hadoop完全分布式集群搭建(超详细)
集群信息
jdk: 1.8
linux: ubuntu18.04 server
hadoop: hadoop2.9.2
虚拟机: VMware
一.安装VMware,准备一台虚拟机
1.VMware:到VMware官网下载
安装:一路next
2.linux镜像:到官网下载
这里一定要下服务器版的 因为我们搭建集群至少要三台虚拟机 ,桌面版的太浪费性能,公司里也都是用服务器版


3.安装虚拟机,
选择自定义

这里不用改

选择稍后安装

选择linux Ubuntu64位

名称随便 路径建议安装到D盘

处理器数量和内核数都给2,根据自己电脑的性能自行修改

内存也根据自己电脑性能修改 建议2G

网络连接使用nat

这里选择推荐


选择创建新的磁盘

这里分配磁盘空间80G 可以根据需要自行修改 建议不要低于40G

这里使用默认

到此 虚拟机配置完成
现在准备打开虚拟机 在这之前需要导入镜像文件(之前在linux官网下载的ubuntu18.04)
双击CD/DVD

选择使用镜像文件 并选择之前下载的镜像文件
配置虚拟机网络
选择Workstation–>编辑–>虚拟网络编辑器

(1)选择nat模式
(2)把 使用本地DHCP服务器将ip地址分配给虚拟机 的勾去掉
(3)进入NAT设置 把网关设为192.168.219.2(记住了,等下配置虚拟机静态网络需要),这个根据自己的子网ip进行修改就好

(4)双击网路适配器将网络连接改为自定义模式 然后选择VMnet8(NAT模式)

到此外部网络环境配置完成
4.启动虚拟机 (启动过程中可能比较缓慢 一定要耐心等待)
选择english


这里不用管 等下到里面进行配置

这里可以不填

这里是下载源 不用管 等下到里面配置

这里选择第一个就好

继续回车

继续回车

选择continue

这里是一些账户信息 随便填 密码不要忘了

回车把install openSSH server 勾上 import SSH选择no

等待安装成功 选择reboot重启 (此过程有些电脑可能会非常慢 ,本人自己电脑有一次卡在这里将近一个小时 ,所以在这里不要急 耐心等待)

二.配置虚拟机网络
1.修改hostname主机名称
使用命令 sudo vim /etc/cloud/cloud.cfg 修改这一行: preserve_hostname: false 改为true 保存退出
sudo vim /etc/hostname 这里改为hadoop101
2.设置静态ip
使用命令打开.yaml文件sudo vim /etc/netplan/XXXX.yaml 我这里是50-cloud-init.yaml
network:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [192.168.219.101/24,] 这里是设置的静态ip一定要和外面设的网关在同一个网段上 我这里是192.168.219.101 因为这是101服务器所以设为101
gateway4: 192.168.219.2 这里是网关 要和外面vmware设置的网关保持一致
nameservers:
addresses: [8.8.8.8,8.8.4.4]
version: 2
3.配置hosts sudo vim /etc/hosts
192.168.219.101 hadoop101
192.168.219.102 hadoop102 这里配置三台 这是我们等下需要的三台服务器
192.168.219.103 hadoop103
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
4.改完之后reboot重启
ping一下百度,物理机,和自己 测试网络 看到如下结果表示网络配置完成

三.更改国内更新源 以及更新系统资源
1.更改国内下载源 sudo vim /etc/apt/sources.list 把之前的全部注释掉 或者删掉
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
这里不建议手敲 可以使用Xshell连接服务器粘贴复制 下载Xshell建议连同下载Xftp用于传文件
小提示: 使用普通用户每次sudo都需要输密码 觉得麻烦可以修改配置文件 使用命令 sudo visudo 改完户 ctrl+o 然后回车 在ctrl+x
# User privilege specification
root ALL=(ALL:ALL) ALL
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
# Allow members of group sudo to execute any command
%sudo ALL=(ALL:ALL) NOPASSWD:ALL
2.使用sudo apt-get update更新系统资源
四.设置root用户密码 ,允许root用户登录
1.使用sudo passwd root 设置root用户密码
2.使用sudo vim /etc/ssh/sshd_config 找到 PermitRootLogin 大概在第32行 改为 yes 默认是注释的


五.安装配置jdk
1.安装jdk1.8
执行命令 sudo apt install openjdk-8-jdk-headless 遇到提示按y
2.配置环境环境变量
使用命令 sudo vim /etc/profile 在文件末尾添加如下配置
##JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
保存后执行 source /etc/profile 让配置文件生效 使用 java -version 和 echo $JAVA_HOME 看是否打印正确的信息
六.安装hadoop
1.使用 sudo wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz 进行下载
这里使用hadoop2.9.2 如有需要可以到hadoop官网下载
2.使用 sudo tar zxvf hadoop-2.9.2.tar.gz 进行解压
3.使用sudo mv hadoop-2.9.2 /usr/local/hadoop 移动到/usr/local并重命名,此时可以sudo rm hadoop-2.9.2.tar.gz 删除安装包
4.使用 sudo chown -R xp /usr/local/hadoop 更改hadoop文件夹的所有者 改为普通用户 我这里是xp
5.配置hadoop环境变量
使用命令 sudo vim /etc/profile 在文件末尾添加如下配置
##HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后执行 source /etc/profile 让配置文件生效 使用 hadoop version 和 echo $HADOOP_HOME 看是否打印正确的信息
到此一个虚拟机搭建完毕
七.克隆虚拟机,并配置
1.先把101 关机 在VMware 点击 Workstation -->虚拟机 -->管理 -->克隆 创建完整克隆

命名hadoop102 建议和hadoop101存放在一个目录下 方便管理

打开克隆好的虚拟机然后做以下几件事 以后如果要添加服务器也是这样操作
1.修改主机名称
2.修改静态ip
3.reboot重启
然后再克隆一个hadoop103
这样就准备好了三台服务器 hadoop101 hadoop102 hadoop103
八.配置ssh免密登录
1.分别在三台服务器上执行ssh-keygen -t rsa 连续三次回车 生成公钥和秘钥 进到ssh文件夹 cd ~/.shh 查看文件
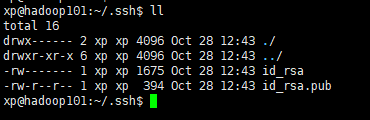
id_rsa是私钥 id-rsa.pub
2.我们需要把每台服务器上的公钥拷贝到其他服务器的.ssh目录和自己的.ssh目录即可实现免密登录
使用命令 ssh-copy-id 后面接需要拷贝到的主机名 比如 ssh-copy-id hadoop102 (注:一定要拷贝到自己 不要忘了)
3.使用ssh 接主机名 登录目标主机 例如 ssh hadoop102 登录其他主机和自己都不要密码即免密登录配置成功
九.编写xsync分发脚本
xsync分发脚本可以实现把一台服务器的文件同步到其他服务器,用于更新配置文件 非常方便
1.在hadoop101的 /home/xp下创建bin目录 mkdir bin
2.进到 bin目录创建文件xsync 文件名任意我这里用xsnyc 并写入以下内容
如果主机名和我的不一样则要对#5 for循环的地方进行修改,实现只分发到其他两台服务器,不分发到自己所以我的for循环内容是
host=102; host<104;host++
#!/bin/bash
#1获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4获取当前名称
user=`whoami`
#5循环
for((host=102; host<104 ; host++)); do
echo ---------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
3.把/home/xp/bin文件夹 设置权限777 chmod -R 777 /home/xp/bin
.把/home/xp/bin配置Path 方便执行 记得source /etc/proflie
##xsync
export PATH=$PATH:/home/xp/bin
4.hadoop101的分发脚本就已经配置好了,接下来配置其他两台,
由于我们有了xsync分发脚本,我们配置其他两台就很方便,直接用分发脚本把 /home/xp/bin 和 /etc/profile分发到其他两台
直接使用命令 xsync /home/xp/bin 和 sudo ./xsync /etc/profile
此处因为profile需要root用户才能操作所以要sudo
如果过程中遇到一直输入密码不正确 那可能是没有设置root密码或者没有设置运行root用户登录,参照 四.
5.如第二点所说修改所有xsync脚本 实现只分发给其他两台服务器
6.修改其他两台/home/xp/bin文件夹777权限
7.测试
十.修改hadoop配置文件(重点)
hadoop的配置文件都存放在$HADOOP_HOME/etc/hadoop下
此阶段我们需要搭建的集群有三个比较消耗性能的服务
HDFS的NameNode , SencondaryNameNode 以及Yarn的ResourceManager
所以它们刚好可以放在三台不同的服务器,按下表配置
|
hadoop101 |
hadoop102 |
hadoop103 |
| HDFS |
NameNode
DataNode |
DataNode |
SecondaryNameNode |
| YARN |
NodeManager |
ResourceManager
NodeManager |
NodeManager |
| 每个配置文件的默认值以及作用都可以去官网查看 |
|
|
|
 |
|
|
|
说明:配置好的的文件需要用xsync分发脚本同步到其他两台服务器,这里就体现了sxync的强大之处
由于我们之前改过hadoop目录的权限,所以以后对hadoop目录的操作都不用root用户 即不用sudo
1.配置core-site.xml
说明:
hadoop.tmp.dir : hadoop运行时产生的文件储存的目录
fs.defaultFS : 指定NameNode(元数据节点)的地址 这里根据之前设想好的 配置到hadoop101
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
</configuration>
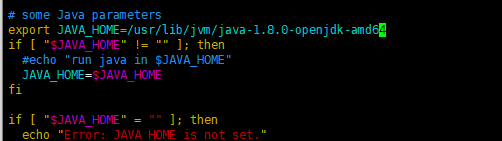
2.hadoop-env.sh
在文件的末尾 添加JAVA_HOME export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 根据自己的环境进行配置
以后遇到env就配JAVA_HOME

3.hdfs-site.xml
说明:
dfs.replication : 副本数量,这里设置为3,也可以不设 因为默认值就是3
dfs.namenode.secondary.http-address : SecondaryNameNode(从元数据节点)的地址 这里根据之前设想好的 配置到hadoop103
dfs.namenode.name.dir : NameNode数据即元数据存放的目录 这里存放到tmp目录下
dfs.datanode.data.dir : DameNode数据即真正数据存放的目录 这里跟NameNode的目录并级
dfs.permissions : 操作hdfs的时候是否检查权限 这里设置为false 方便java api访问 可以不设置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.mapred-env.sh
配置JAVA_HOME 默认是注释的 根据自己环境修改即可

5.mapred-site.xml
这个文件就稍微有点区别了
需要将mapred-site.xml.template文件改名为mapred-site.xml
说明:
mapreduce.framework.name : 设置mapredu在哪里运行这里配置到yarn
mapreduce.jobhistory.address : 历史服务器的地址 这里把它配置到hadoop102
mapreduce.jobhistory.webapp.address : 历史服务器web(即浏览器)的访问地址和端口
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
6.yarn.env.sh
还是照常配置JAVA_HOME 根据环境修改即可
7.yarn.site.xml
说明:
yarn.nodemanager.aux-services : Reducer获取数据的方式 这里设为mapreduce_shuffle
yarn.resourcemanager.hostname : resourcemanager的地址 这里根据我们之前设想好的 配置到hadoop102
yarn.log-aggregation-enable : 是否启用日志查询 为了以后查看程序日志 所以这里设置true
yarn.resourcemanager.webapp.address : resourcemanager的web访问地址 可以不设置 默认就是resourcemanager所在的地址
yarn.log-aggregation.retain-seconds : 日志保留时间 这里设置为七天 604800
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop102:8088</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
8.直接xsync $HADOOP_HOME/etc/hadoop 将配置文件同步到其他服务器
9.格式化NameNode 在以后的格式化之前一定要先杀死所有进程 然后再删掉logs 和tmp目录 命令:hdfs namenode -format
如果有报错 一定要回头检查配置
十一.启动集群
激动人心的时刻到了,执行文件都放在hadoop的sbin下
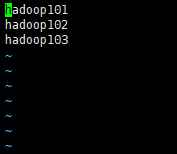
1.为了不一个一个服务器的启动我们可以配置etc/hadooop下的slaves在里面添加我们的三台服务器主机名
注意 :不能有空格和其他符号,然后分发到其他服务器
2.NameNode节点hadoop101上启动hdfs 命令:sbin/start-dfs.sh
3.ResourceManager节点hadoop102上启动yarn 命令:sbin/start-yarn.sh
4.如果需要查看历史服务 则需要打开历史服务器的守护进程
我们的历史服务器配置在hadoop102 命令:sbin/mr-jobhistory-daemon.sh start historyserver
5.使用jps查看进程
如果提示找不到jps 就去source一下 /etc/profile



和我的一样就说明完全分布式集群搭建成功