神经网络的结构呈指数型增长的趋势,下图展示了多部分神经网络经典的拓扑结构。
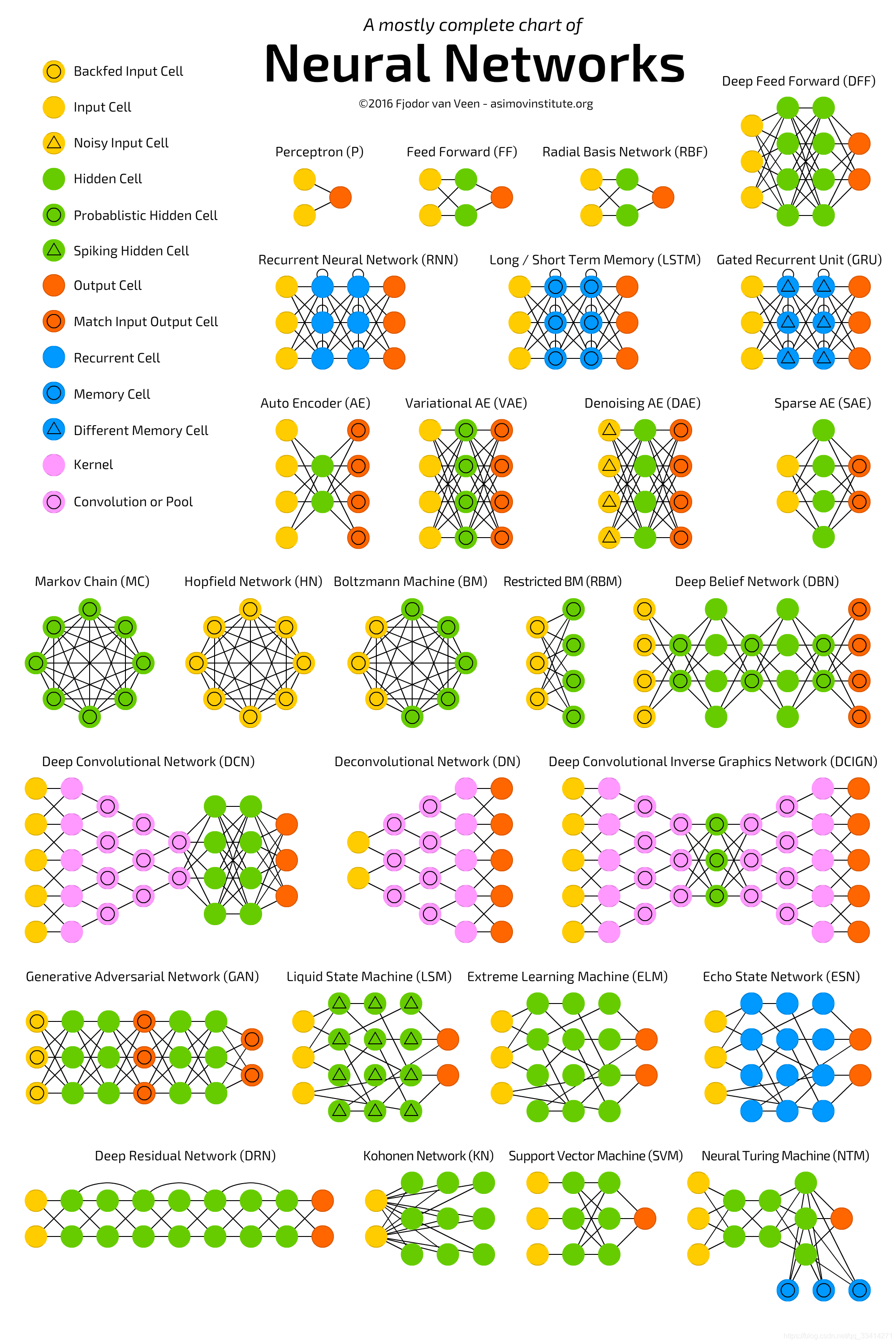
P --> FF : 增加了一层隐藏层,所有节点为全连接
FF --> RBF : 使用径向基函数(Radical Basis Function,RBF)作为激活函数,而不是逻辑函数。这使得神经网络可以处理连续的值。
FF --> DFF : 使用了多层隐藏层,开启了深度学习的纪元。
DFF --> RNN : 在神经网络中传递状态等信息,适用于上下文非常重要的情况。例如当过去的迭代或样本的决策会影响当前的决策时,常见的如文本信息。
RNN --> LSTM : LSTM引入记忆单元,可以控制信息的记录和遗忘,可以处理长依赖信息。不仅可以处理文本,还可以处理视频,语音等。
LSTM --> GRU : GRU是一种门结构不同的LSTM。与LSTM相比,它们消耗的资源更少,并且效果几乎相同。
FF --> AE : 自动编码器用于分类,聚类和特征压缩,是一种无监督学习。
AE --> VAE : 与AE相比,VAE压缩的是概率而不是特征。VAE关注的是两个事件中的连接性等问题。
AE --> DAE : AE往往只是适应输入数据(这实际上是过度拟合的一个例子)。DAE在输入单元上增加了一点噪声—通过随机位,随机切换输入中的位等方式改变数据。
AE --> SAE : 结构与AE中相同,但隐藏的单元数大于输入/输出层单元数。在某些情况下可以显示数据中某些隐藏的分组模式。
FF --> MC : 马尔可夫链是非常古老的图概念,其中每个边都有一个概率。 在过去,它们被用来构造文本,如预测下一句话。MC可以用于基于概率的分类(例如贝叶斯过滤器),聚类(某种形式)以及有限状态机。
DFF --> DCN : 引入了卷积核、池化层等操作。在图像处理领域较为常用。
DFF --> GAN : GAN代表了一个庞大的双重网络家族,它由生成器和鉴别器组成。
不同的网络拓扑结构其中的差异:
- 隐藏层
- AE和SAE中的结构信息完全相同,但中间隐藏层单元的多少决定了是对输入的压缩还是放大。
- 感知机到FF,以及FF到DFF也因为隐藏层的数量不同而不同
- 神经元
- 神经元具有多样的类型,每一种类型为不同的任务和目的而设定,由此组成了多种多样的神经网络结构
- 激活函数
模型结构判断依据