前言`
本文仅用selenium爬取求职信息,记录selenium的尝试和使用
使用步骤
1.引入库
本代码仅仅使用selenium库和time库来操作,无其他数据处理操作
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
2.引入谷歌内核以及定位打开页面
代码如下(示例):
#谷歌内核
path="D:\Google\Chrome\Application\chromedriver.exe"
driver=webdriver.Chrome(executable_path=path)
#调窗口至全屏大小
driver.maximize_window()
#打开页面
driver.get('https://www.zhipin.com/zhengzhou/?sid=sem_pz_360pc_title')
sleep(3)
3.使用selenium控制浏览器页面搜索需要信息
以数据分析师为例
search = driver.find_element(By.XPATH,'//*[@id="wrap"]/div[3]/div/div[1]/div[1]/form/div[2]/p/input')
search.send_keys("数据分析师")
sleep(2)
submit = driver.find_element(By.XPATH,'//*[@id="wrap"]/div[3]/div/div[1]/div[1]/form/button')
submit.click()
print('搜索结束,开始寻找信息')
driver.implicitly_wait(5)
sleep(3)
4.定位到所需要的li标签
我们所需要的是各种招聘类信息,所以先进入页面寻找定位标签
先通过class定位到装有信息的li标签
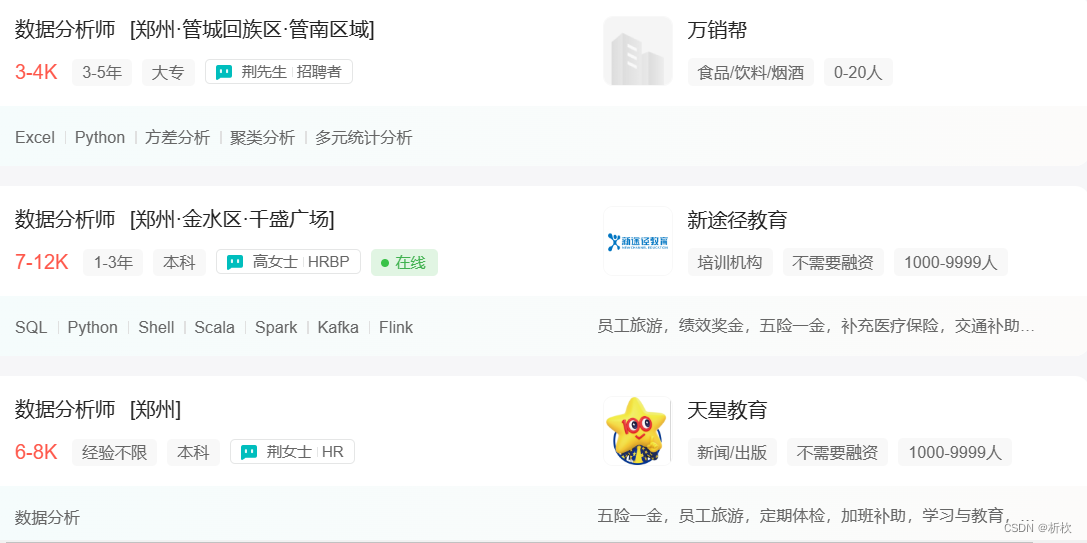
lis = driver.find_elements(By.CSS_SELECTOR,'.job-card-wrapper')
print('定位完成')
5.从li标签中提取信息
因为li标签不止一个,所以我们需要采用循环一次提取并输出
for li in lis:
jobname = li.find_element(By.CSS_SELECTOR, '.job-name').text
print(jobname)
info_data = li.find_element(By.CSS_SELECTOR, '.job-card-left').get_attribute('href')
print(info_data)
jobarea = li.find_element(By.CSS_SELECTOR, '.job-area').text
print(jobarea)
slary = li.find_element(By.CSS_SELECTOR, '.salary').text
print(slary)
print('工作名字:' + jobname + ' 工作场所:', jobarea + ' 工资:' + slary + ' 详细链接:' + info_data)
print('\n')
总结
selenium的自动化操作页面目前技术有限,仅能先进行爬取,而自动化技术难以实现
不过我在爬取过程中却老是出现搜索后页面不断刷新,难以定位到li标签然后直接退出的问题,如果遇到,现在我能做到的仅为多尝试几次,看运气了。
源码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#BOSS直聘
#谷歌内核
path="D:\Google\Chrome\Application\chromedriver.exe"
driver=webdriver.Chrome(executable_path=path)
#调窗口至全屏大小
driver.maximize_window()
#打开页面
driver.get('https://www.zhipin.com/zhengzhou/?sid=sem_pz_360pc_title')
sleep(3)
search = driver.find_element(By.XPATH,'//*[@id="wrap"]/div[3]/div/div[1]/div[1]/form/div[2]/p/input')
search.send_keys("数据分析师")
sleep(2)
submit = driver.find_element(By.XPATH,'//*[@id="wrap"]/div[3]/div/div[1]/div[1]/form/button')
submit.click()
print('搜索结束,开始寻找信息')
driver.implicitly_wait(5)
sleep(3)
# #
lis = driver.find_elements(By.CSS_SELECTOR,'.job-card-wrapper')
print('定位完成')
for li in lis:
jobname = li.find_element(By.CSS_SELECTOR, '.job-name').text
print(jobname)
info_data = li.find_element(By.CSS_SELECTOR, '.job-card-left').get_attribute('href')
print(info_data)
jobarea = li.find_element(By.CSS_SELECTOR, '.job-area').text
print(jobarea)
slary = li.find_element(By.CSS_SELECTOR, '.salary').text
print(slary)
print('工作名字:' + jobname + ' 工作场所:', jobarea + ' 工资:' + slary + ' 详细链接:' + info_data)
print('\n')
driver.quit()
最终爬取效果如下
