
簇识别:
簇识别给出了聚类结果的含义,假定有一些数据,簇识别会告诉我们这些簇到底都是些什么。
聚类与分类的区别:
分类的目标事先已知,但是聚类的类别没有事先定义,故聚类也称无监督分类。
10.1 K-均值聚类算法

K-均值是发现给定数据集的k个簇的算法,簇个数k是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。
K-均值算法工作流程:
1)随机确定k个初始点作为质心
2)将数据集中的每个点分配到一个簇中,即为每个点找到距离其最近的质心,并将其分配给该质心所对应的簇,该步骤完成后,每个簇的质心更新为该簇所有点的平均值。
伪代码:
随机创建K个质心为起始点
当任意一个点的簇分配结果发生变化时
对每一个数据点
对每个质心
计算数据点和之心之间的距离
将数据点分配到距离最近的簇中
对每个簇,计算所有点的均值更新质心
具体做法:
1、 随机选取k个聚类质心点(cluster centroids)为
μ
1
,
μ
2
,
.
.
.
,
μ
k
∈
R
n
\mu_1,\mu_2,...,\mu_k\in R^n
μ1,μ2,...,μk∈Rn。
2、 重复下面过程直到收敛
{
对于每一个样例i,计算其应该属于的类别
c
(
i
)
:
=
a
r
g
m
i
n
j
∣
∣
x
(
i
)
−
μ
j
∣
∣
2
c^{(i)}:=arg min_j||x^{(i)}-\mu_{j}||^2
c(i):=argminj∣∣x(i)−μj∣∣2
,对于每一个类 j,重新计算该类的质心

}
K 是我们事先给定的聚类数,
c
(
i
)
c^{(i)}
c(i) 代表样例i与k个类中距离最近的那个类,
c
(
i
)
c^{(i)}
c(i)的值是1到k中的一个。质心
μ
j
\mu_j
μj 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心.
一般流程:

下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。
收敛性:
首先定义畸变函数:
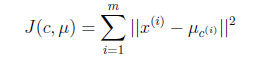
J 函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心
μ
j
\mu_j
μj,调整每个样例的所属的类别
c
(
i
)
c^{(i)}
c(i)来让J函数减少,同样,固定
c
(
i
)
c^{(i)}
c(i),调整每个类的质心
μ
j
\mu_j
μj也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
μ
\mu
μ和
c
c
c也同时收敛。(在理论上,可以有多组不同的clip_image018[7]和c值能够使得J取得最小值,但这种现象实际上很少见)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较敏感,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的
μ
\mu
μ 和
c
c
c 输出。
K-均值聚类支持函数:
from numpy import *
def loadDataSet(fileName):
"""
加载数据集
:param fileName: 文件名称
:return:
"""
dataMat=[]
fr=open(fileName)
for line in fr.readlines():
curLine=line.strip().split('\t')
# map函数的主要功能是
# 对一个序列对象中的每一个元素应用被传入的函数,并且返回一个包含了所有函数调用结果的一个列表
# 这里从文件中读取的信息是字符型,通过map函数将其强制转化为浮点型
frtLine=map(float,curLine)
dataMat.append(frtLine)
return dataMat
def distEclud(vecA,vecB):
"""
计算两个向量间的距离
:param vecA:
:param vecB:
:return:
"""
#np.power(x1, 2):数组x1的元素求2次方
return sqrt(sum(power(vecA-vecB,2)))
def randCent(dataSet,k):
"""
随机构建初始质心
:param dataSet: 数据集
:param k: k个随机质心
:return:
"""
#求列数
n=shape(dataSet)[1]
#初始化质心
centroids=mat(zeros(k,n))
for j in range(n):
#求每一维数据的最大值和最小值,保证随机选取的质心在边界内
minJ=min(dataSet[:,j])
maxJ=max(dataSet[:,j])
rangeJ=float(maxJ-minJ)
centroids[:,j]=minJ+rangeJ*random.rand(k,1)
return centroids
数据集:testSet.txt
#################################################
# kmeans: k-means cluster
# Author : zouxy
# Date : 2013-12-25
# HomePage : http://blog.csdn.net/zouxy09
# Email : zouxy09@qq.com
#################################################
from numpy import *
import time
import matplotlib.pyplot as plt
# calculate Euclidean distance
def euclDistance(vector1, vector2):
return sqrt(sum(power(vector2 - vector1, 2)))
# init centroids with random samples
def initCentroids(dataSet, k):
numSamples, dim = dataSet.shape
centroids = zeros((k, dim))
for i in range(k):
index = int(random.uniform(0, numSamples))
centroids[i, :] = dataSet[index, :]
return centroids
# k-means cluster
def kmeans(dataSet, k):
numSamples = dataSet.shape[0]
# first column stores which cluster this sample belongs to,
# second column stores the error between this sample and its centroid
clusterAssment = mat(zeros((numSamples, 2)))
clusterChanged = True
## step 1: init centroids
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
## for each sample
for i in range(numSamples):
minDist = 100000.0
minIndex = 0
## for each centroid
## step 2: find the centroid who is closest
for j in range(k):
distance = euclDistance(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
## step 3: update its cluster
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
## step 4: update centroids
for j in range(k):
pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]
centroids[j, :] = mean(pointsInCluster, axis=0)
print('Congratulations, cluster complete!')
return centroids, clusterAssment
# show your cluster only available with 2-D data
def showCluster(dataSet, k, centroids, clusterAssment):
numSamples, dim = dataSet.shape
if dim != 2:
print("Sorry! I can not draw because the dimension of your data is not 2!")
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("Sorry! Your k is too large! please contact Zouxy")
return 1
# draw all samples
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=12)
plt.show()
if __name__=='__main__':
## step 1: load data
print("step 1: load data...")
dataSet = []
fileIn = open('testSet.txt')
for line in fileIn.readlines():
lineArr = line.strip().split('\t')
dataSet.append([float(lineArr[0]), float(lineArr[1])])
## step 2: clustering...
print( "step 2: clustering...")
dataSet = mat(dataSet)
k = 4
centroids, clusterAssment = kmeans(dataSet, k)
## step 3: show the result
print("step 3: show the result...")
showCluster(dataSet, k, centroids, clusterAssment)
结果:

不同的类型用不同的颜色来表示,大菱形是对应类的均值质心点。
由于基本K均值聚类算法质心选择的随机性,其聚类的结果一般比较随机,一般不会很理想,最终结果往往出现自然簇无法区分的情况,为避免此问题,下面介绍二分K均值聚类算法。
质心:
centroids, clusterAssment
[[-3.53973889 -2.89384326]
[ 3.54988221 -2.50520707]
[ 1.27051487 -2.7993025 ]
[-0.02298687 2.99472915]]
10.2 使用后处理来提高聚类性能
k是用户自定义的参数,但是无法确定k的选取是否正确,如何才能判断生成的簇效果是否好呢,每个点的误差是点到簇质心的距离平方值。

上图中簇的分配结果值没有那么准确,k-均值算法收敛但是聚类效果差的原因是,k-均值算法收敛到了局部最小值,而非全局最小值。
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和),对应clusterAssment矩阵的第一列之和,SSE值越小表示数据点越接近于其质心,聚类效果越好。因为对误差取了平方,因此更加重视那些远离中心的点,一种肯定可以降低SSE值的方法是增加簇的个数,但是这违背了聚类的目标,聚类的目标是在不增加簇的情况下,提高簇的质量。
如何对图10-2的结果进行改进,可以对生成的簇进行后处理,一种方法是将具有最大SSE值的簇划分为两个簇。
为了保持簇的总数不变,可以将某两个簇进行合并。
如何合并:
1)合并最近的质心
通过计算所有质心之间的距离,合并两个距离最近的点。
2)合并两个使得SSE增幅最小的质心
10.3 二分K-均值算法
该算法首先将所有的点当成一个簇,然后将该簇一分为二。之后选择其中一个簇进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。不断重复该过程,直到达到用户所需要的簇个数为止。
伪代码:
将所有的点看成一个簇
当簇数目小于k时
对每一个簇
计算总误差
在给定的簇上面进行二分k-均值聚类
计算一分为二之后的总误差
选择使得误差最小的那个簇进行划分
代码:
#################################################
# kmeans: k-means cluster
# Author : zouxy
# Date : 2013-12-25
# HomePage : http://blog.csdn.net/zouxy09
# Email : zouxy09@qq.com
#################################################
from numpy import *
import time
import matplotlib.pyplot as plt
# calculate Euclidean distance
def euclDistance(vector1, vector2):
return sqrt(sum(power(vector2 - vector1, 2)))
# init centroids with random samples
def initCentroids(dataSet, k):
numSamples, dim = dataSet.shape
centroids = zeros((k, dim))
for i in range(k):
index = int(random.uniform(0, numSamples))
centroids[i, :] = dataSet[index, :]
return centroids
# k-means cluster
def kmeans(dataSet, k):
numSamples = dataSet.shape[0]
# first column stores which cluster this sample belongs to,
# second column stores the error between this sample and its centroid
clusterAssment = mat(zeros((numSamples, 2)))
clusterChanged = True
## step 1: init centroids
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
## for each sample
for i in range(numSamples):
minDist = 100000.0
minIndex = 0
## for each centroid
## step 2: find the centroid who is closest
for j in range(k):
distance = euclDistance(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
## step 3: update its cluster
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
## step 4: update centroids
for j in range(k):
pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]
centroids[j, :] = mean(pointsInCluster, axis=0)
return centroids, clusterAssment
# bisecting k-means cluster
def biKmeans(dataSet, k):
numSamples = dataSet.shape[0]
# first column stores which cluster this sample belongs to,
# second column stores the error between this sample and its centroid
clusterAssment = mat(zeros((numSamples, 2)))
# step 1: the init cluster is the whole data set
centroid = mean(dataSet, axis=0).tolist()[0]
centList = [centroid]
for i in range(numSamples):
clusterAssment[i, 1] = euclDistance(mat(centroid), dataSet[i, :]) ** 2
while len(centList) < k:
# min sum of square error
minSSE = 100000.0
numCurrCluster = len(centList)
# for each cluster
for i in range(numCurrCluster):
# step 2: get samples in cluster i
pointsInCurrCluster = dataSet[nonzero(clusterAssment[:, 0].A == i)[0], :]
# step 3: cluster it to 2 sub-clusters using k-means
centroids, splitClusterAssment = kmeans(pointsInCurrCluster, 2)
# step 4: calculate the sum of square error after split this cluster
splitSSE = sum(splitClusterAssment[:, 1])
notSplitSSE = sum(clusterAssment[nonzero(clusterAssment[:, 0].A != i)[0], 1])
currSplitSSE = splitSSE + notSplitSSE
# step 5: find the best split cluster which has the min sum of square error
if currSplitSSE < minSSE:
minSSE = currSplitSSE
bestCentroidToSplit = i
bestNewCentroids = centroids.copy()
bestClusterAssment = splitClusterAssment.copy()
# step 6: modify the cluster index for adding new cluster
bestClusterAssment[nonzero(bestClusterAssment[:, 0].A == 1)[0], 0] = numCurrCluster
bestClusterAssment[nonzero(bestClusterAssment[:, 0].A == 0)[0], 0] = bestCentroidToSplit
# step 7: update and append the centroids of the new 2 sub-cluster
centList[bestCentroidToSplit] = bestNewCentroids[0, :]
centList.append(bestNewCentroids[1, :])
# step 8: update the index and error of the samples whose cluster have been changed
clusterAssment[nonzero(clusterAssment[:, 0].A == bestCentroidToSplit), :] = bestClusterAssment
return mat(centList), clusterAssment
# show your cluster only available with 2-D data
def showCluster(dataSet, k, centroids, clusterAssment):
numSamples, dim = dataSet.shape
if dim != 2:
print("Sorry! I can not draw because the dimension of your data is not 2!")
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("Sorry! Your k is too large!")
return 1
# draw all samples
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=12)
plt.show()
if __name__=='__main__':
#################################################
# kmeans: k-means cluster
# Author : zouxy
# Date : 2013-12-25
# HomePage : http://blog.csdn.net/zouxy09
# Email : zouxy09@qq.com
#################################################
from numpy import *
import time
import matplotlib.pyplot as plt
## step 1: load data
print("step 1: load data...")
dataSet = []
fileIn = open('testSet2.txt')
for line in fileIn.readlines():
lineArr = line.strip().split('\t')
dataSet.append([float(lineArr[0]), float(lineArr[1])])
## step 2: clustering...
print( "step 2: clustering...")
dataSet = mat(dataSet)
k = 3
centroids, clusterAssment = biKmeans(dataSet, k)
## step 3: show the result
print("step 3: show the result...")
showCluster(dataSet, k, centroids, clusterAssment)
结果:

10.4 总结
1)优点:
2)缺点:
- 1.收敛太慢
- 2.算法复杂度高O(nkt)
- 3.不能发现非凸形状的簇,或大小差别很大的簇
- 4.需样本存在均值(限定数据种类)
- 5.需先确定k的个数
- 6.对噪声和离群点敏感
- 7.最重要是结果不一定是全局最优,只能保证局部最优。
3)改进算法: