


调用模块:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'SimHei' # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False
import random
import pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts import *
from datetime import datetime,timedelta
任务 1 数据的预处理
任务 1.1 附件 1 的产品通用名称存在不规范的情况。请按照复混肥料(掺 混肥料归入这一类)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 种类别 对附件 1 进行规范化处理。请在报告中给出处理思路、过程及必要的结果,同时 将完整的结果保存到文件“result1_1.xlsx”中。
data1 = pd.read_excel('附件1.xlsx')
# 自定义函数
def rep(x):
x = x.strip() # 去除左右空字符
if x == '掺混肥料':
return '复混肥料'
if x[-3:] =='调酸剂':
return '床土调酸剂'
if x[:2] =='有机' and x[-4:]=='复混肥料':
return '有机-无机复混肥料'
else:
return x
data1.产品通用名称 = data1.产品通用名称.apply(rep)
data1.to_excel('result1_1.xlsx')
处理前:

处理后:
 自主分析:
自主分析:
with sns.color_palette('rainbow'): fig = plt.figure(figsize=(13,4))
plt.subplot(121)
d = data1['产品通用名称'].value_counts()
plt.pie(x = d ,labels = d.index,autopct='%.2f%%')
plt.title('产品类型统计饼图')
plt.subplot(122)
axesSub = sns.countplot(x = '产品通用名称',data = data1[['产品通用名称','产品形态']],hue = '产品形态')
# 展示数值
plt.bar_label(axesSub.containers[0])
plt.bar_label(axesSub.containers[1])
plt.title('产品形态统计柱状图')
plt.show()

任务 1.2 计算附件 1 中各肥料产品的氮、磷、钾养分百分比之和,称为总 无机养分百分比。请在报告中给出处理思路、过程及必要的结果,同时将完整的 结果保存到文件“result1_2.xlsx”中,结果保留 3 位小数(例如 1.0%,即 0.010)。
data1['总无机养分百分比'] = data1[['总氮百分比','P2O5百分比','K2O百分比']].sum(axis = 1).apply(lambda x:('%.3f'%x))
data1.to_excel('result1_2.xlsx')
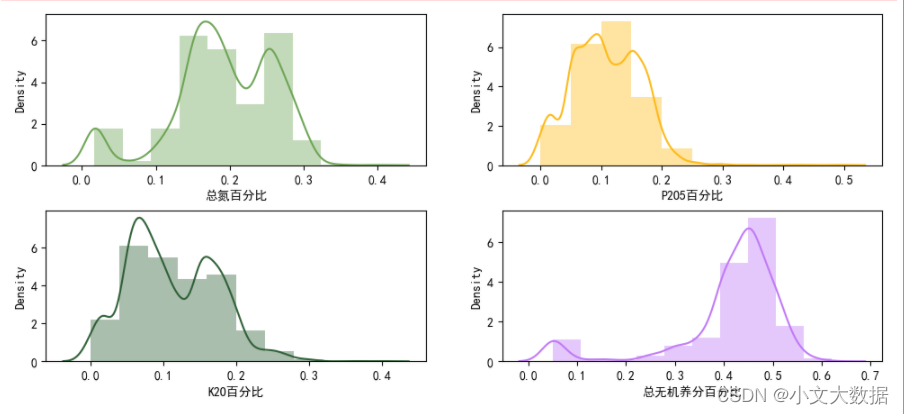
自主分析:
data1['总无机养分百分比'] = data1['总无机养分百分比'].astype(float)
# 作者封装函数,有需要源程序可在作者博客‘seaborn封装’中寻找
distplot(data1, 2, 2, vars = ['总氮百分比','P2O5百分比','K2O百分比', '总无机养分百分比'],kind = 'both')
任务 2.1 从附件 2 中筛选出复混肥料的产品,将所有复混肥料按照总无机 养分百分比的取值等距分为 10 组。根据每个产品所在的分组,为其打上分组标 签(标签用 1~10 表示),将完整的结果保存到文件“result2_1.xlsx”中。分析复 混肥料产品的分布特点,在报告中绘制产品登记数量的直方图,给出处理思路及 过程,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记 数量。
data2 = pd.read_excel('附件2.xlsx')
# 取出复混肥料数据
data2_1 = data2[data2['产品通用名称']=='复混肥料'].copy()
# 等距分组
data2_1['无机养分百分比分组'] = pd.cut(data2_1.总无机养分百分比,bins = 10,labels=np.arange(1,11))
# 保存结果
data2_1.to_excel(r'result2_1.xlsx')
可视化:
with sns.color_palette('rainbow'):
data2_1['无机养分百分比分组'].hist()
plt.xticks(range(1,11))
plt.title('产品登记数量直方图')

a = data2_1['无机养分百分比分组'].value_counts()
print('前三:\n',a.head(3))
a = a.sort_index()
with sns.color_palette('rainbow'):
bar = plt.bar(a.index,a.values)
plt.bar_label(bar)
plt.title('产品登记数量柱状图')
plt.xticks(range(11))

pyecharts:
bar = Bar()
bar.add_xaxis(a.index.to_list())
bar.add_yaxis('无机养分分组',a.tolist(), color = 'blue')
bar.set_global_opts(title_opts=opts.TitleOpts(title = '无机总养分分组数量统计',subtitle=None,item_gap = 20),# item_gap表示正副标题的距离
xaxis_opts=opts.AxisOpts(type_='category',name= '组别', name_location='center',name_gap=25,),
yaxis_opts=opts.AxisOpts(name= '数量',type_='value', name_location='end',name_gap=15,
splitline_opts=opts.SplitLineOpts(is_show=True,
linestyle_opts=opts.LineStyleOpts(opacity=1)),),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
# 范围拖动功能
# datazoom_opts = opts.DataZoomOpts(range_start = 0,range_end = 100),
# 右上角功能窗口
# toolbox_opts= opts.ToolboxOpts(True),
)
bar.set_series_opts(label_opts = opts.LabelOpts(position = 'top'),
# markpoint_opts = opts.MarkPointOpts(data = [opts.MarkPointItem(type_= ['max'])],symbol_size=80)
)
# bar.reversal_axis() # 转换成水平直方图
bar.render_notebook()

任务 2.2 从附件 2 中筛选出有机肥料的产品,将产品按照总无机养分百分 比和有机质百分比分别等距分为 10 组,并为每个产品打上分组标签 (1,1), (1,2), ⋯, (10,10),将完整的结果保存到文件“result2_2.xlsx”中。请在报告中给出处理 思路及过程,并根据分组情况绘制有机肥料产品的分布热力图,其中横轴代表总 无机养分分组,纵轴代表有机质分组。在此基础上,分析有机肥料产品的分布特 点,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记数 量。
data2_2 = data2[data2['产品通用名称']=='有机肥料'].copy()
data2_2['无机养分百分比分组'] = pd.cut(data2_2.总无机养分百分比,bins = 10,labels=np.arange(1,11))
data2_2['有机养分百分比分组'] = pd.cut(data2_2.有机质百分比,bins = 10,labels = np.arange(1,11))
data2_2['无机、有机分组'] = data2_2[['无机养分百分比分组','有机养分百分比分组']].apply(lambda x:(x[0],x[1]),axis = 1)
data2_2.drop(['无机养分百分比分组','有机养分百分比分组'],axis = 1,inplace =True)
data2_2.to_excel('result2_2.xlsx')
# 获取热力图矩阵数据
shuju = data2_2['无机、有机分组'].value_counts()
# 矩阵初始化
reli = np.zeros((10,10))
# 填上数据
for index,data in zip(shuju.index,shuju.values):
for row in range(1,11):
for col in range(1,11):
if col == index[0] and row == index[1]:
reli[row-1,col-1] =data
reli = reli.astype(int)
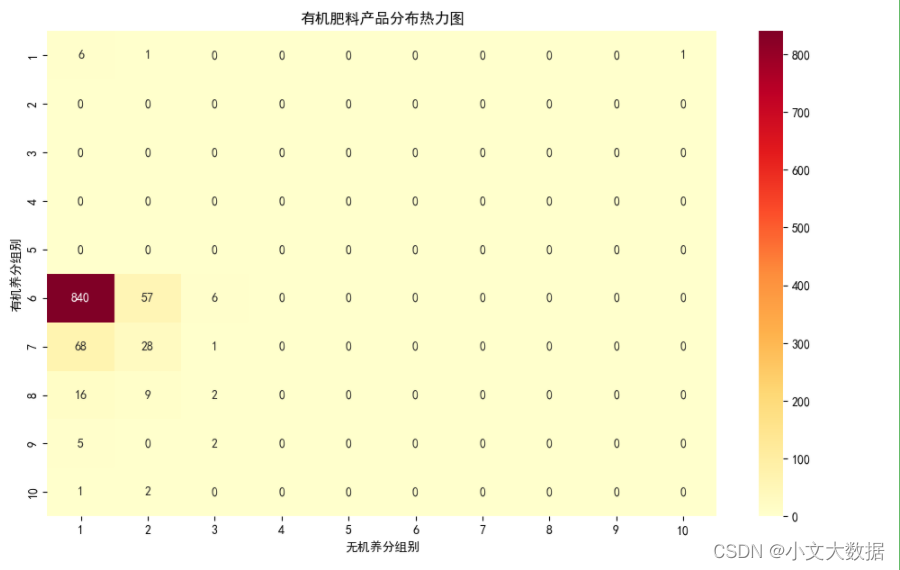
热力图:
plt.figure(figsize = (12,7))
heatmap = sns.heatmap(reli,annot=True,fmt ='d',cmap = "YlOrRd",xticklabels = range(1,11),yticklabels=range(1,11)) #画热力图
plt.title('有机肥料产品分布热力图')
plt.xlabel('无机养分组别')
plt.ylabel('有机养分组别')
plt.show()
pyecharts:
from pyecharts import options as opts
from pyecharts.charts import HeatMap
from pyecharts.faker import Faker
import random
hm = HeatMap()
# 使用列表表达式创建7*24的二维列表
data = [[i,j, reli.tolist()[j][i]] for i in range(10) for j in range(10)]
hm.add_xaxis([f'第{i}组' for i in range(1,11)])
hm.add_yaxis("有机肥料产品分布热力图", [f'第{i}组' for i in range(1,11)], data)
hm.set_global_opts(
title_opts=opts.TitleOpts(title="热力图--显示标签"),
visualmap_opts=opts.VisualMapOpts(
min_=10,max_=900,
orient="horizontal", # 视觉映射组件水平放置
pos_left="center")) #居中
hm.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position="inside"))
hm.render_notebook()

shuju = data2_2['无机、有机分组'].value_counts()
bar = shuju[:3].plot.bar(color = 'b',width = 0.4)
plt.bar_label(bar.containers[0])
plt.xticks(rotation = 0)
plt.title('分组登记数量:Top 3')
plt.show()

任务 2.3 从附件 2 中筛选出复混肥料的产品,按照氮、磷、钾养分的百分 比,使用聚类算法将这些产品分为 4 类。根据聚类结果为每个产品打上聚类标签 (标签用 1~4 表示),并将完整的结果保存到文件“result2_3.xlsx”中。请在报 告中给出处理思路及过程,根据聚类标签绘制肥料产品的三维散点图和散点图矩阵,并通过绘制聚类结果的雷达图分析每个聚类的特征。
from sklearn import cluster
from sklearn.preprocessing import StandardScaler
# Kmeans聚类模型,4个聚类簇
model = cluster.KMeans(n_clusters=4)
x = StandardScaler().fit_transform(data2_1[['总氮百分比','P2O5百分比','K2O百分比']])
# 模型训练
data2_1['labels'] = model.fit_predict(x)+1
axesSub = data2_1.labels.value_counts().sort_index().plot.bar(color = 'c')
plt.bar_label(axesSub.containers[0])
plt.xticks(rotation = 0)
plt.title('聚类类别统计')
plt.show()

三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(18,9))
ax = fig.add_subplot(111, projection='3d')
for i in range(1,5):
data = data2_1[data2_1['labels']==i]
ax.scatter(data['总氮百分比'],data['P2O5百分比'],data['K2O百分比'],label =i)
plt.title('三维散点图')
plt.legend()
plt.show()

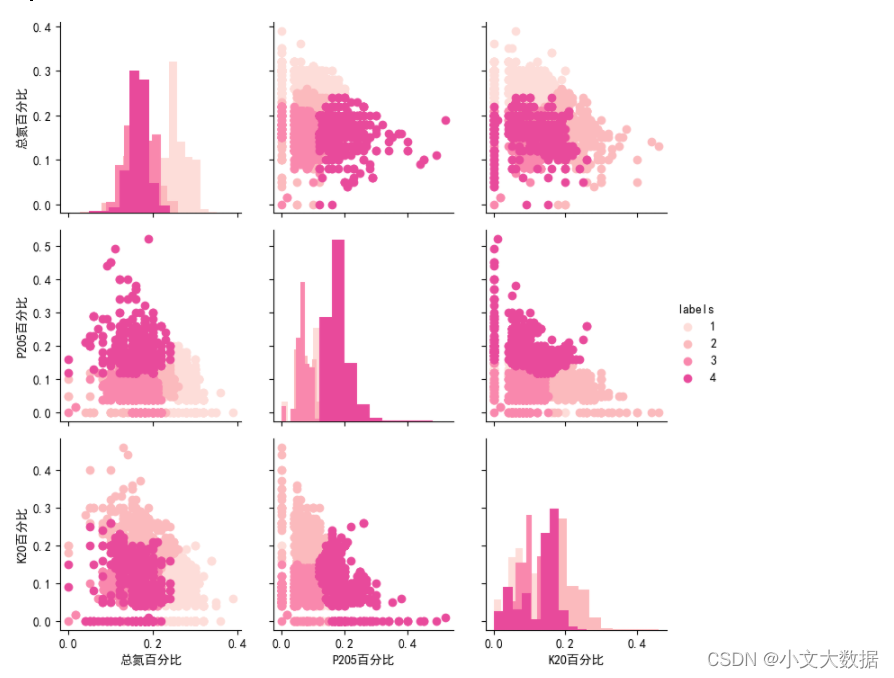
散点图矩阵
plt.figure(figsize=(18,7))
sns.set_palette(sns.color_palette("RdPu"))
g = sns.PairGrid(data2_1[['总氮百分比','P2O5百分比','K2O百分比','labels']], hue="labels")
g = g.map_diag(plt.hist)
g = g.map_offdiag(plt.scatter)
g = g.add_legend()
plt.show()
雷达图:
from pyecharts import options as opts
from pyecharts.charts import Radar
value_bj = [
data2_1.labels.value_counts().sort_index().tolist(),
]
c_schema = [
{"name": "1", "max": 1800, "min": 0},
{"name": "2", "max": 1800, "min": 0},
{"name": "3", "max": 1800, "min": 0},
{"name": "4", "max": 1800, "min": 0},
]
Radar().add_schema(schema=c_schema, shape="circle").add("聚类", value_bj, color="blue",
).set_series_opts(label_opts=opts.LabelOpts(is_show=False)
).set_global_opts(title_opts=opts.TitleOpts(title="聚类类别雷达图")).render_notebook()
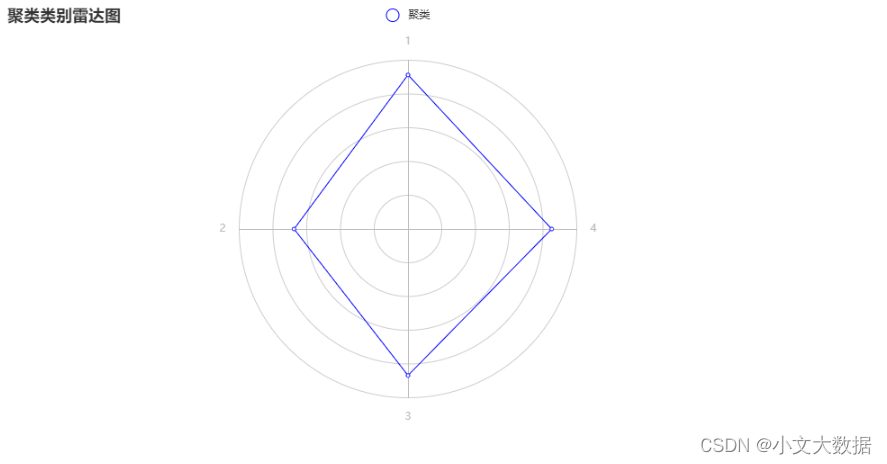
自主分析:
箱线图
def boxplot(data):
with sns.color_palette('rainbow'):
fig = plt.figure(figsize = (12,3))
for i,col in enumerate(data.columns):
plt.subplot(1,3,i+1)
sns.boxplot(data = data[[col]],width = 0.2, color = np.random.choice(list(sns.xkcd_rgb.values())))
plt.show()
boxplot(data2_1[['总氮百分比','P2O5百分比','K2O百分比']])

直方图
# 作者封装函数,有需要源程序可在作者‘博客seaborn’中寻找
distplot(data2_1[['总氮百分比','P2O5百分比','K2O百分比']],1,3)

各聚类类别密度图
# 作者封装函数,有需要源程序可在作者‘博客seaborn’中寻找
distplot(data2_1[['总氮百分比','P2O5百分比','K2O百分比','labels']],1,3,hue = 'labels',kind = 'kde')

任务 3.1 从文件“result2_1.xlsx”中提取发证日期中的年份,分析比较复混 肥料中各组别不同年份产品登记数量的变化趋势。请在报告中给出处理思路及分 析过程,使用合适的图表对结果进行可视化。
data3_1 = pd.read_excel(r'result2_1.xlsx').iloc[:,1:]
data3_1['发证日期'] = pd.to_datetime(data3_1.发证日期)
data3_1['发证日期年份'] = data3_1.发证日期.dt.year
# 统计数据
data = data3_1.groupby(['无机养分百分比分组','发证日期年份'],as_index=False).size()
data.无机养分百分比分组 = data.无机养分百分比分组.apply(str)
data.head()
可视化:
with sns.color_palette('gist_rainbow',n_colors=10):
for i in data.无机养分百分比分组.unique():
d = data.query(f"无机养分百分比分组 == '{i}'").sort_values('发证日期年份')
plt.plot(d['发证日期年份'], d['size'],label = f'{i}')
plt.legend()
plt.title('不同产品登记数量随年份变化曲线图')
plt.show()

pyecharts:
# 封装函数:参考seaborn中的hue参数
def hue_line_plot(data,hue,x,y,title='',label_show=True,smooth =False):
# data要提前排好序
data = data.sort_values(by = x)
categorys= np.sort(data[hue].copy().unique())
line = Line(init_opts=opts.InitOpts(theme=ThemeType.DARK,bg_color = '',width='900px',height = '550px'))
for category in categorys:
data_ = data[data[hue]==category]
data_x = data_.loc[:,x]
data_y = data_.loc[:,y]
line.add_xaxis(data_x,)
line.add_yaxis(series_name=category,y_axis = data_y,is_symbol_show =True,is_smooth=smooth,
linestyle_opts=opts.LineStyleOpts( width=2.5, type_="solid"),
label_opts = opts.LabelOpts(is_show=label_show,))
line.set_global_opts(xaxis_opts = opts.AxisOpts(min_=int(data[x].min()-data[x].std()/2),name = x,max_interval=None,),
yaxis_opts = opts.AxisOpts(name = y),
title_opts = opts.TitleOpts(title = title),
legend_opts =opts.LegendOpts(pos_bottom='0',type_ = 'scroll'),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),)
return line.render_notebook()
hue_line_plot(data =data,x = '发证日期年份',y = 'size',label_show=False,smooth=True,
hue = '无机养分百分比分组',title = '各组别不同年份产品登记数量趋势图',)

任务 3.2 从文件“result2_2.xlsx”中提取 2021 年 9 月 30 日仍有效的有机 肥料产品,将完整的结果保存到文件“result3_2.xlsx”中。从有效产品中分别筛 选出广西和湖北(根据正式登记证号区分)产品登记数量在前 5 的组别,分析两 个省份上述组别的分布差异。请在报告中给出处理过程及分析结果。
data3_2 = pd.read_excel(r'result2_2.xlsx').iloc[:,1:]
data3_2['发证日期'] = pd.to_datetime(data3_2['发证日期'])
# 有的有效期只有年月份没有日,使用发证日期的日填补
def add_day(x):
if x['有效期'].count('-')==1:
return x['有效期'] + '-' + str(x['发证日期'].day)
else:
return x['有效期']
data3_2['有效期'] = data3_2[['发证日期','有效期']].apply(add_day,axis =1)
data3_2['有效期'] = pd.to_datetime(data3_2['有效期'])
# 根据题意有效期为5年,去除有效期减去发证日期小于五年的异常不确定数据
condition1 = data3_2['有效期'].dt.year - data3_2['发证日期'].dt.year >=5
# 取出有效期在2021-9-30之后的数据
condition2 = data3_2['有效期'].apply(lambda x:x>=datetime(2021,9,30))
data = data3_2[condition1 & condition2]
# 保存结果
data.to_excel('result3_2.xlsx')
筛选广西、湖北数据:
data_hubei = data[data['正式登记证号'].str.startswith('鄂')]
data_guangxi = data[data['正式登记证号'].str.startswith('桂')]
# 可视化广西、湖北产品登记数量统计前五组别数据进行对比分析
with sns.color_palette('rainbow'):
plt.figure(figsize=(10,5))
plt.subplot(121)
axesSub = data_guangxi.groupby(['无机、有机分组']).size().sort_values(ascending=False).head().plot.bar(label ='广西')
plt.legend()
plt.bar_label(axesSub.containers[0])
plt.xticks(rotation = 0)
with sns.color_palette('rainbow_r'):
plt.subplot(122)
axesSub = data_hubei.groupby(['无机、有机分组']).size().sort_values(ascending=False).head().plot.bar(label ='湖北')
plt.xticks(rotation = 0)
plt.legend()
plt.bar_label(axesSub.containers[0])
plt.show()

任务 3.3 从附件 3 中提取产品登记数量大于 10 的肥料企业,给出这些企业 所用到的原料集合(发酵菌剂除外)。以各企业用到的原料作为特征,计算企业 之间的杰卡德相似系数矩阵,并将结果(保留4位小数)保存到文件“result3_3.xlsx” 中(不提供模板文件,格式见表 1)。请在报告中给出处理思路、过程及相似系 数矩阵。 注 集合
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)