首先创建测试环境
创建数据库表并加入数据
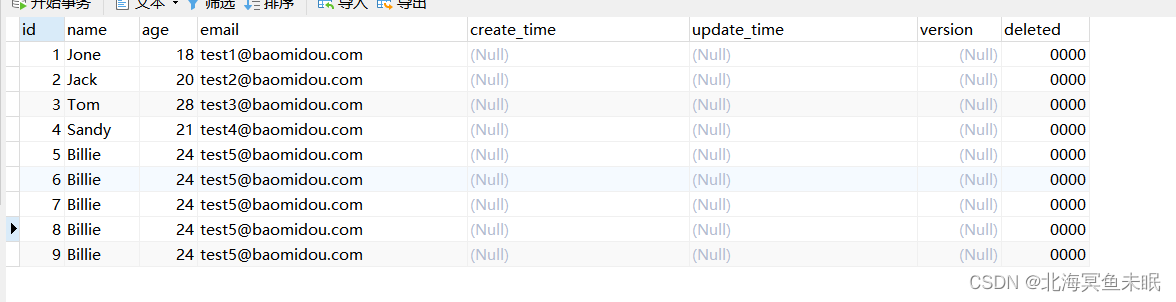
接下来研究如何做到删除重读的数据行并且仅保留第一条id最小的记录。
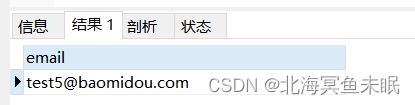
- 首先需要知道哪一列是重复的,所以首先筛选出重复的列
select email from user group by email having count(email)>1 #查询表中重复的列数据
查询的结果是email为test5的
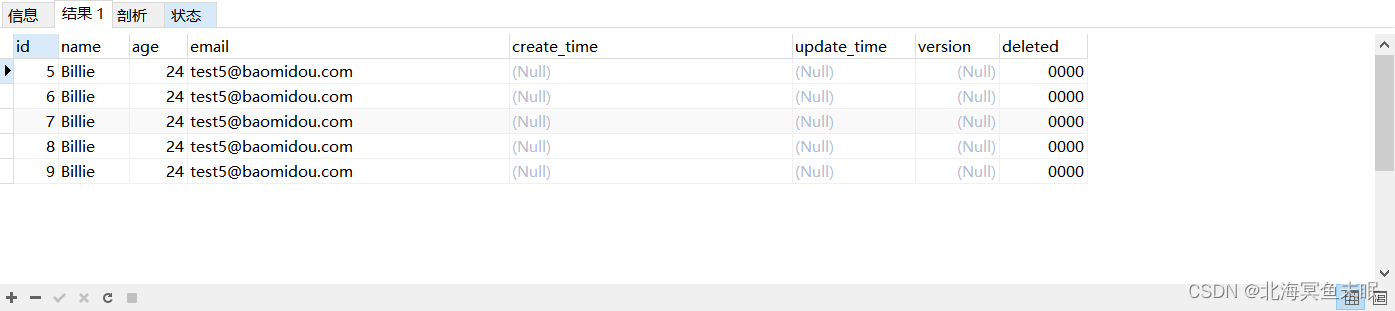
- 然后查询重复的列对应的数据行的所有记录
select * from user where email in(select email from user group by email having count(email)>1)#查询表中重复列对应行的所有数据
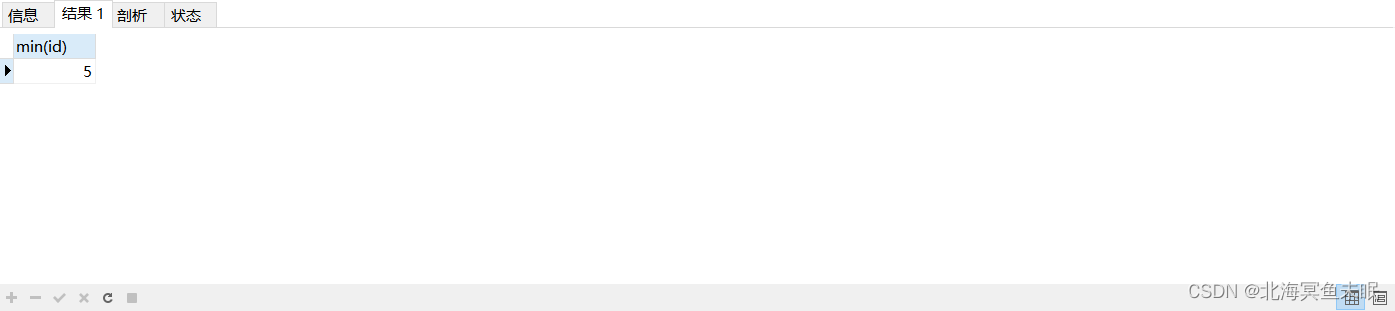
- 然后我们需要筛选出id最小的,以便于后面去除的时候可以保留id最小的
select min(id) from (select * from user where email in(select email from user group by email having count(email)>1)) t #找到所有的重读列中id最小的DELETE
- 最后删除重复的数据行并且保留最小的
FROM `user` WHERE email IN ( SELECT t.email FROM (( SELECT email FROM `USER` GROUP BY email HAVING count( email )> 1 ) t
))
AND id NOT IN (
SELECT
aaa.id
FROM
(
SELECT
min( id ) AS id
FROM
(
SELECT
id
FROM
`USER`
WHERE
`USER`.email IN ( SELECT email FROM `USER` GROUP BY email HAVING count( email )> 1 )) s
) aaa
)
另外这个sql里面涉及到中间表的查询,也就是我中间又进行了一些select,这是因为MySQL中You can't specify target table for update in FROM clause错误的意思是说,不能先select出同一表中的某些值,再update这个表(在同一语句中)
大家参考这个。因此我上面的sql这样写即可。
总体的步骤如下:
1: 找到重复的数据
2:取出重复数据的数据行所有字段值
3:在所有的重复的数据中分组取出id最小的
4:删除属于重复的数据集合并且id不是最小值的id集合里面的数据