不涉及原理,只是快速开始使用
更详细的请参考官方文档
https://bert-as-service.readthedocs.io/en/latest/index.html
可用环境
python==3.7
pip install bert-serving-server bert-serving-client tensorflow==1.13.1 protobuf==3.19.0
1. 下载预训练模型
(下载可能需要一些时间,等待的时候可以先去下一步把python库安了)
可以直接去github下载
https://github.com/google-research/bert

解压后的文件有5个(我使用的是BERT-Base, Uncased这个预训练模型)
2. 安装python库
pip install bert-serving-server
pip install bert-serving-client
3. 启动服务
在命令行输入
bert-serving-start -model_dir D:\Documents\Code\PythonCode\bert\model\ -num_worker=1
这条指令启动了位于-model_dir地址的bert模型,提供一个工作通道
注意:地址填绝对地址,相对地址可能会出问题(有的人出错,有的人不出错)
启动成功会显示

一定是显示all set , ready to serve request!才算启动成功
和jupyter notebook一样,在使用Bert的过程中这个命令行窗口要保持开启
4. 使用
from bert_serving.client import BertClient
print(“::0”)
bc = BertClient()
ans = bc.encode([‘First do it’, ‘then do it right’, ‘then do it better’])
print(len(ans[0]))
print(“::1”)
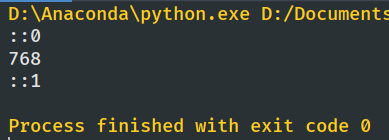
encode是将句子转换为固定长度向量返回,小型的模型的向量长度为768,大型的为1024
encode接收两种数据形式
一种是list[str],一个列表,里面是为分词的句子,之后得到的矩阵每一行对应一个句子
比如
[‘First do it’, ‘then do it right’, ‘then do it better’]
另一种是list[list[str]],一个列表,里面是分词完毕的句子词语的列表,同样得到的矩阵也是一行对应一个句子
比如
[[‘First’, ‘do’, ‘it’], [‘then’, ‘do’, ‘it’, ‘right’], [‘then’, ‘do’, ‘it’, ‘better’]]
关于坑
tensorflow版本
一开始安装的是最新的2.2版本,启动服务的时候报错
TypeError: cannot unpack non-iterable NoneType object
卸载当前的tensorflow,重新安装tensorflow
或者直接覆盖
pip install tensorflow==1.13.0rc1
内存问题(num_worker)
官方给的教程写的基本指令是num_worker=4
我电脑太渣,瞬间CPU和内存飙满,但是也不给个报错MemoryError,废了好大的劲才发现是内存问题
这种有可能是卡在中间,也不报错,所以一定要记住all set , ready to serve request!才算启动成功
一开始还是要从num_worker=1开始
一般启动过程中会有几秒资源占用很高,过去之后会降下来
最长序列长(max_seq_len)
如果你提供给他的句子比较长,可能会出现下面这个警告

bert默认句子最长是25,超过了的词直接被放弃,
举个栗子
这里有一个长句(句子随便找的)
“In the special period, Shanghai will take advantage of ChinaJoy platform on industry collaboration, international cooperation and create better business environment for the industry, according to the organizers including local government bureaus.”
一共32个词,它只会取前25个作为特征来生成向量
如何解决
回到上面的第3步,
更改启动参数
加一条“max_seq_len=40”
比如
bert-serving-start -model_dir D:\Documents\Code\PythonCode\bert\model\ -num_worker=1 -max_seq_len=40
如果你不知道自己的数据最长多少,那就设置成None,动态调节,但相应的计算量就上去了,像我这样电脑渣的,
小风扇呼呼转,分分钟CPU、内存爆炸给你看。
