
文章目录
二叉树的创建(使用先序遍历)
递归实现二叉树的遍历:
先序遍历:
中序遍历:
后续遍历:
一些二叉树基本操作:
求树的深度:
求树的结点个数:
查找特定值的结点:
查找特定值结点的父结点:
将树拷贝到新树上(二叉树的复制):
非递归实现遍历:
层次遍历:
前序遍历:
中序遍历:
后续遍历:
本文主要讲解递归实现二叉树的代码,对于树,二叉树的性质概念不多赘述
我们以'#'代表空结点(为已有结点下的左右空孩子),方便创建二叉树,我们以下图的二叉树作为讲解
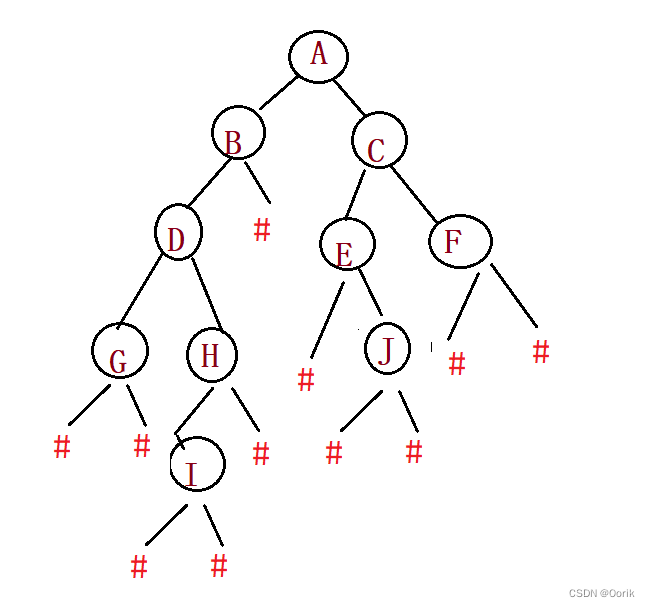
二叉树的创建(使用先序遍历)
以下我会用递归的方法实现创建和基本操作,最后也会使用非递归的思想取实现二叉树的几种遍历方法
class Node {//二叉树结点
public:
char m_value;//结点值
Node* m_left;//左子树
Node* m_right;//右子树
Node():m_left(nullptr),m_right(nullptr){}
Node(char val):m_value(val),m_left(nullptr),m_right(nullptr){}
~Node(){}
};
class Tree {//创建二叉树
public:
Node* m_root;//根节点
Tree():m_root(nullptr){}
Tree(Node* t):m_root {t} {}
~Tree(){}
//传递节点指针的指针!!!const char*& str
//用#表示空结点
Node* Create(const char*& str);//先序遍历创建二叉树
};
Node* Tree::Create(const char*& str)//创建二叉树然后把树的根结点返回去
{
if (*str == '#')//没有树
{
return nullptr;
}
else
{
Node* root = new Node(*str);//新创建根结点
root->m_left = Create(++str);//创建左孩子
root->m_right = Create(++str);//创建右孩子
return root;
}
}
递归实现二叉树的遍历:
先序遍历:
当根节点不空时,将此时根节点值输出,开始递归遍历左子树,不空输出值若为空,则跳出这一层函数,去遍历此时结点处是否有右子树,当为空,则退出返回上一层。一定要理解递归的含义,照着代码照着图自己走一遍,就会理解,后续递归实现遍历和一些操作也都大同小异
void Tree::PreOrderTree(Node* t)//根左右,t为传入根节点
{
if (t == nullptr)return;
else {
//先遍历根,及输出根的值
cout << t->m_value <<" ";
PreOrderTree(t->m_left);
PreOrderTree(t->m_right);
}
}
中序遍历:
void Tree::InOderTree(Node* t)//左根右
{
if (t == nullptr)return;
else {
//如果根不空了先遍历他的左子树
InOderTree(t->m_left);
cout << t->m_value << " ";//左子树完了之后,根,其实就是把根的值输出一下
InOderTree(t->m_right);//完了再遍历他的右子树
}
}
后续遍历:
void Tree::PostOrderTree(Node* t)//左右根
{
if (t == nullptr)return;
else {
PostOrderTree(t->m_left);
PostOrderTree(t->m_right);
cout << t->m_value << " ";
}
}
一些二叉树基本操作:
求树的深度:
依旧用递归来写,求树的深度其实就是求左右子树的深度较大值+1,如果不能理解可以先看看求树的结点个数,我粗略的举个例子,描述一些递归思想,懂了之后,这些基本操作其实递归起来都大差不差。
int Tree::Height(Node* t)
{
if (t== nullptr)
{
return 0;
}
else
{
int h1 = Height(t->m_left);
int h2 = Height(t->m_right);
return h1 > h2 ? h1 + 1 : h2 + 1;
}
}
求树的结点个数:
先看代码:看不懂了照着下面的解释和代码一起看
int Tree::Size(Node* t)//结点个数
{
if (t == nullptr)//如果根是空的,没有结点,返回0
{
return 0;
}
else
{//结点个数就是左子树结点+右子树结点+根结点个数(1)
//左子树一路递归+右子树一路递归+1
return Size(t->m_left) + Size(t->m_right) +1 ;
}
}
* A
* B C 举例
* t等于A不空,所以走到 Size(t->m_left)这一句
* t->m_left就是B
* 此时进入t等于B的Size函数,t不空再走到Size(t->m_left)
* 即新t要等于B的左子树
* 而B的左子树是空,return 0返回到t=B的这一层
* 在t=B的这一层Size(t->m_left) + Size(t->m_right) +1中
* Size(t->m_left)就是0了,等于开始走Size(t->m_right)
* 同上面的思路,B的右孩子是空,返回0,返回到B这一层
* 此时 Size(t->m_right)也是0
* 此时t等于B这一层函数就成了0+0+1,等于1
* 相当于return 1,返回到了t等于A这一层函数
* 此时在A层的函数中,经过前面左子树递归
* 得到1+Size(t->m_right) +1,这下开始从A开始走Size(t->m_right)函数
* 和遍历左子树一个逻辑,最终也会返回一个1
* 最后A这层函数就是1+1+1
* 最终结果就return 3;
查找特定值的结点:
Node* Tree::Search(Node* t, char v)//查找特定值的结点,找到返回结点,没找到返回空
{
if (t == nullptr){
return nullptr;
}
if (t->m_value == v) {
return t;
}
//如果不空,也不是根,那么开始往左子树查找
Node* p = Search(t->m_left, v);
if (p == nullptr)//如果是空,往右边找
return Search(t->m_right, v);
}
查找特定值结点的父结点:
Node* Tree::Search_Parent(Node* t, char v)//特点值结点的父结点
{
if (t == nullptr)
{
return nullptr;
}
if (t->m_left != nullptr && t->m_left->m_value == v)
{
return t;//如果t结点左孩子不空,左孩子值是v,t就是特定结点的父结点
}
if (t->m_right != nullptr && t->m_right->m_value == v)
{
return t;
}
if (Search_Parent(t->m_left, v) != nullptr)//如果左边找到且不空,返回
return Search_Parent(t->m_left, v);
else
return Search_Parent(t->m_right, v);
}
将树拷贝到新树上(二叉树的复制):
void Tree::Copy(Node* &t1, Node* &t)//将t树拷贝到t1上
{
//先拷根,再拷左子树,再拷右子树
if (t == nullptr)
{
t1 = nullptr;
}
else
{
t1=new Node(t->m_value);//申请空间,把根值拷贝
Copy(t1->m_left, t->m_left);//递归把左子树拷过去
Copy(t1->m_right, t->m_right);
}
}
非递归实现遍历:
层次遍历:
对于非递归实现遍历,无非就是模拟如何遍历的过程,这其中我们需要借助栈或者队列去实现。
对于层次遍历而言我们需要借助队列去完成,其他三种需要借助栈去实现。
大致思路为:
- 如果说层次A B C
- 先把A入队,用p保存A的值,然后出队A,然后看p有没有左右孩子
- 如果有入,他的左右孩子B C,然后出队B,p指向B,在看B有没有左右孩子
- 依次类推
注意:一定要画图照着代码去模拟一遍过程,其他三种遍历也是如此。
void Tree::LevelOrder(Node* t)//非递归实现层次遍历
{
queue<Node*>q; //借助队列实现
Node* ff = nullptr;//指向对头的指针,用来后面判断有没有左右孩子,需要入队
if (t == nullptr) return;
else
{
q.push(t); //如果有根,入队
while (!q.empty()) //看队列空不空
{
ff=q.front();//获取对头元素,为了保存下一层的孩子,如果有孩子就需要入队
q.pop();
cout << ff->m_value << " ";
if(ff->m_left!=nullptr)
{
q.push(ff->m_left);
}
if (ff->m_right != nullptr)
{
q.push(ff->m_right);
}
}
}
}
前序遍历:
void Tree::PreOrder_YTree(Node* t)//先序遍历非递归
{
stack<Node*> ss;//用栈
Node* p = nullptr;//用来保存栈顶
//根左右,根入了之后保存栈顶,要按照先入右边再入左边,为的是把右子树保存到栈,左子树访问完了开始访问右子树
//因为栈是先进后出
if (t == nullptr)return;
else
{
ss.push(t);//根入栈
while (!ss.empty())
{
p = ss.top();//保存栈顶元素
ss.pop();
cout << p->m_value << " ";
if (p->m_right != nullptr)
{
ss.push(p->m_right);
}
if (p->m_left != nullptr)
{
ss.push(p->m_left);
}
}
}
}
中序遍历:
大致思路:
- 左根右,访问完最左边孩子,接着要访问他的父结点,所以得保存父结点,自然就能找到右节点
- 先将根以及根以下左子树全部入栈(把路径上的父子结点都保存着)
- 判断栈空不空,不空获取栈顶并出栈
- 并用p记住栈顶的右子树
- 查看当前结点p有没有左子树,如果有则继续压栈左边,如果没有或者为空则返回栈顶(父亲),找栈顶p的右孩子
- 从右孩子这边继续找左,没有,返回这个p,再找他的右子树...
void Tree::InOder_YTree(Node* t)//中序遍历非递归
{
stack<Node*>ss;
Node* p = t;
Node* tmp=nullptr;
if (t == nullptr)return;
else
{
while (p!=nullptr || !ss.empty())
{
while (p!=nullptr)
{
ss.push(p);
p = p->m_left;
}
if (!ss.empty())
{
tmp = ss.top();
ss.pop();
cout << tmp->m_value << " ";
p = tmp->m_right;//当前结点遍历完,记录右子树
}
}
}
}
后续遍历:
- 左右根--> 入的顺序应该根右左
- 注意:需要一个指针记住已经遍历过得结点(刚刚出去的上个结点)
- 原因:入栈:如果当前结点有左右孩子,则按照右左顺序入栈
- 出栈:如果当前结点没有左右孩子,当前结点有孩子,但是孩子已经遍历过了,则出栈
void Tree::PostOrder_YTree(Node* t)//后序遍历非递归
{
if (t != nullptr)
{
stack<Node*> ss;
Node* top = nullptr, * pre = nullptr;
ss.push(t);
while (!ss.empty())
{
top = ss.top();
if (top->m_left == nullptr && top->m_right == nullptr ||
pre != nullptr && top->m_left == pre || pre != nullptr && top->m_right == pre)
{
ss.pop();
cout << top->m_value << " ";
pre = top;
}
else
{
if (top->m_right != nullptr)
ss.push(top->m_right);
if (top->m_left != nullptr)
ss.push(top->m_left);
}
}
}
}
我们在主函数测试一下:
int main()
{
Tree t;
const char* str = "ABDG##HI####CE#J##F##";
t.m_root = t.Create(str);//创建二叉树,返回他的根结点
cout << "先序遍历:" ;
t.PreOrderTree(t.m_root);
cout <<endl;
cout << "中序遍历:";
t.InOderTree(t.m_root);
cout << endl;
cout << "后序遍历:";
t.PostOrderTree(t.m_root);
cout << endl;
cout << "Size为:"<< t.Size(t.m_root)<<endl;
cout << "Height为:" << t.Height(t.m_root) << endl;
Node* p = t.Search(t.m_root, 'E');
if (p== nullptr)
{
cout << "没有找到" << endl;
}
else
cout <<"找到了:"<< p->m_value << endl;
Node* pp = t.Search_Parent(t.m_root, 'B');
if (p == nullptr)
{
cout << "没有找到" << endl;
}
else
{
cout << "找到了:" << pp->m_value << endl;
}
cout << "非递归层次遍历:";
t.LevelOrder(t.m_root);
cout << endl;
cout << "非递归先序遍历:";
t.PreOrder_YTree(t.m_root);
cout << endl;
cout << "非递归中序遍历:";
t.InOder_YTree(t.m_root);
cout << endl;
cout << "非递归后序遍历:";
t.PostOrder_YTree(t.m_root);
cout << endl;
Tree t1;
t1.Copy(t1.m_root, t.m_root);
cout << "拷贝成功后,先序遍历:";
t1.PreOrderTree(t1.m_root);
return 0;
}

本篇旨在讲解二叉树的代码方便查阅
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)