均值滤波的应用场合: 根据冈萨雷斯书中的描述,均值模糊可以模糊图像以便得到感兴趣物体的粗略描述,也就是说,去除图像中的不相关细节,其中“不相关”是指与滤波器模板尺寸相比较小的像素区域,从而对图像有一个整体的认知。即为了对感兴趣的物体得到一个大致的整体的描述而模糊一幅图像,忽略细小的细节。 均值滤波的缺陷: 均值滤波本身存在着固有的缺陷,即它不能很好地保护图像细节,在图像去噪的同时也破坏了图像的细节部分,从而使图像变得模糊,不能很好地去除噪声点。特别是椒盐噪声。 均值滤波是上述方框滤波的特殊情况,均值滤波方法是:对待处理的当前像素,选择一个模板,该模板为其邻近的若干个像素组成,用模板的均值(方框滤波归一化)来替代原像素的值。公式表示为:
g
(
x
,
y
)
=
1
/
n
∑
I
∈
N
e
i
g
h
b
o
u
r
I
(
x
,
y
)
g(x, y)=1 / n \sum_{I \in N e i g h b o u r} I(x, y)
g(x,y)=1/nI∈Neighbour∑I(x,y)g(x,y)为该邻域的中心像素,n跟系数模版大小有关,一般3*3邻域的模板,n取为9,如:
[
1
1
1
1
1
1
1
1
1
]
\left[\begin{array}{lll} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right]
⎣⎡111111111⎦⎤当然,模板是可变的,一般取奇数,如5 * 5 , 7 * 7等等。 注:在实际处理过程中可对图像边界进行扩充,扩充为0或扩充为邻近的像素值。
高斯滤波
应用: 高斯滤波是一种线性平滑滤波器,对于服从正态分布的噪声有很好的抑制作用。在实际场景中,我们通常会假定图像包含的噪声为高斯白噪声,所以在许多实际应用的预处理部分,都会采用高斯滤波抑制噪声,如传统车牌识别等。 高斯滤波和均值滤波一样,都是利用一个掩膜和图像进行卷积求解。不同之处在于:均值滤波器的模板系数都是相同的为1,而高斯滤波器的模板系数,则随着距离模板中心的增大而系数减小(服从二维高斯分布)。所以,高斯滤波器相比于均值滤波器对图像个模糊程度较小,更能够保持图像的整体细节。 二维高斯分布 高斯分布公式终于要出场了!
f
(
x
,
y
)
=
1
(
2
π
σ
)
2
e
−
(
(
x
−
u
x
)
2
+
(
y
−
u
y
)
2
)
/
2
σ
2
f(x, y)=\frac{1}{(\sqrt{2 \pi} \sigma)^{2}} e^{-\left((x-u x)^{2}+(y-u y)^{2}\right) / 2 \sigma^{2}}
f(x,y)=(2πσ)21e−((x−ux)2+(y−uy)2)/2σ2 其中不必纠结于系数,因为它只是一个常数!并不会影响互相之间的比例关系,并且最终都要进行归一化,所以在实际计算时我们是忽略它而只计算后半部分:
f
(
x
,
y
)
=
e
−
(
(
x
−
u
x
)
2
+
(
y
−
u
y
)
2
)
/
2
σ
2
f(x, y)=e^{-\left((x-u x)^{2}+(y-u y)^{2}\right) / 2 \sigma^{2}}
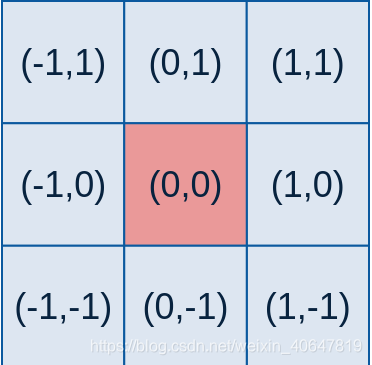
f(x,y)=e−((x−ux)2+(y−uy)2)/2σ2 其中(x,y)为掩膜内任一点的坐标,(ux,uy)为掩膜内中心点的坐标,在图像处理中可认为是整数;σ是标准差。 例如:要产生一个3×3的高斯滤波器模板,以模板的中心位置为坐标原点进行取样。模板在各个位置的坐标,如下所示(x轴水平向右,y轴竖直向下)。 这样,将各个位置的坐标带入到高斯函数中,得到的值就是模板的系数。 对于窗口模板的大小为 (2k+1)×(2k+1),模板中各个元素值的计算公式如下:
H
i
,
j
=
1
2
π
σ
2
e
−
(
i
−
k
−
1
)
2
+
(
j
−
k
−
1
)
2
2
σ
2
H_{i, j}=\frac{1}{2 \pi \sigma^{2}} e^{-\frac{(i-k-1)^{2}+(j-k-1)^{2}}{2 \sigma^{2}}}
Hi,j=2πσ21e−2σ2(i−k−1)2+(j−k−1)2 这样计算出来的模板有两种形式:小数和整数。
src — input image; the image can have any number of channels, which are processed independently, but the depth should be CV_8U, CV_16U, CV_16S, CV_32F or CV_64F.
dst — output image of the same size and type as src.
ksize Gaussian kernel size. ksize.width and ksize.height can differ but they both must be positive and odd. Or, they can be zero’s and then they are computed from sigma.
sigmaX — Gaussian kernel standard deviation in X direction.
sigmaY — Gaussian kernel standard deviation in Y direction; if sigmaY is zero, it is set to be equal to sigmaX, if both sigmas are zeros, they are computed from ksize.width and ksize.height, respectively (see cv::getGaussianKernel for details); to fully control the result regardless of possible future modifications of all this semantics, it is recommended to specify all of ksize, sigmaX, and sigmaY.
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。