从“文本”到“知识”:信息抽取
这是一个大数据的时代。随着太阳东升西落,每一天都在产生大量的数据信息。人们通常更擅长处理诸如数字之类的结构化数据。但实际情况是,非结构化数据往往比结构化的数据多。
当我们从互联网上获取了大量的如文本之类的非结构化数据,如何去有效地分析它们来帮助我们更好地做出决策呢?这将是本文要回答的问题。
信息提取是从非结构化数据(例如文本)中提取结构化信息的任务。我将这个过程分为以下四个步骤进行处理。
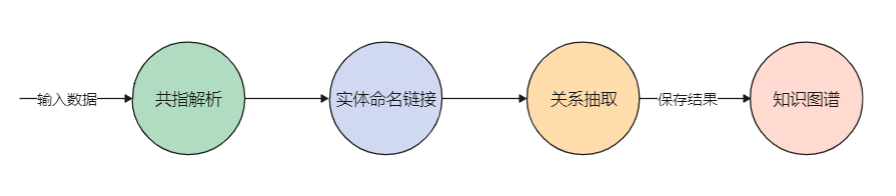
1.共指解析(Coreference Resolution)
“共指解析”就是在文本中查找引用特定实体的所有表达式。简单来说就是解决代指问题。比如,Deepika has a dog. She loves him. 我们知道这里的she指代的是Deepika,him指代的是dog,但是计算机不知道。
我这里使用Neuralcoref模型解决这个问题,该模型基于SpaCy框架运行。值得注意的是,Neuralcoref模型可能不太适用于位置代词。代码如下:
import spacy
import neuralcoref
# Load SpaCy
nlp = spacy.load('en')
# Add neural coref to SpaCy's pipe
neuralcoref.add_to_pipe(nlp)
def coref_resolution(text):
"""Function that executes coreference resolution on a given text"""
doc = nlp(text)
# fetches tokens with whitespaces from spacy document
tok_list = list(token.text_with_ws for token in doc)
for cluster in doc._.coref_clusters:
# get tokens from representative cluster name
cluster_main_words = set(cluster.main.text.split(' '))
for coref in cluster:
if coref != cluster.main: # if coreference element is not the representative element of that cluster
if coref.text != cluster.main.text and bool(set(coref.text.split(' ')).intersection(cluster_main_words)) == False:
# if coreference element text and representative element text are not equal and none of the coreference element words are in representative element. This was done to handle nested coreference scenarios
tok_list[coref.start] = cluster.main.text + \
doc[coref.end-1].whitespace_
for i in range(coref.start+1, coref.end):
tok_list[i] = ""
return "".join(tok_list)
如果以下面这段文本作为输入:
Elon Musk is a business magnate, industrial designer, and engineer. He is the founder, CEO, CTO, and chief designer of SpaceX. He is also early investor, CEO, and product architect of Tesla, Inc. He is also the founder of The Boring Company and the co-founder of Neuralink. A centibillionaire, Musk became the richest person in the world in January 2021, with an estimated net worth of $185 billion at the time, surpassing Jeff Bezos. Musk was born to a Canadian mother and South African father and raised in Pretoria, South Africa. He briefly attended the University of Pretoria before moving to Canada aged 17 to attend Queen's University. He transferred to the University of Pennsylvania two years later, where he received dual bachelor's degrees in economics and physics. He moved to California in 1995 to attend Stanford University, but decided instead to pursue a business career. He went on co-founding a web software company Zip2 with his brother Kimbal Musk. |
则输出为:
Elon Musk is a business magnate, industrial designer, and engineer. Elon Musk is the founder, CEO, CTO, and chief designer of SpaceX. Elon Musk is also early investor, CEO, and product architect of Tesla, Inc. Elon Musk is also the founder of The Boring Company and the co-founder of Neuralink. A centibillionaire, Musk became the richest person in the world in January 2021, with an estimated net worth of $185 billion at the time, surpassing Jeff Bezos. Musk was born to a Canadian mother and South African father and raised in Pretoria, South Africa. Elon Musk briefly attended the University of Pretoria before moving to Canada aged 17 to attend Queen's University. Elon Musk transferred to the University of Pennsylvania two years later, where Elon Musk received dual bachelor's degrees in economics and physics. Elon Musk moved to California in 1995 to attend Stanford University, but decided instead to pursue a business career. Elon Musk went on co-founding a web software company Zip2 with Elon Musk brother Kimbal Musk. |
2.命名实体链接(Named Entity Linking)
这部分我使用的是Wikifier API。大家可以自己尝试一下。Wikifier API:http://wikifier.org/

在通过Wikifier API运行输入文本之前,我们将文本拆分为句子并删除标点符号。代码如下:
import urllib
from string import punctuation
import nltk
ENTITY_TYPES = ["human", "person", "company", "enterprise", "business", "geographic region",
"human settlement", "geographic entity", "territorial entity type", "organization"]
def wikifier(text, lang="en", threshold=0.8):
"""Function that fetches entity linking results from wikifier.com API"""
# Prepare the URL.
data = urllib.parse.urlencode([
("text", text), ("lang", lang),
("userKey", "tgbdmkpmkluegqfbawcwjywieevmza"),
("pageRankSqThreshold", "%g" %
threshold), ("applyPageRankSqThreshold", "true"),
("nTopDfValuesToIgnore", "100"), ("nWordsToIgnoreFromList", "100"),
("wikiDataClasses", "true"), ("wikiDataClassIds", "false"),
("support", "true"), ("ranges", "false"), ("minLinkFrequency", "2"),
("includeCosines", "false"), ("maxMentionEntropy", "3")
])
url = "http://www.wikifier.org/annotate-article"
# Call the Wikifier and read the response.
req = urllib.request.Request(url, data=data.encode("utf8"), method="POST")
with urllib.request.urlopen(req, timeout=60) as f:
response = f.read()
response = json.loads(response.decode("utf8"))
# Output the annotations.
results = list()
for annotation in response["annotations"]:
# Filter out desired entity classes
if ('wikiDataClasses' in annotation) and (any([el['enLabel'] in ENTITY_TYPES for el in annotation['wikiDataClasses']])):
# Specify entity label
if any([el['enLabel'] in ["human", "person"] for el in annotation['wikiDataClasses']]):
label = 'Person'
elif any([el['enLabel'] in ["company", "enterprise", "business", "organization"] for el in annotation['wikiDataClasses']]):
label = 'Organization'
elif any([el['enLabel'] in ["geographic region", "human settlement", "geographic entity", "territorial entity type"] for el in annotation['wikiDataClasses']]):
label = 'Location'
else:
label = None
results.append({'title': annotation['title'], 'wikiId': annotation['wikiDataItemId'], 'label': label,
'characters': [(el['chFrom'], el['chTo']) for el in annotation['support']]})
return results
以上一步中共指解析的输出作为这里的输入,运行得到如下结果。

可以看到,我们还获得了实体对应的WikiId及其label。WikiId可以消除同名实体的歧义问题。虽然维基百科拥有超过1亿个实体,但对于维基百科上不存在的实体,仍将无法识别它。
3.关系提取(Relationship Extraction)
我使用OpenNRE项目来实现关系提取。它具有五个在Wiki80或Tacred数据集上经过训练的开源关系提取模型。在Wiki80数据集上训练的模型可以推断80种关系类型。
-
wiki80_cnn_softmax: trained on wiki80 dataset with a CNN encoder.
-
wiki80_bert_softmax: trained on wiki80 dataset with a BERT encoder.
-
wiki80_bertentity_softmax: trained on wiki80 dataset with a BERT encoder (using entity representation concatenation).
-
tacred_bert_softmax: trained on TACRED dataset with a BERT encoder.
-
tacred_bertentity_softmax: trained on TACRED dataset with a BERT encoder (using entity representation concatenation).
这里,我使用了wiki80_bert_softmax模型(需要GPU提供支持)。
如果我们看一下OpenNRE库中的关系提取示例,我们会注意到它仅推断关系,而不尝试提取命名实体。所以我们必须提供一对带有h和t参数的实体,然后模型尝试推断出一个关系。
# 示例
model.infer({'text': 'He was the son of Máel Dúin mac Máele Fithrich, and grandson of the high king Áed Uaridnach (died 612).',
'h': {'pos': (18, 46)},
't': {'pos': (78, 91)}
})
# 结果
('father', 0.5108704566955566)
实现代码如下所示:
# First get all the entities in the sentence
entities = wikifier(sentence, threshold=entities_threshold)
# Iterate over every permutation pair of entities
for permutation in itertools.permutations(entities, 2):
for source in permutation[0]['characters']:
for target in permutation[1]['characters']:
# Relationship extraction with OpenNRE
data = relation_model.infer(
{'text': sentence, 'h': {'pos': [source[0], source[1] + 1]}, 't': {'pos': [target[0], target[1] + 1]}})
if data[1] > relation_threshold:
relations_list.append(
{'source': permutation[0]['title'], 'target': permutation[1]['title'], 'type': data[0]})
用“命名实体链接”的结果作为“关系提取过程”的输入。我们遍历一对实体的每个排列组合来尝试推断一个关系。用relationship_threshold参数,用于省略较低的置信度关系。在下一步中,我会解释为什么这里使用实体的所有排列而不是一些组合。
运行结果如下:

关系提取是一个具有挑战性的问题,就目前来说,很难有一个完美的结果。
4.知识图谱(Knowledge Graph)
当我们处理实体及其关系时,将结果存储在图形数据库中才有意义。这里我使用Neo4j作为图数据库。

我尝试推断实体之间所有排列的关系。查看上一步中的表格结果,很难解释为什么。但在图形可视化中,很容易观察到,虽然大多数关系都是双向推断的,但并非在所有情况下都是如此。