今天写爬虫的时候遇到的问题:
将抓取的数据保存下来的时候报错:TypeError: write() argument must be str, not list。字面意思是write写入的应该是str类型的数据,而不是一个list类型的数据,回到代码中
for i in range(0,num):
try:
title1 = title1_list[i].replace("】","")
title2 = title2_list[i].replace("\n","")
name1 = title1 + title2
product_dict = {
"product_name": name1,
"product_id": product_id_list[i]
}
product_list.append(product_dict)
except:
pass
print("保存的数据为:",product_list)
product_list = json.dumps(product_list,ensure_ascii=False,indent=2)
return pages,product_list
检查发现保存前已经使用dumps转化格式了,那为什么还是会显示保存的是列表呢,保存之前的数据打印一下保存的数据看一下发现了原因
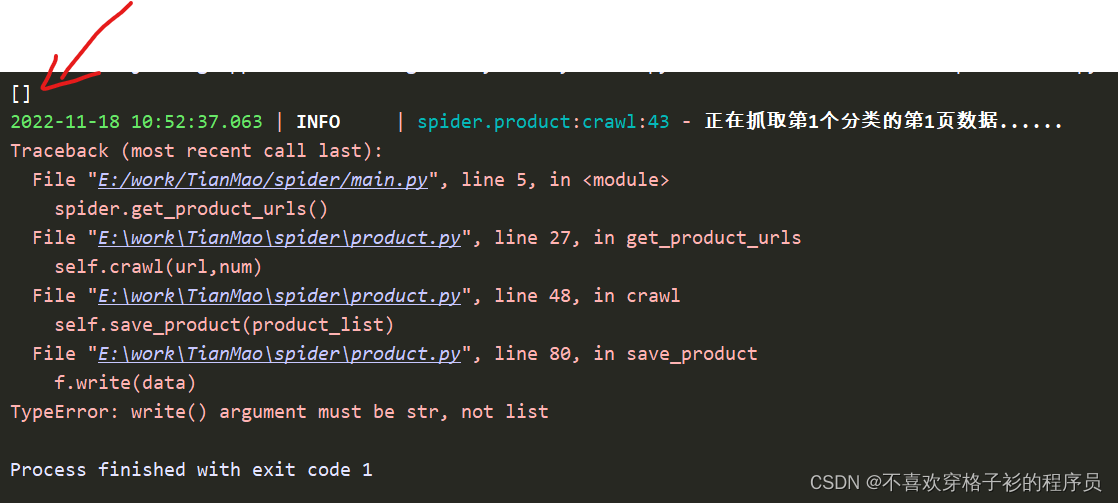
获取到的数据为空,所以才没有保存数据。找到问题所在解决起来就很轻松了,只要加入一个判断的条件,判断抓取的数据是否为空就可以了,代码如下:
data = self.product_html
# print(data)
data = etree.HTML(data)
#商品数量
try:
product_num = data.xpath('//*[@id="content"]/div[1]/div/div[1]/p/em/text()')[0]
except:
# 出现滑块,需要拖动滑块
drop_block = DropBlock()
drop_block.drop_block(url)
product_num = data.xpath('//*[@id="content"]/div[1]/div/div[1]/p/em/text()')[0]
if int(product_num) == 0:
pages = 0
list1 = {
"product_name": "Null",
"product_id": "Null"
}
list1 = json.dumps(list1,ensure_ascii=False,indent=2)
return pages,list1
首先获取到商品详情页的数据是否为0,这是唯一可以辨别商品数据为空的数据,因为空数据的页数也会显示为1,所以这里采用商品数量作为判断商品数量是否为空的依据

所以现在只需要在保存数据前加入判断的条件就可以了。将空的列表替换成指定的数据,这样就不会造成空列表保存不了的情况了,最后记得返回空的数据之前也要使用dumps转化哦