点击上方蓝字,关注并星标,和我一起学技术。

今天是pandas数据处理专题第三篇文章,我们来聊聊DataFrame中的索引。
上篇文章当中我们简单介绍了一下DataFrame这个数据结构的一些常见的用法,从整体上大概了解了一下这个数据结构。今天这一篇我们将会深入其中索引相关的应用方法,了解一下DataFrame的索引机制和使用方法。
数据准备
上一篇文章当中我们了解了DataFrame可以看成是一系列Series组合的dict,所以我们想要查询表中的某一列,也就是查询某一个Series,我们只需要像是dict一样传入key值就可以查找了。但是,如果我们想要查找某一行应该怎么办?难道手动去遍历每一列么?这显然是不现实的。
所以DataFrame当中也为我们封装了现成的行索引的方法,行索引的方法一共有两个,分别是loc,iloc。这两种方法都可以查询某一行,只是查询的参数不同,本质上没有高下之分,大家可以自由选择。
首先,我们还是用上次的方法来创建一个DataFrame用来测试:
data = {'name': ['Bob', 'Alice', 'Cindy', 'Justin', 'Jack'], 'score': [199, 299, 322, 212, 311], 'gender': ['M', 'F', 'F', 'M', 'M']}
df = pd.DataFrame(data)
loc
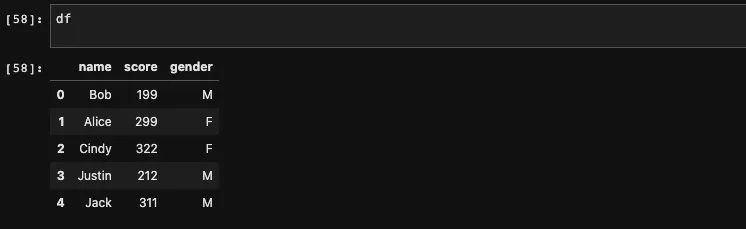
首先我们来介绍loc,loc方法可以根据传入的行索引查找对应的行数据。注意,这里说的是行索引,而不是行号,它们之间是有区分的。行索引其实对应于Series当中的Index,也就是对应Series中的索引。所以我们一般把行索引称为Index,而把列索引称为columns。
我们在之前的文章当中了解过,对于Series来说,它的Index可以不必是整数,也可以拥有重复元素。当然如果我们不指定的话,它会和行号一样,都是整数:
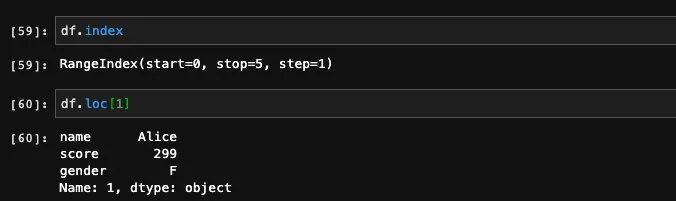
我们可以手动修改df的index,来看看当行索引不是整数的时候,是不是也一样生效。
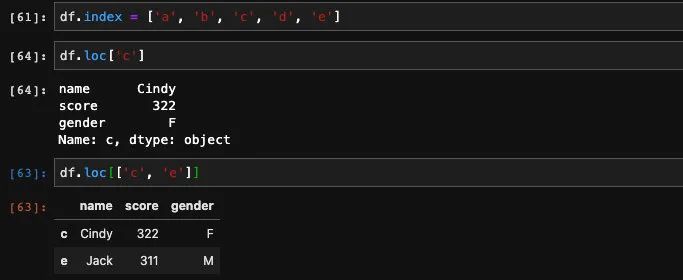
可以明显看出来是生效的,而且我们也可以传入一个索引数组来查询多行。
不仅如此,loc方法也是支持切片的,也就是说虽然我们传进的是一个字符串,但是它在原数据当中是对应了一个位置的。我们使用切片,pandas会自动替我们完成索引对应位置的映射。
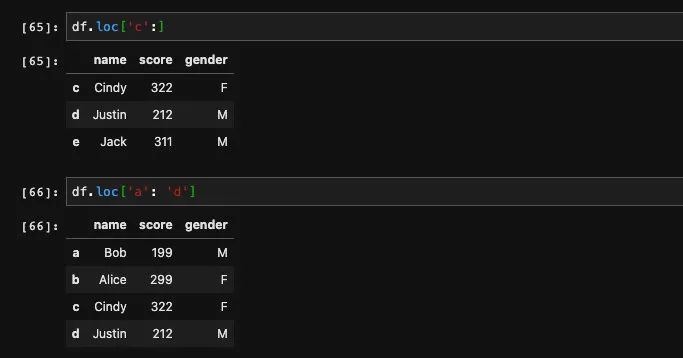
但是索引对应的切片出来的结果是闭区间,这一点和Python通常的切片用法不同,需要当心。
另外,loc是支持二维索引的,也就是说我们不但可以指定行索引,还可以在此基础上指定列。说白了我们可以选择我们想要的行中的字段。

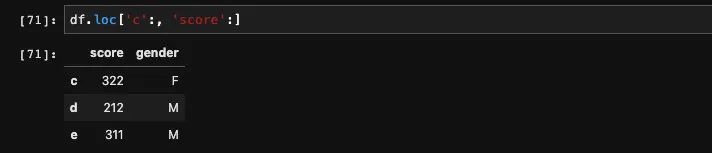
列索引也可以切片,并且可以组合在一起切片:
iloc
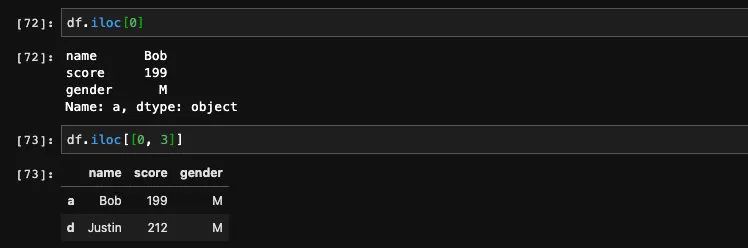
iloc从名字上来看就知道用法应该和loc不会差太大,实际上也的确如此。iloc的用法几乎和loc完全一样,唯一不同的是,iloc接收的不是index索引而是行号。我们可以通过行号来查找我们想要的行,既然是行号,也就说明了固定死了我们传入的参数必须是整数。
同样iloc也支持传入多个行号。
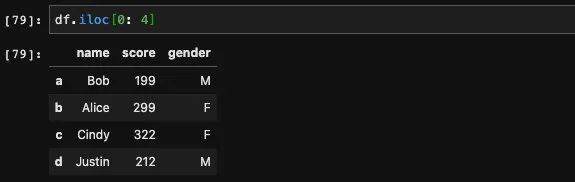
iloc也支持二维索引,但是对于列,我们也必须传入整数,也就是这个列对应的列号。

和loc不同,iloc的切片也是左闭右开。
我们在使用当中往往会觉得不方便,因为我们往往是知道我们需要的行号和列名。也就是知道一个索引知道一个位置,而不是两个位置或者是两个索引,所以使用loc也不方便使用iloc也不方便。这个时候可以取巧,我们可以通过iloc找出对应的行之后,再通过列索引的方式去查询列。
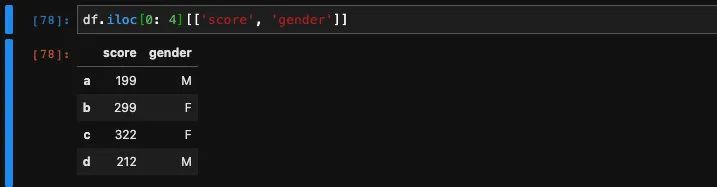
这里我们在iloc之后又加了一个方括号,这其实不是固定的用法,而是两个语句。先是iloc查询行之后,再对这些行组成的新的DataFrame进行列索引。
但如果是通过索引来查找对应的若干行的话,其实也可以不用使用iloc,我们可以直接在df后面加上方括号来查询,一样可以得到结果。

但是这种方式有一个限制,就是后面只能传入一个切片,而不能是一个整数。比如我想要单独查询第2行,我们通过df[2]来查询是会报错的。因为pandas会混淆不知道我们究竟是想要查询一列还是一行,所以这个时候只能通过iloc或者是loc进行。
逻辑表达式
和numpy一样,DataFrame也支持传入一个逻辑表达式作为查询条件。
比如我们想要查询分数大于200的行,可以直接在方框中写入查询条件df['score'] > 200。

实际上我们知道df['score']可以获得这一列对应的Series,加上了判断之后,得到的结果应该是一个Bool型的Series。所以如果我们直接传入一个bool型的数组也是一样可以完成查询的:
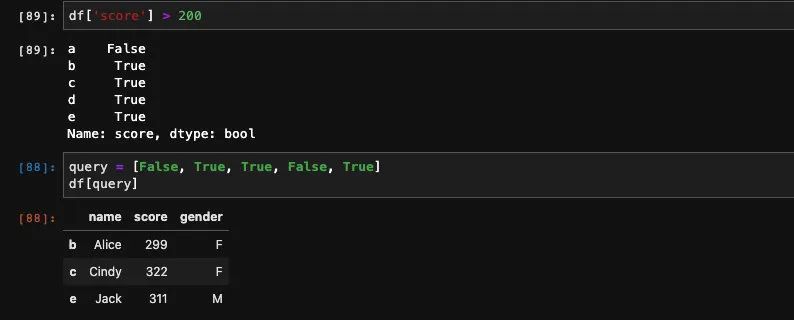
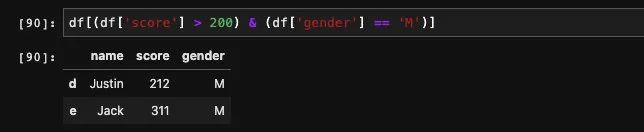
如果表达式有多个也没问题,不过需要使用括号将表达式包起来,并且多个表达式之间用位运算符连接,比如&, |。
总结
今天主要介绍了loc、iloc和逻辑索引在pandas当中的用法,这也是pandas数据查询最常用的方法,也是我们使用过程当中必然会用到的内容。建议大家都能深刻理解,把它记牢。
很多人在学习pandas的前期遇到最多的一个问题就是会把iloc和loc记混淆,搞不清楚哪个是索引查询哪个是行号查询。曾经原本还有一个ix方法,可以兼顾iloc和loc的功能,既可以索引查询也可以行号查询。但是可惜的是,在pandas最新的版本当中这个方法已经被废弃了。我个人也没有什么太好的办法,只能熟能生巧了,多用几次就记住了。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、在看、点赞)。
