无监督学习:聚类,分类
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)

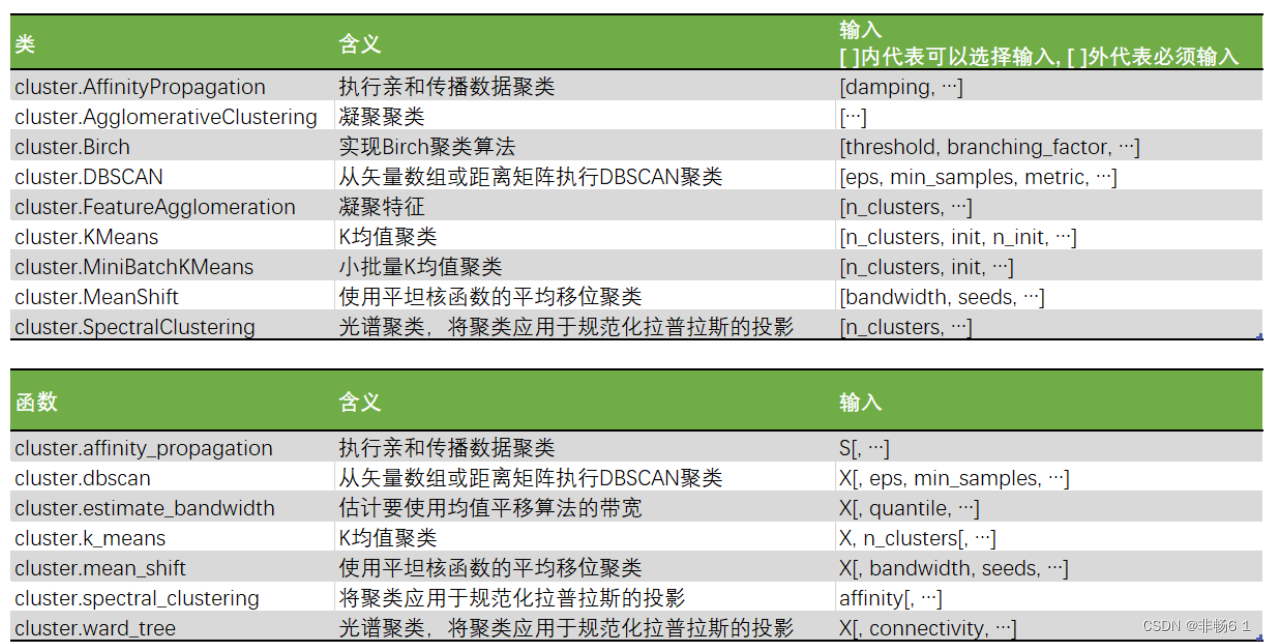
sklearn当中的聚类算法
有两种表现形式:类、函数
KMeans是如何工作的


重要参数n_clusters
n_clusters是KMeans中的k,表示着我们告诉模型我们要分几类。这是KMeans当中唯一一个必填的参数,默认为8 类,但通常我们的聚类结果会是一个小于8的结果。通常,在开始聚类之前,我们并不知道n_clusters究竟是多少, 因此我们要对它进行探索。
#创建一个数据集
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
#自己创建数据集
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]
,marker='o' #点的形状
,s=8 #点的大小
)
plt.show()
#如果我们想要看见这个点的分布,怎么办?
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
plt.show()
#基于这个分布,我们来使用Kmeans进行聚类
from sklearn.cluster import KMeans
n_clusters = 3
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
y_pred = cluster.labels_
y_pred
pre = cluster.fit_predict(X)
pre == y_pred
cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:200])
y_pred_ = cluster_smallsub.predict(X)
y_pred == y_pred_
centroid = cluster.cluster_centers_
centroid
centroid.shape
inertia = cluster.inertia_
inertia
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred==i, 0], X[y_pred==i, 1]
,marker='o'
,s=8
,c=color[i]
)
ax1.scatter(centroid[:,0],centroid[:,1]
,marker="x"
,s=15
,c="black")
plt.show()
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
n_clusters = 5
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
n_clusters = 6
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
案例:轮廓系数找最佳n_clusters
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
n_clusters = 4
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
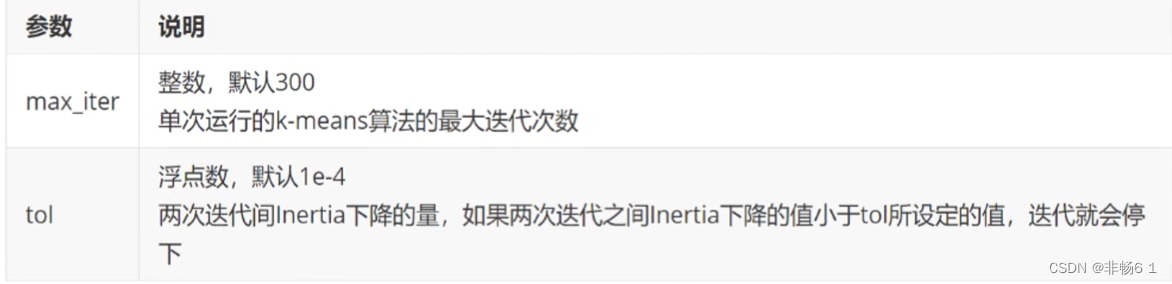
重要参数init & random_state & n_init:让初始质心放好
重要参数max_iter & tol:让迭代停下来
案例:Kmeans做矢量量化
非结构化数据往往占用比较 多的储存空间,文件本身也会比较大,运算非常缓慢,我们希望能够在保证数据质量的前提下,尽量地缩小非结构 化数据的大小,或者简化非结构化数据的结构。矢量量化就可以帮助我们实现这个目的。即压缩大小
#导入需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin
from sklearn.datasets import load_sample_image
from sklearn.utils import shuffle
#导入数据,探索数据
china = load_sample_image("china.jpg")
china
china.dtype
china.shape
china[0][0]
newimage = china.reshape((427 * 640,3))
import pandas as pd
pd.DataFrame(newimage).drop_duplicates().shape
plt.figure(figsize=(15,15))
plt.imshow(china)
flower = load_sample_image("flower.jpg")
plt.figure(figsize=(15,15))
plt.imshow(flower)
#决定超参数,数据预处理
n_clusters = 64
china = np.array(china, dtype=np.float64) / china.max()
w, h, d = original_shape = tuple(china.shape)
assert d == 3
image_array = np.reshape(china, (w * h, d))
china = np.array(china, dtype=np.float64) / china.max()
w, h, d = original_shape = tuple(china.shape)
w
h
d
assert d == 3
d_ = 5
assert d_ == 3, "一个格子中的特征数目不等于3种"
image_array = np.reshape(china, (w * h, d))
image_array
image_array.shape
a = np.random.random((2,4))
a
a.reshape((4,2))
np.reshape(a,(4,2))
np.reshape(a,(2,2,2))
np.reshape(a,(3,2))
#对数据进行K-Means的矢量量化
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
kmeans.cluster_centers_
labels = kmeans.predict(image_array)
labels.shape
image_kmeans = image_array.copy()
for i in range(w*h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans
pd.DataFrame(image_kmeans).drop_duplicates().shape
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shape
#对数据进行随机的矢量量化
centroid_random = shuffle(image_array, random_state=0)[:n_clusters]
labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0)
labels_random.shape
len(set(labels_random))
image_random = image_array.copy()
for i in range(w*h):
image_random[i] = centroid_random[labels_random[i]]
image_random = image_random.reshape(w,h,d)
image_random.shape
# 将原图,按KMeans矢量量化和随机矢量量化的图像绘制出来
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(image_kmeans)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(image_random)
plt.show()