回归就是输出值是连续的而不是离散的,如果是离散值,就是分类问题。
1、线性回归:
(1)定义
\给定数据集D={(x1,y1),(x2,y2)...},线性回归尝试学习到一个线性模型,尽可能地输出正确标记。
线性回归无非就是在N维空间中找一个形式像直线方程一样的函数来拟合数据而已。比如说,横坐标代表房子的面积,纵坐标代表房价。线性回归就是要找一条直线,并且让这条直线尽可能地拟合图中的数据点。找直线的过程就是在做线性回归。

(2)损失函数
既然是找直线,那肯定是要有一个评判的标准,来评判哪条直线才是最好的。只要算一下实际房价和我找出的直线根据房子大小预测出来的房价之间的差距就行了。说白了就是算两点的距离,用欧式距离计算两点之间的距离,并对所有样本的距离进行加和

在ML中称它为损失函数(就是计算误差的函数)。那有了这个函数,我们就相当于有了一个评判标准,当这个函数的值越小,就越说明我们找到的这条直线越能拟合我们的房价数据。所以说啊,线性回归无非就是通过这个损失函数做为评判标准来找出一条直线。
参考地址:https://blog.csdn.net/alw_123/article/details/82193535
2、逻辑回归:
(1)逻辑回归不是回归,逻辑回归就是用回归来做二分类任务
前面说到,回归任务是结果为连续型变量的任务,logistics regression是用来做分类任务的,为什么叫回归呢?
其实,逻辑回归就是用回归的办法来做分类的,它将回归值y放入sigmoid函数中,输出值在 0 到 1 之间,表示样本类别的概率。
(2)定义
逻辑回归基于概率理论,比如回归函数为 y=wx+b,逻辑回归会将回归值 y 放入sigmoid函数中,映射成0 - 1之间的值。它的输出可以看作是样本为正类的概率,选定阈值,大于这个阈值我们就认为它是正类。它可以通过极大似然估计的方法估计出最可能的参数的值。
sigmoid函数可以点击链接:https://blog.csdn.net/qq_32172681/article/details/97936956
逻辑回归为什么使用sigmoid?https://blog.csdn.net/qq_32172681/article/details/101080628
极大似然估计点击链接:https://blog.csdn.net/qq_32172681/article/details/98037944
3、逻辑回归损失函数及其推导过程
参考地址:https://blog.csdn.net/weixin_41537599/article/details/80585201#commentsedit
函数定义:
推导过程如下:
假定输入样本x,用y^表示训练样本x条件下预测y=1的概率,用1-y^表示训练样本x条件下预测y=0的概率,即:
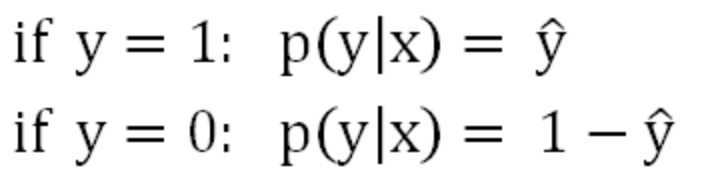
把这两个公式合并成一个公式,在y=1时公式右边等于y^,在y=1时公式右边等于1-y^。

由于log函数是严格递增函数,所以最大化log等价于最大化原函数,上式因此可以化简为损失函数的负数。即:
 (公式中间是加号)
(公式中间是加号)
用极大似然估计求解参数,所以最大化似然函数就是最小化损失函数,由于似然函数是联合概率密度函数,对于m个样本的整个训练集,服从独立同分布的样本的联合概率(似然函数)就是每个样本的概率的乘积:

这个函数就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数。

4、求解交叉熵损失函数
参考:https://blog.csdn.net/weixin_39445556/article/details/83930186
求解损失函数的办法我们还是使用梯度下降。
求解步骤如下:
- 随机一组W
- 将W带入交叉熵损失函数,让得到的点沿着负梯度的方向移动
- 循环第二步
求解梯度部分同样是对损失函数求偏导,过程如下:
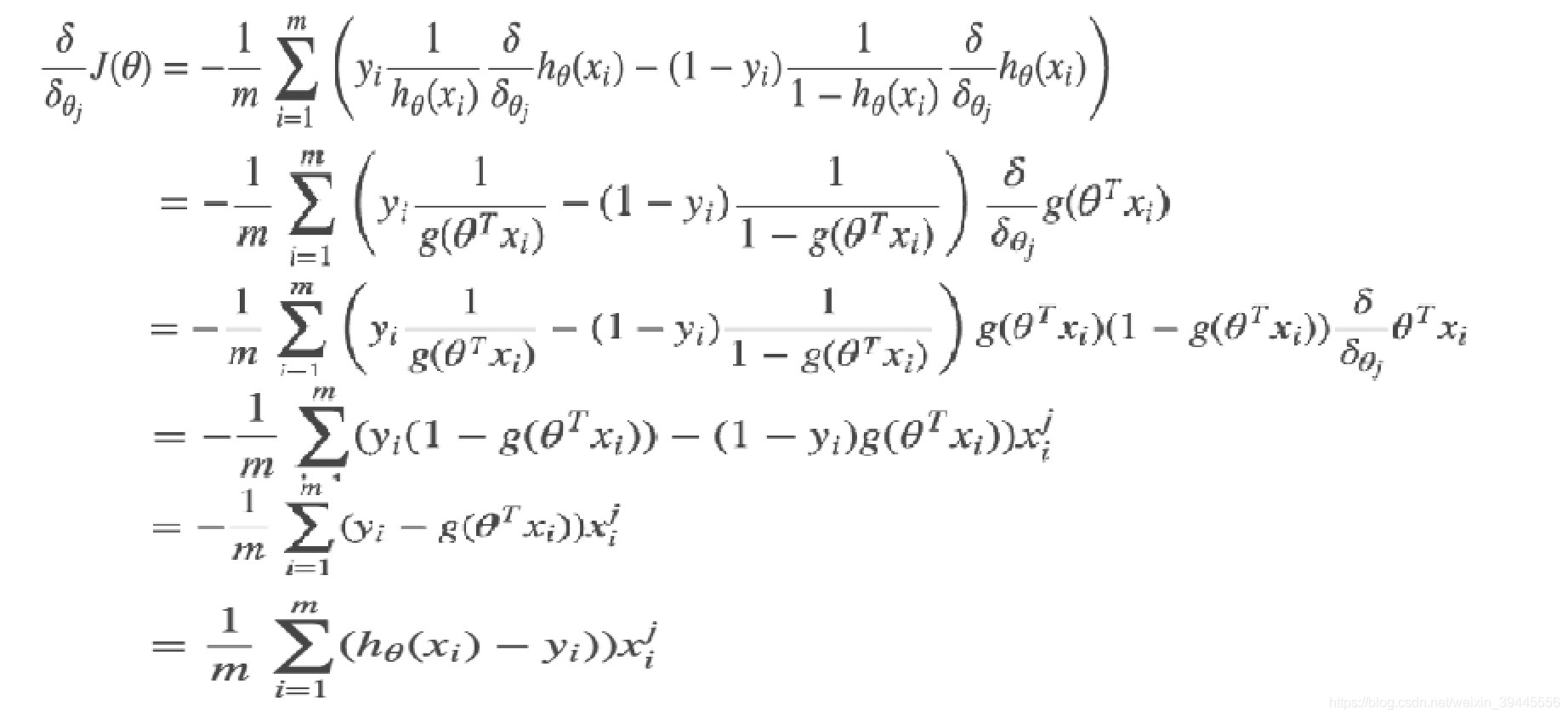
交叉熵损失函数的梯度和最小二乘的梯度形式上完全相同,区别在于,此时的  ,而最小二乘的
,而最小二乘的  。
。
梯度下降推导过程:https://blog.csdn.net/weixin_39445556/article/details/83661219
5、逻辑回归中的参数估计
对于有标签数据而言,就是已知结果值y,求可以得到这个正确结果的最可能的参数w,最先想到的就是最大似然估计。最大似然估计可以点击链接:https://blog.csdn.net/qq_32172681/article/details/98037944
6、逻辑回归举例
参考地址:https://baijiahao.baidu.com/s?id=1628902000717534995&wfr=spider&for=pc
以下为研究一个学生优秀还是差等的问题,已知训练数据的学生基本特征信息如下:

需要预测分类的学生数据如下:

(1)数据归一化处理,方便训练,且将评级优表示为1,评级差表示为0,原数据表示为:

(2)假设使用的网络模型为:
设置参数初始值为(0.5,0.5,0.5,0.5),计算损失函数。设置学习率为0.3,并且当损失函数为0.1时,迭代停止截止。
(3)第一次迭代的值为(-0.096,0.50008,-0.32,0.350858),不断迭代,直到损失函数小于0.1。
(4)最终确定参数的值和网络模型Y(x)的表达式,计算待预测数据的值:
