在上一期中,介绍了常见的软件质量度量模型(McCall、Boehm、ISO 9126模型),通过这些模型可以对软件质量进行科学的评价。在本期中,主要介绍
7个软件质量的评价指标(
编码规范、源代码行、千行代码bug率、圈复杂度、代码覆盖率、扇入/扇出数、设计开发约束)

1 编码规范
度量标准:MISRA C/MAAB
作用:编码/建模标准化
关于编码规范,在前几期已经介绍了MISRAC和MAAB相关内容,详细介绍可以参考公众号中相关文章。大家也可以通过MATLAB中的Polyspace和Simulink模块体验一下MISRA C和MAAB相关内容(可以参考MATLAB帮助文档中的相关例子)。
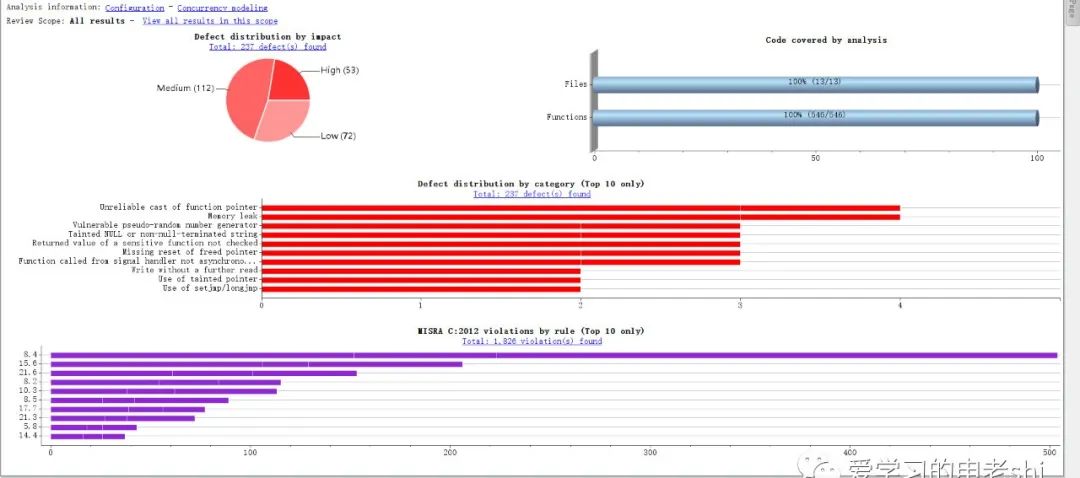
MATLAB中MISRA C使用案例
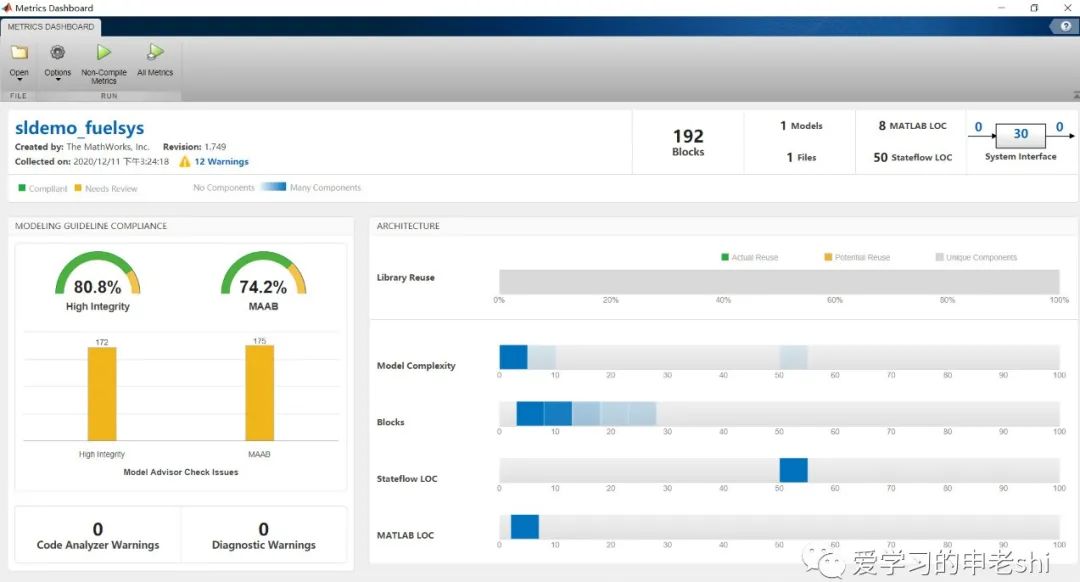
MATLAB中MAAB使用案例
2 源代码行 SLOC
度量标准:源代码行数
作用:工作量评估,编写效率评价
源代码行(SLOC, Source LinesOf Code),也称为代码行(LOC, Lines Of Code),是一种通过统计程序源代码的行数来度量程序大小的方法。这种方法可能是最简单的软件衡量指标,主要体现了软件的规模,一般用来预测开发程序需的工作量,同时也用来评价程序的编写效率。
2.1 两类SLOC测量方法
物理代码行(LOC, Physical SLOC),是程序源代码中(包括注释行)的代码行数。
逻辑代码行(LLOC, Logical SLOC),是测量可执行“语句”的数量(不同的计算机语言有不同的定义)。
2.2 使用SLOC的问题
在使用SLOC方法评价时,可能会遇到歧义,以C语言代码为例(示例1):
for (i = 0; i<100; i++) printf("hello"); /*一共有几行?*/
以上代码有1个物理代码行(只有1行),2个逻辑代码行(for语句和printf语句),1个注释行(1行注释行)。
由于不同程序员的不同编码习惯和编码标准,在确保功能不变的情况下,上述代码可以被改写为(示例2):
/* 现在有几行?*/for (i = 0; i < 100; i++){printf("hello");}
有5个物理代码行,2个逻辑代码行,1个注释行。
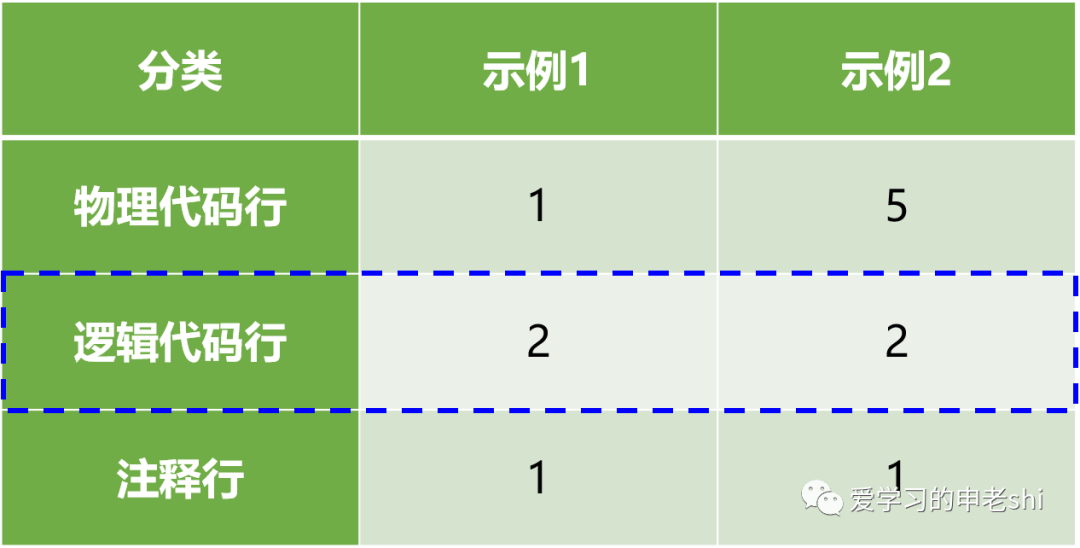
通过以上两个相同效果的例子,可以看出代码行参数有很大的差异。如果需要比较,可以选择逻辑代码行进行对比,可以获得相对准确的信息。
2.3 SLOC方法的优劣
优:有效估计工作量,计数方便直观。
劣:不能有效评估程序员效率,无法进行程序功能评估,易增加冗余代码,未考虑不同计算机语言差异
实践证明SLOC和工作量之间的关系高度相关,简单来说就是SLOC值越大的程序开发时间越长,可以非常有效地估计工作量。由于代码行是一个物理实体,可以通过程序来进行计数和统计,也易于进行可视化处理,获得一个直观的度量。
但是对于SLOC度量方法存在一些争议,特别是有时候可能会被滥用。SLOC度量方法不能很好地衡量程序员效率。首先,仅仅使用编码阶段的结果来衡量项目的生产力是没有用的,编码阶段通常只占整个工作量的30%到35%;其次,SLOC度量方法和程序功能的相关性较差,因为一个优秀的程序员只开发几行代码,但是在功能方面比最终创建更多行的程序员更有效率。并且,特别有经验的程序员员往往会被分配最困难的任务,因此有时可能会比其他程序员在某项任务上的“效率”更低;另外,追求更高的SLOC会引起程序员写不必要的冗长代码的动机,增加程序复杂性和维护成本;此外,在当今的软件场景中,软件通常是使用一种以上的语言开发的。不同语言实现相同功能使用代码的行数不同,使用SLOC无法对程序进行有效地度量。
3 千行代码bug率
度量标准:bug数/(代码行/1000),数值越小质量越好
作用:bug统计/跟踪/修复
要想实现更好的测试以及更高的可维护性,bug跟踪是必不可少的。每个代码段、模块或时间段(天、周、月等)内的bug可以很容易通过工具统计出来。这样,可以及早发现并及时修复。
3.1 CMMI要求
在CMMI*级别中的关于Bug率相关的信息如下:
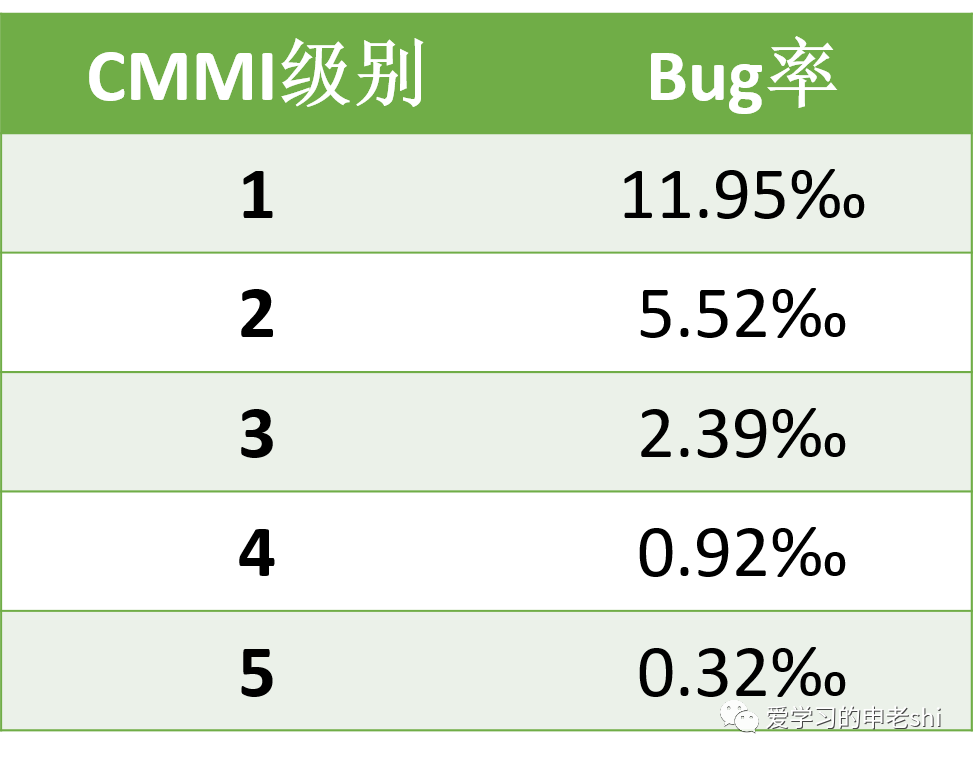
*CMMI(Capability Maturity Model Integration For Software,软件能力成熟度模型集成)是由美国卡耐基梅隆大学软件工程研究所(Software Engineering Institute,SEI)组织全世界的软件过程改进和软件开发管理方面的专家历时四年而开发出来的,并在全世界推广实施的一种软件能力成熟度评估标准,主要用于指导软件开发过程的改进和进行软件开发能力的评估。
3.2 bug率的优劣
对于千行代码bug率,从考核标准上来说,bug率数值越小就说明越好,但是基于这个结果,可能会引导团队成员做出一些对长远和整体效率无益的行为,例如:增大基数,增加无意义代码;把定长循环分开写,写成顺序方法;把可配置信息写死到代码中;大量的复制、粘贴代码。千行代码Bug率,虽然没有明确鼓励增加代码行数,但是这个计算结果对于优秀的员工来说是相当的不公平。它隐含的推广了“尽量增大代码行数”这个意思。
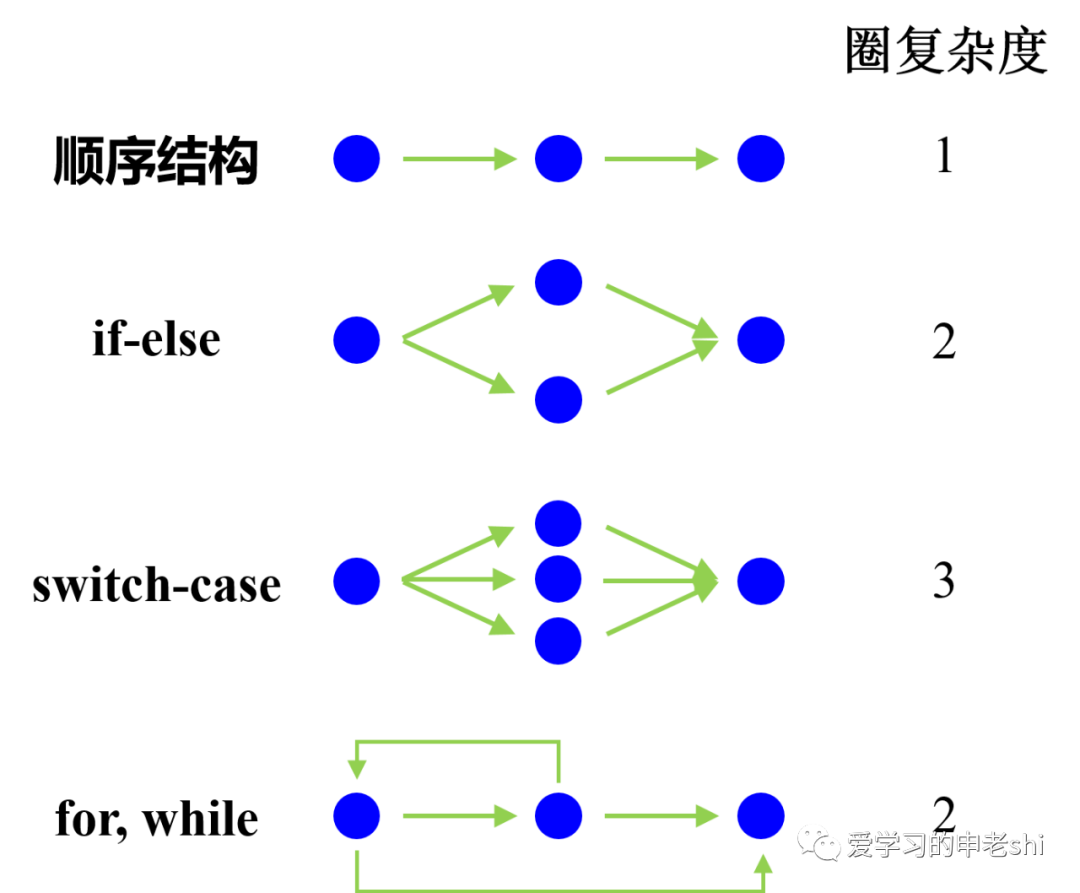
4 圈复杂度
度量标准:圈复杂度的大小
作用:结构复杂度衡量
圈复杂度(CyclomaticComplexity)是一种
代码复杂度的衡量标准,在软件测试的概念里,圈复杂度用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护。
4.1 原理(分支的个数)
圈复杂度为1,意味着代码只有一条路径;对于有一条分支的代码,它的圈复杂度为2。简单计算方法:从1开始,一直往下经过程序,一旦遇到以下关键字或者其它同类的词(if、while、repeat、for、and、or)就加1,在case语句中每一种情况都加1。
4.2 基于流程图的计算方法
公式1:V(G)=e-n+2p。其中,e表示流程图中边的数量,n表示流程图中节点的数量,p表示流程图中的连接组件数目(连接组件数是相连节点的最大集合)。因为流程图都是连通的,所以p为1.公式2:V(G)=区域数=判定节点数+1。其实,圈复杂度的计算还有更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1,也即控制流图的区域数。公式3:V(G)=R。其中R代表平面被控制流图划分成的区域数。
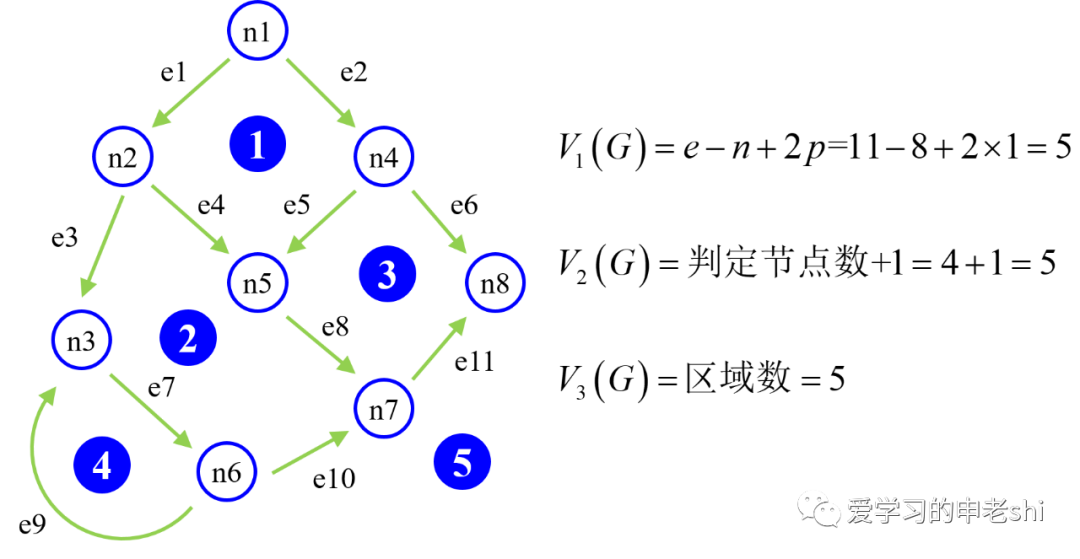
针对程序的流程图计算圈复杂度时,最好还是采用公式1;而针对模块的流程图时,可以直接统计判定节点数(公式2),更为简单;针对复杂的流程图时,使用公式3计算区域数更简单。
5 代码覆盖率
度量标准:覆盖率越大越好
作用:测试效果衡量
代码覆盖率:一种对代码的覆盖程度的度量方式。代码覆盖程度的度量方式是有很多种的,这里介绍最常用的4种。
5.1 语句覆盖(Statement Coverage)
又称行覆盖(Line Coverage),段覆盖(Segment Coverage),基本块覆盖(Basic Block Coverage),这是最常用也是最常见的一种覆盖方式,就是
度量被测代码中每个可执行语句是否被执行到了。语句覆盖常常被指责为“最弱的覆盖”,只覆盖代码中的执行语句,不考虑各种分支的组合等。
测试效果的不明显,很
难更多地发
现代码中的问题。举个例子:
int Example1(int a, int b){ return a / b;}
如果测试用例为:
TestCase1: a = 1, b = 5
测试结果是代码覆盖率达到了100%,但是没有发现其中最简单的bug:当b = 0时,出现一个除零异常。
5.2 分支覆盖(Branch Coverage)
又称判定覆盖(Decision Coverage),所有边界覆盖(All-Edges Coverage),基本路径覆盖(Basic Path Coverage),判定路径覆盖(Decision-Decision-Path)。
分支覆盖度量程序中每一个判定的分支是否都被测试到了。例如以下代码:
int Example2(int a, int b){ int Result = 0; if (a < 10 || b > 10) // 判定 { return Result += 1; // 分支一 } else { return Result -= 1; // 分支二 } return Result;}
设计分支覆盖测试用例时,
只需考虑判定结果为true和false两种情况,因此,设计如下的测试用例就能达到判定覆盖率100%:
TestCaes1: a = 5, b = 5 //判定结果为true,Result = 1, 覆盖分支一TestCaes2: a = 15, b = 5 //判定结果为false,Result = -1, 覆盖分支二
5.3 条件覆盖(ConditionCoverage)
它度量判定中的每个子表达式结果true和false是否被测试到了。以Example2代码为例:
int Example2(int a, int b){ int Result = 0; if (a < 10 || b > 10) // 判定 { return Result += 1; // 分支一 } else { return Result -= 1; // 分支二 } return Result;}
按条件覆盖设计的测试用例,需要覆盖条件表达式的所有可能,如条件数为n,所用的测试用例数为2的n次方,在示例代码中,条件数为2(a<10和b>10),因此需要4个测试用例,具体测试用例如下:
TestCaes1: a = 5, b = 15 //a: true,b: true, 判定为true, Result = 1TestCaes2: a = 5, b = 5 //a: true,b: false, 判定为true, Result = 1TestCaes3: a = 15, b = 15 //a: false, b: true, 判定为true, Result = 1TestCaes4: a = 15, b = 5 //a: false, b: false, 判定为false, Result = -1
在条件数较多的代码中,条件覆盖的测试用例数量惊人,如果有10个条件,则需要2的10次方1024个测试用例以满足覆盖率100%。
5.4 修正条件判定覆盖(Modified Condition/Decision Coverage)
修正条件判定覆盖(MC/DC)要求每个条件都要独立影响判定结果。是一种条件覆盖的优化,可以减少所需的测试用例数量。MC/DC要求:①在一个程序中每一种输入输出至少得出现一次;②在程序中的每一个条件必须产生所有可能的输出结果至少一次;③并且每一个判定中的每一个条件必须能够独立影响一个判定的输出,即在其他条件不变的前提下仅改变这个条件的值,而使判定结果改变。MC/DC的概念有点绕,我们通过具体代码进行说明,依然
以
Example
2
代码为例:
int Example2(int a, int b){ int Result = 0; if (a < 10 || b > 10) // 判定 { return Result += 1; // 分支一 } else { return Result -= 1; // 分支二 } return Result;}
在5.3中条件覆盖达到100%的测试用例为:
TestCaes1: a = 5, b = 15 //a: true,b: true, 判定为true, Result = 1TestCaes2: a = 5, b = 5 //a: true,b: false, 判定为true, Result = 1TestCaes3: a = 15, b = 15 //a: false, b: true, 判定为true, Result = 1TestCaes4: a = 15, b = 5 //a: false, b: false, 判定为false, Result = -1
条件覆盖的表达式结果为:
TestCaes1: (True || True) True
TestCaes2: (True || False) True
TestCaes3: (False || True) True
TestCaes4: (False || False) False参考条件覆盖的测试用例,依据MCDC设计的测试用例如下:
TestCaes2: a = 5, b = 5 //a: true,b: false, 判定为true, Result = 1TestCaes3: a = 15, b = 15 //a: false, b: true, 判定为true, Result = 1TestCaes4: a = 15, b = 5 //a: false, b: false, 判定为false, Result = -1
MCDC覆盖设计的测试用例数为3个,分别覆盖的条件为TestCaes2: (True || False) TrueTestCaes3: (False || True) True
TestCaes4: (False || False) False
设计的MCDC测试用例中包含了程序输出结果1和-1,符合了①和②的要求。对比TestCase2和TestCase4,b不变,改变a,结果相反;对比TestCase3和TestCase4,a不变,改变b,结果相反,符合③的要求。因此,MC/DC覆盖率100%。
对于条件覆盖中的
Test
C
ase
1和TestCase2
,当表达式a < 10为True时,if( )的判定结果不会受第二个表达式的结果而改变,
依然会是True。
所
以
可以
忽略掉条件覆盖的
Test
C
ase
1或TestCase2中的任意一个
,实现测试用例减少的效果。
因为MC/DC在逻辑判断上包含分支覆盖,并且在条件覆盖的基础上减少了测试用例数量,所以实际应用中推荐使用MC/DC。
6 函数/模块的扇入/扇出数
度量标准:扇入/扇出数,高扇入,合理扇出(3~4,7≤)
作用:函数/模块复杂度/复用性衡量
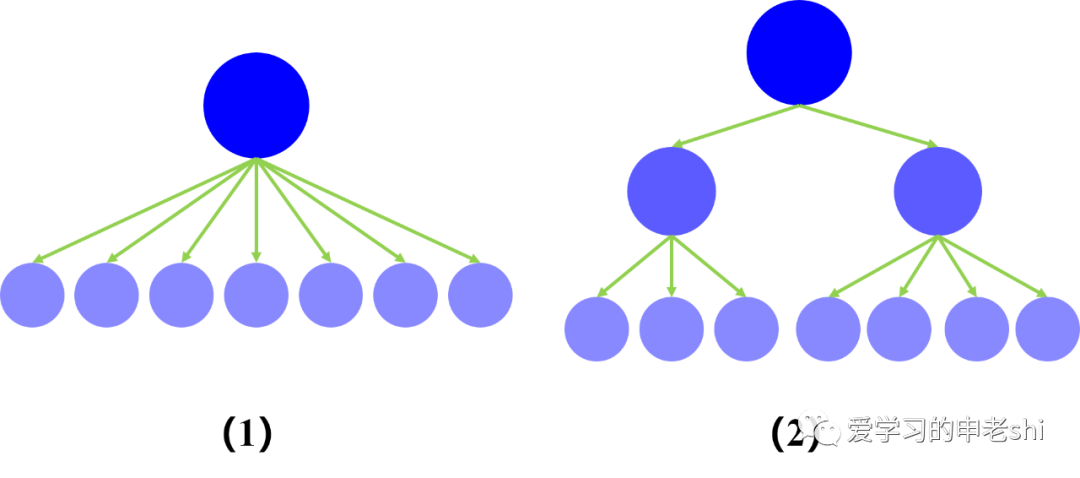
一个模块调用其他模块的个数,称为该模块的扇出。扇出越大,设计该模块时需要考虑的问题就越多,因而复杂性越高。
一个模块被其他模块调用的个数,称为该模块的扇入。扇入大些,一般不会影响问题的复杂性,而且扇入越大,说明该模块的复用性越好。
为了控制模块的复杂性,一个模块的扇出不宜过大,一般认为不要超过7。
如果发现某个模块的扇出较大(如图(1)),可以考虑重新分解(例如改为图(2)的方案)
7 设计/开发约束
软件开发中有很多设计约束和原则,其中包括:
代码的可维护性和可读性是很重要的,开发团队可以选择以上这些原则中的一个或全部,并通过一些自动化工具来遵循这些原则,这将大大提高软件产品的质量。
以上就是本期的内容,欢迎大家在评论区留言讨论~