TNASP:基于Transformer和自进化的的NAS Predictor
CVPR2022
Abstract
基于预测器的NAS算法依旧是NAS的一个重要研究课题,因为基于预测器可以有效缩短传统NAS冗长的耗时时间。高性能的predictor决定了最终搜索到的网络性能。目前的predictor主要基于代理数据集上的训练可能存在精度下降和泛化问题,因为他们不能表示图数据结构的空间拓普信息。除了对空间拓普信息的编码能力较差这些研究也没有利用训练过程中的历史评价等时间信息。
本文则提出一种基于Transformer的NAS性能预测器,与基于拉普拉斯的位置编码相结合可以更好的表示拓普信息,在NAS-Bench-101/201和DARTS搜索空间上均取得了更好的性能。此外本文还提出了一个自进化框架可以充分利用时序信息作为指导,通过迭代进化前一评估信息作为约束来纳入当前迭代,从而进一步提升predictor的性能,并且这一框架是模型无关的,因此可提高各种主干结构的性能。本文提出的算法在CVPR2021NAS竞赛中排名第二。
Section I Introduction
NAS致力于在预定义的搜索空间中自动搜索又一网络结构,并且在诸多领域取得了优异的结果。但是基于RL或基于进化学习的NAS算法往往需要消耗成百上千的GPU Hours,限制了NAS算法的实际部署。虽然可微的NAS算法搜索量更小但与传统方法相比,存在优化差距、离散化差距、陷入局部最优等问题。
为了节省NAS的搜索时间,基于predictor的NAS算法使用训练好的性能预测器来快速获得候选模型的性能而无需训练所有的网络结构。这种无需训练的predictor在诸多应用中显示出并不如训练的那么好。因此许多研究致力于设计有效的训练predictor的方法。Predictor一般包括编码模块和回归模块,只需要从一些采样的结构精度中进行学习就可以预测网络结构对应的新京都,大大加速了NAS的搜索过程。
性能预测器的关键部分是将离散的网络结构编码成连续的特征表示。比如Neural Predictor和CTNAS使用GCN来学习输入模型结构的特征表示,SemiNAS和GCN学习候选操作的嵌入矩阵,将网络结构表示为上述嵌入的线性组合。ReNAS会计算类型矩阵、flops矩阵、参数矩阵,将他们级联形成一个特征向量来代表具体的网络结构。本文和它们不同,提出了基于Transformer的NAS Predictor使用网络结构的拉普拉斯矩阵的线性变换输出作为位置编码。
Transformer做预测器有以下优势:
(1)自注意力可以帮助从图结构中搜索更好的特征表示
(2)多头机制可以对不同子空间信息进行编码,这也在Transformer原文中有提及
(3)基于拉布拉斯矩阵的位置编码可以很好的找到图的拓普信息
总之本文证明了Transformer是一种有效地从离散网络结构中提取特征表示并局域良好泛化性来处理未见过的数据。因为Predictor一般都是在一个小规模代理数据集上训练,但测试数据集通常要大得多,泛化性差是普遍的一个问题。功能强大的Transformer可以一定程度上有效缓解这一问题,因为其具有良好的度拓普信息编码的能力。
为了进一步提升predictor的性能本文引入自进化框架可以重温利用时序信息来引导训练。该框架会将前一次预测结果计算一个进化分数作为约束来迭代到本次的进化中从而让预测结果逐渐接近GT。本文证明了这一框架可以让predictor具有更好的泛化性。
本文工作总结如下:
(1)本文提出一个基于Transformer的NAS Predictor来更好的编码空间信息,使用多头注意力机制来将离散网络结构编码成更有意义的特征表述,使用拉普拉斯矩阵的线性变换作为位置编码。
(2)本文利用历史评估分数作为约束条件,应用基于梯度的优化方法来优化predictor的性能,可以充分利用时间信息
。
(3)本文提出的方法在NAS-Bench101/201,DARTS搜索空间超过了之前的SOTA方法
Section II Related Work
鉴于基于强化学习或基于进化算法的NAS需要耗费极大的搜索成本,基于predictor的NAS成为一个热门的研究话题。大部分只需要少量网络结构-精度对即可训练predictor然后对未知的网络结构进行预测,这一类叫做基于训练的predictor。还有的是使用一些网络结构的度量标准来表征网络性能,这一类叫做无训练的predictor.
Training-based network performance predictors
Training-based predictor会学习网路结构与性能之间的映射关系。由于难以从离散的网络结构中学习有用的特征往往会采取将网络结构映射到隐空间的策略,又分为基于序列的方案和基于图的方案。
Sequence-based将网络结构表示为固定长度的向量,然后使用MLP或自编码器,GBDT等将序列转化为连续的表示。
Graph-based将网络结构看做图数据,使用邻接矩阵等作为输入,使用GHN,GIN,WL-Kernel等进行处理。
本文依旧是属于Training_based的方法,只不过使用拉布拉斯矩阵作为位置编码,使用多头注意力机制来编码网络结构从而提取更具表征能力的特征。
Training-free network performance predictors
这一类方法不通过训练而是通过一些评价指标来评估predoctor,比如计算网络二进制编码之间的关系来评分网络;TE-NAS分析的是网络的可训练性和表达性,Zen-NAS通过期望的高斯复杂度来衡量网络的表达性能。尽管这些training-free的方法取得了一些令人满意的结果,但是其鲁棒性无法保证,在不同任务之间存在剧烈波动。与他们相比本文的基于训练的方法虽然更耗时,但是性能要好得多。
Section III Methods
本节首先简要介绍training-based NAS Predictor的普遍范式,然后介绍本文的基于Transformer的predictor。进一步在介绍如何利用验证集上的历史信息来优化predictor.
Part 1 Training-based network performance predictors
之前的一些工作通过搭建一个编码器完成离散网络结构的编码:
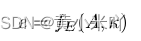
A表示网络节点连接情况的邻接矩阵,N表示节点数目。A表征了网络结构的拓扑信息,一般由GCN或LSTM或者简单的嵌入完成编码器的工作。
将离散的网络结构编码为连续表征之后就可以通过回归进行网络性能的预测了。
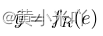
一般使用MSE损失完成encoder和regressor的训练。最优的参数集合表示为:
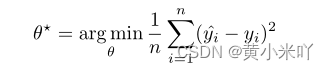
Part 2 Transformer-based predictor
近期Transformer超过了许多SOTA模型,因此也启发我们借鉴使用期强大的encoder部分作为我们predictor的backbone.
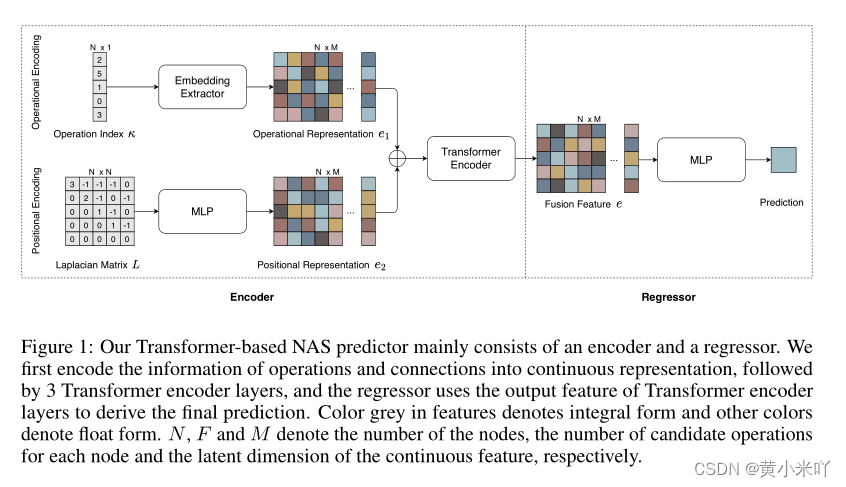
Fig 1展示了本文的基于Transformer的NAS 流程,可以看到包含一个encoder和一个regoressor,首先将网络结构信息编码成连续的表征,这一步通过3个Transformer层实现。regressor使用encoder的输出进行性能预测。灰色部分代表整数格式,其他颜色代表浮点数。
N,F,M分别代表节点数目、每一个节点的候选操作数、隐空间的特征维度。
首先输入的向量k经过嵌入后表示为e1:
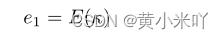
以及为了编码位置信息,本文尝试了诸多方式发现拉普拉斯矩阵是最有效的能够表征网络拓普信息的编码方式,它可以包含图的连接情况和每一个节点的中心情况。因此本文通过邻接矩阵和度矩阵计算出Laplacian matrix,而不是传统Laplacian 矩阵的计算:
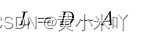
随后本文在通过一个MLP层将L映射到特征向量e2:
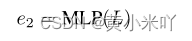
最终经过Transformer的多头注意力米快获得网络结构的连续表示:

因为e包含了更丰富的网络结构信息:操作和连接,因此可以更轻易学到网络结构与精度之间的映射关系,因此本文使用较为简单的2层MLP结构。
Part 3 Self-evolution framework
除了可以更好的编码空间拓扑结构,本文还提出一个自进化框架,可以充分利用训练过程的时序信息。自进化框架会利用前一次在验证集上的验证信息作为本次优化的约束。SE流程参见Fig 2。
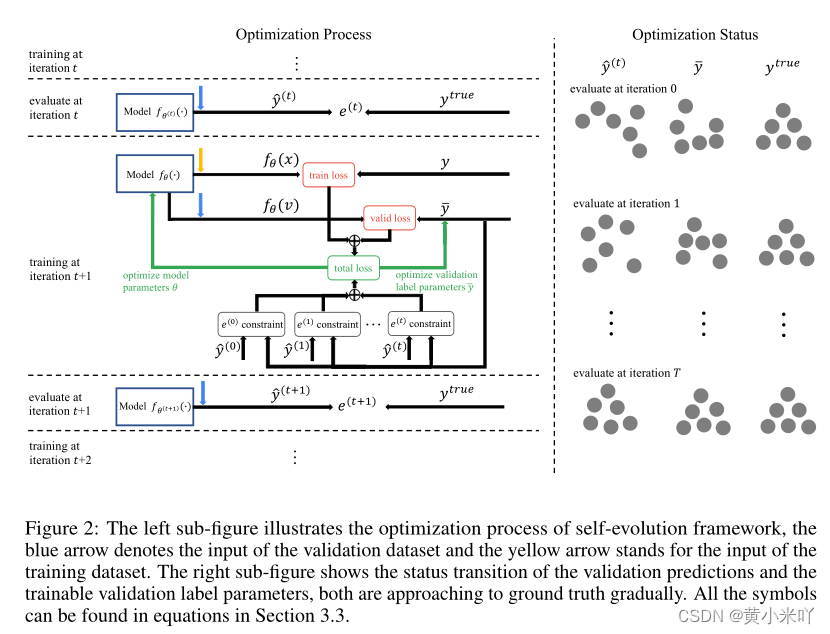
本文这种训练策略针对一些场景十分有效,比如一些ML比赛。在比赛中主办方提供的测试集其实就是本文的验证集,每一次提交的结果都会作为反馈来进行下一次的迭代优化。本文的目标函数表示为:
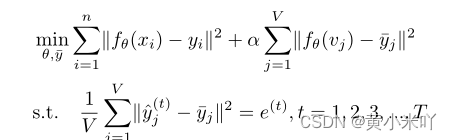
x:training data
v:validation data
alpha:用于平衡训练损失和验证损失的权重系数 不同实验系数不同
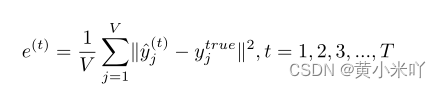
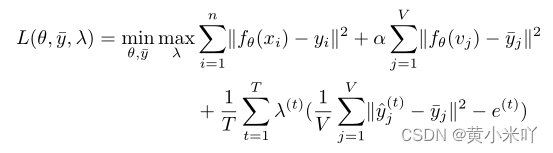
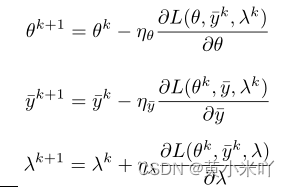
这一自进化框架可以充分利用任何可用信息(比如比赛中的历史提交信息和训练过程中的历史验证信息),SE会直接将每个历史验证评估信息作为训练中的约束条件,并且将训练变成一个极大极小优化问题,使用基于梯度的方法求解。
Section IV Eperiments
本文在三个搜索空间验证TNASP,分别是NAS-Bench-101/201,DARTS。并且与GCN,SemiNAS,BONAS等进行了对比。

Part 1 Experiments on NAS-Bench-101
NAS-Bench-101中包含423624种不同的网络结构,每种网络结构由9种重复单元堆叠而成,每一个单元最多有7个节点和9条边。节点代表候选操作,边代表节点之间的连接关系。NAS-Bench-101提供验证精度和测试精度,本文采取一次运行的验证精度作为训练目标,将三次运行的测试精度均值作为GT。所有模型训练300个epoch。
Table 1展示了与SOTA的对比结果,可以看到当训练数据所占比例极低时,本文的TNASP比Neural Predictor,NAO等方法拥有更高的肯德尔Tao指标,证明了本文的predictor强大的少样本学习能力。随着训练数据比例的提升各种方法的性能均有所上升但本文的TNASP依旧是最优秀的。
从Table 1也可以看出本文的自进化优化框架可以进一步提升predictor的预测性能。
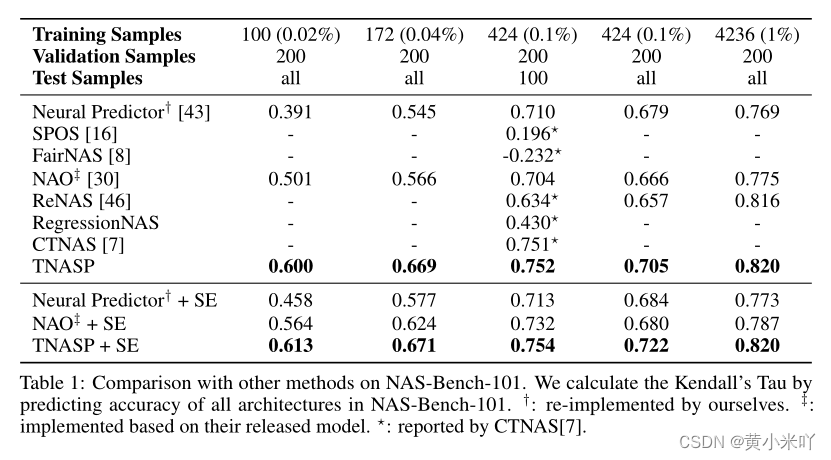
Part 2 Experiments on NAS-Bench-201
NAS-Bench-201也是由单元堆叠而成的各种网络结构,每个单元包含4个节点和6条边,包含5种候选操作,共15625种网络框架。
Table 2展示了在NAS-Bench-201上的实验结果,可以看到与NAS-Bench-101的保持一致。
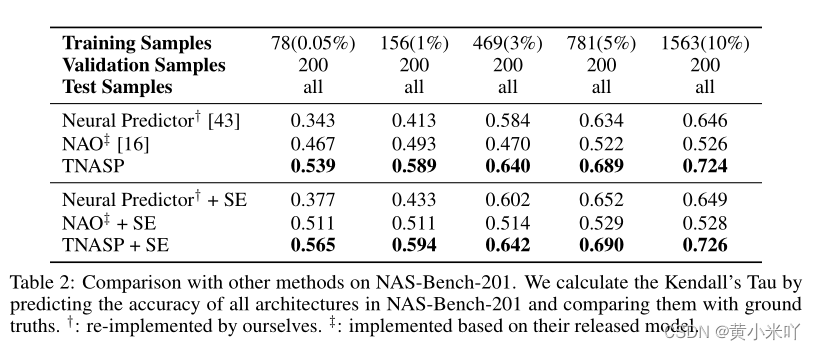
基于上述实验结果的观察可以看到当验证数据比训练数据更多时使用SE自进化可以获得更大的提升;与此相反,当训练数据超过验证数据那么提升效果就没那么明显。
Part 3 Experiments on DARTS
DARTS搜索空间由normal cell和reduction cell组成,每一个单元包含7个节点,14条边,但本文忽略了7种候选操作中的零操作。
本文选择在CIFAR-10上训练的超网均匀采样的1000个网络结构,然后采集他们的测试进度作为本文的训练数据。
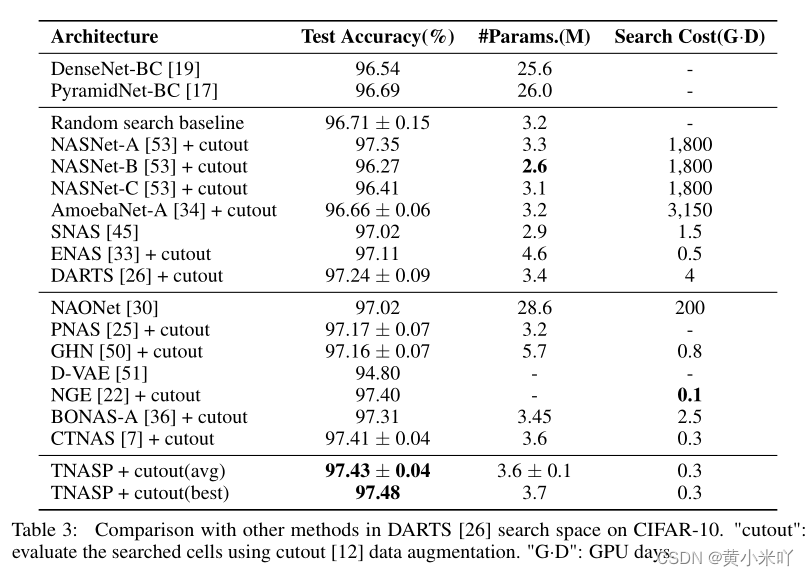
Table 3展示了top-3的网络结构,取他们的平均性能指标。可以看到本文搜索到的cell达到了最高的测试精度-97.48,说明TNASP的predictor学到了最优的结构-性能映射关系。
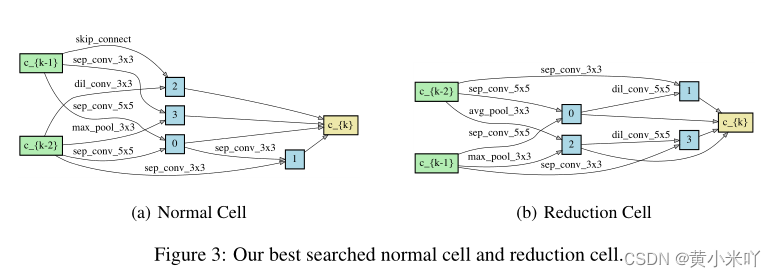
Fig 3展示了搜索到的最优结构,可以看到在reduction cell中出现了一些卷积操作,normal cell中出现了max_pool这些在其他搜索方法的cell中很少出现,说明本文搜索的cell具有新的结构,实现了更高的测试精度,比其他方法达到了更好的局部最小值。在未来探索不同搜索到的cell之间的本质差异也是一个有意思的课题。
Part 4 Ablation studies
Different positional encoding strageties
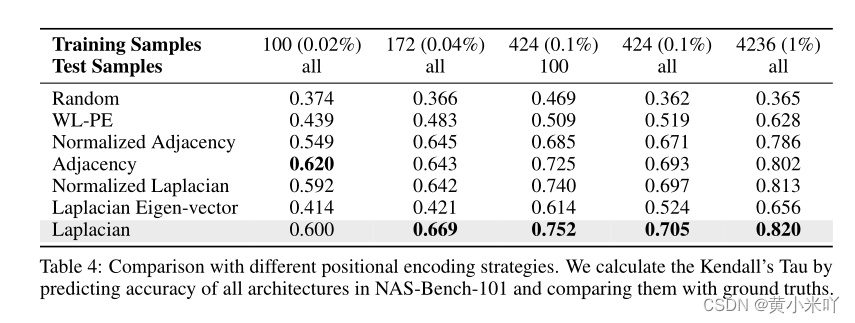
Table 4展示了使用不同位置编码方案的对比结果,可以看到当训练数据=100.Laplacian matrix 获得了最优精度;有趣的一点是传统的Laplacian matrix反而性能没那么好。
Different evaluation numbers
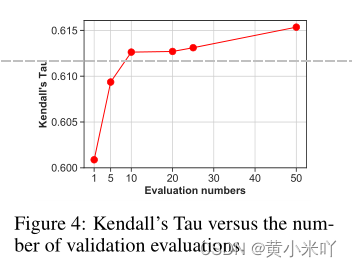
我们研究了了执行的评估的数量和最终的肯德尔的Tau值的关系。如Fig 4所示,当评估的次数增加时
从1到10,我们可以看到肯德尔Tau的显著增加
。然而,当评估的数量继续增长肯德尔Tau值似乎逐渐饱和,但是训练时间增加了很多。因此,我们
选择在验证数据集上自进化框架评估10次。
Rethinking results over only good architectures
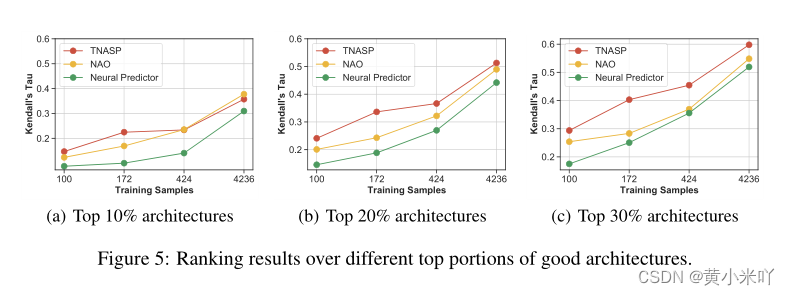
一般我们更关注搜索到的最优秀的网络结构长什么样,因此本文在NAS-Bench-101数据集上以肯德尔Tau作为对比指标比较不同的方法,Fig 5可以看出top-10%的中NAO和本文的TNASP结果接近,而top-20%.30%,TNASP搜索到的网络结构性能更好。
Section V Conclusion
本文提出一种基于Transformer的NAS Predictor,使用Laplacian矩阵的线性变换作为位置编码方案。这种Predictor具有更好的编码空间拓扑结构的能力,在三种benchmark上均超过了SOTA。进一步本文还提出了一种通用的自进化框架可以利用训练的历史信息来优化Predictor。但是本文并没有讨论更复杂的指标,比如不可微的指标来作为框架的约束。
未来本文将进一步探索选择更合理、有效的约束条件来稳定高效的提升NAS Predictor的预测性能。