目录
1.1简单动态字符串(SDS):
1.2链表
1.3字典(符号表、关联数组、映射)
1.3.1字典的实现
1.4跳跃表
1.5整数集合
1.6压缩列表
1.7对象
1.7.1对象的类型与编码
1.7.2字符串对象
1.7.3列表对象
1.7.4哈希对象
1.7.5集合对象
1.7.6有序集合对象
1.7.7类型检查与命令多态
1.7.8内存回收
1.7.9对象共存
1.7.10对象的空转时长

1.1简单动态字符串(SDS):
1、redis构建了一种名为简单动态字符串得抽象类型,并用此作为redis默认的字符串表示。
2、C字符串只会在redis中最为字符串字面量(无需修改的地方)
3、SDS遵循C字符串以空字符串结尾的惯例,保存空字符的一字节空间不算在SDS的len属性里面;遵循空字节符结尾的好处是可以直接用C字符串函数库的函数(例如复制、对比等)
4、SDS跟C字符串的区别:
- SDS结构中又专门记录SDS字符串的属性,所以可以在常数复杂度获取字符串长度
- SDS字符串可以防止缓冲区溢出。与C字符串不同的是,当需要对SDS进行修改的时候,API会先检查SDS的空间是否满足修改的需求,如果不满足的话API会自动将SDS空间孔容。(扩容规则:如果修改之后SDS的长度,也就是len属性的值小于1MB,纳闷程序分配和len属性同样大小的未使用空间;反之,程序则分配1MB的未使用空间)

- 二进制安全。redis的buf数组是用来保存一些列二进制数据的。
1.2链表
链表在redis的应用非常广泛,列表键的底层实现之一就是链表,当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,redis就会使用链表作为列表键的底层实现:
- 链表的节点结构:

- list结构:用list结构来持有链表操作会更方便



1.3字典(符号表、关联数组、映射)
一种用于保存键值对的数据结构。字典中的每个键都是独一无二的。redis的数据库就是用字典来实现的、哈希键的实现(包含的键值对比较对、键值对中的元素都是比较长的字符串)之一也是字典。
1.3.1字典的实现
- 字典使用哈希表作为底层实现,哈希表中有多个哈希节点,每个哈希节点保存字典中的一个键值对
- 哈希表:
 属性定义:table是一个数组,数组中的每个元素都指向一个哈希节点的指针;size的记录哈希表的大小(即他变了数组的大小)。sizemask等于size-1,用于计算键值对在哈希表上的位置。
属性定义:table是一个数组,数组中的每个元素都指向一个哈希节点的指针;size的记录哈希表的大小(即他变了数组的大小)。sizemask等于size-1,用于计算键值对在哈希表上的位置。
- 哈希表节点:
 key保存的时键值对中的键,v保存的是值。因为这个哈希表用的是链地址法来解决冲突,所以next属性指向的是下一个哈希节点。
key保存的时键值对中的键,v保存的是值。因为这个哈希表用的是链地址法来解决冲突,所以next属性指向的是下一个哈希节点。
- 字典结构:



- 哈希算法:

- rehash:

- 哈希表的扩展与收缩:

- 渐进式rehash:rehash动作不是一次性集中式的完成的,而是分多次、渐进式的完成的,因为如果ht[0]数组中报错的键值对是超大数据的时候,一次性的完成会导致服务器停止服务。


1.4跳跃表
redis使用跳跃表作为有序集合键的底层实现之一(有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时)
- 有序表的实现


- 跳跃表节点







- 跳跃表:


1.5整数集合
整数集合时集合键的底层实现之一(当一个集合只包含整数值的元素,并且这个集合的元素数量不多时)
- 整数集合的实现


- 升级:当一个新元素添加到整数集合里面,并且新元素比整数集合现有所有的元素类型都要长的时候,就要进行升级,才能将新元素添加到整数集合里面。升级分为步:1、根据新元素类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。2、将底层数组原有的元素全部转换成新元素相同类型,并将元素放到正确的位置上。3、将新元素放到底层数组里面


- 降级:整数集合不支持降级操作
1.6压缩列表
压缩列表是列表键和哈希键的底层实现之一(只包含少量的列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串)
- 压缩列表的构成


- 压缩列表节点构成




- 连锁更新

1.7对象
redis对象系统:字符串对象、列表对象、哈希对象、集合对象、有序集合对象,每个对象都用到了至少一种前面提到的数据结构。对象系统实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占的内存就会被自动释放。通过引用计数技术实现对象的共享机制,让多个数据库键共享一个对象来节约内存。最后,数据库对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时间,在开启maxmemory功能的情况下,服务器可能会优先删除空转时间长的键。
1.7.1对象的类型与编码
每一次在数据库中新建一个数据库都会创建至少两个对象,分别就是键值。



1.7.2字符串对象

如果是整数值且可以用long表示,那么会编码为int;如果是一个字符串值并且长度大于39字节,那么采用raw编码;如果长度小于等于39字节采用embstr编码。 

对于Int编码来说,如果使得这个对象保存的不再是整数值而是一个字符串,那么字符串对象的编码会从Int变成raw。embstr编码的字符串对象是只读的,当对embstr编码的字符串执行修改命令时,程序会先将字符串改成raw,再执行修改命令。 
1.7.3列表对象
列表对象的编码可以是ziplist或者linkedlist。
如果采用ziplist编码: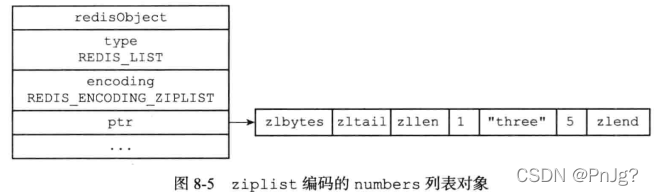


编码转换:


1.7.4哈希对象
哈希对象编码可以是ziplist或者hashtable





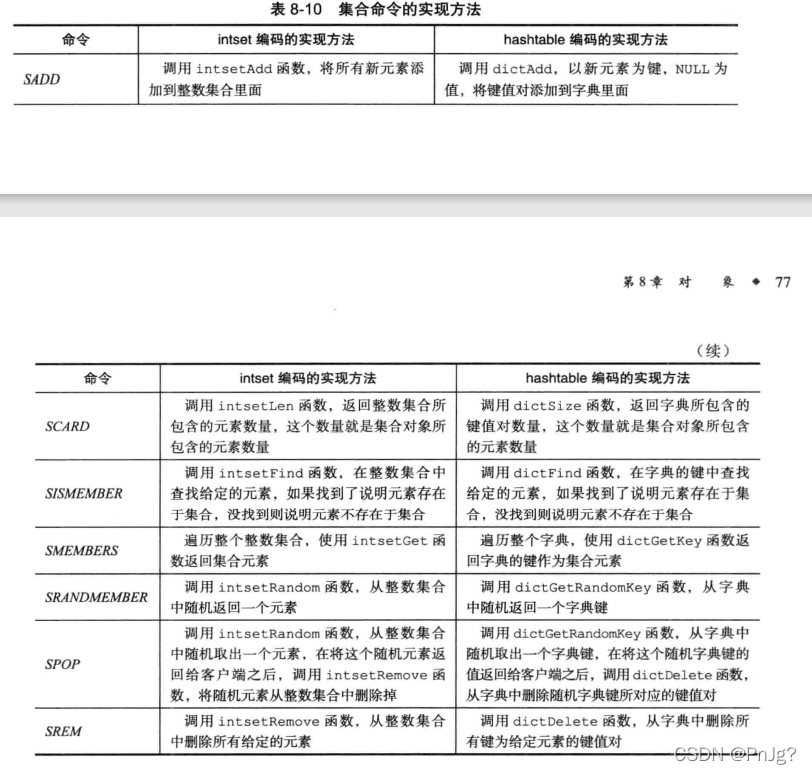
1.7.5集合对象
集合对象的编码可以是intset或者是hashset



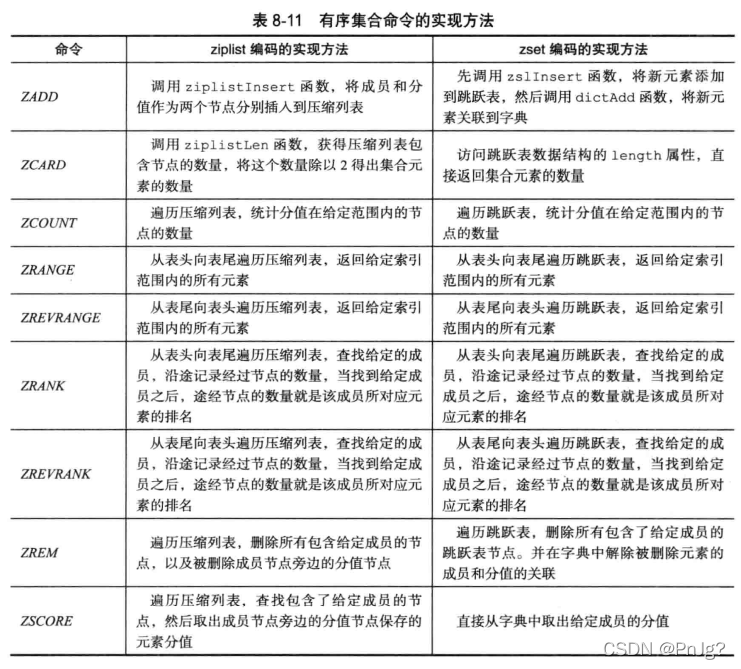
1.7.6有序集合对象
有序集合的编码可以是ziplist或者是skiplist
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zet结构同时包含一个字典和一个跳跃表:
typedef sruct zset{
zskiplist *zsl;
dict *dict;
} zset



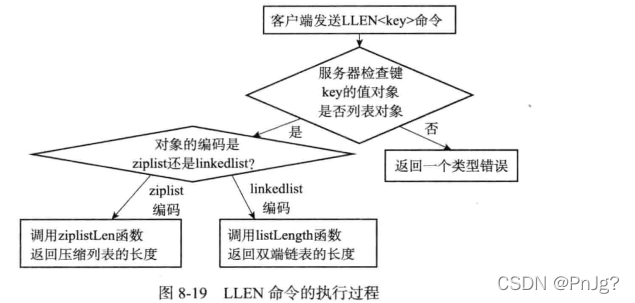
1.7.7类型检查与命令多态





1.7.8内存回收

1.7.9对象共存




1.7.10对象的空转时长
