType="com.wx.entity.User">
<![CDATA[select * from tbl_user02 where id>#{min} and id<#{max}]]>
</select>
测试类
@Test
public void testFindByMaxMin01() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
User user = userDao.findByMaxAndMin01(1, 3);
System.out.println(user);
session.commit();
session.close();
}

5.mybatis完成模糊查询
语法:select * from 表名 where 列名 like ‘%a%’ 但是% a %这样在mapper层无法使用 解决办法有两种
第一种:使用字符串函数(concat)完成拼接
dao层
public User findByName(@Param("name")String name);
mapper层
<select id="findByName" resultType="com.wx.entity.User">
select * from tbl_user02 where name like concat('%',#{name},'%');
</select>
测试类
@Test
public void testFindByName() throws Exception{
Reader rd = Resources.getResourceAsReader("conf.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(rd);
SqlSession session = factory.openSession();
UserDao userDao = session.getMapper(UserDao.class);
User user = userDao.findByName("李");
System.out.println(user);
session.close();
}

第二种:使用${}
<select id="findByName" resultType="com.wx.entity.User">
select * from tbl_user02 where name like '%${name}%';
</select>
两者区别:concat不能解决sql注入的问题 第二种是预编译 可以解决sql注入问题
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)