声明:文中所有使用图片均来自网络,侵删。
什么是LSTM
LSTM(Long Short-Term Memory网络),是一种特殊的RNN类型,可以有效解决RNN神经网络存在的长期依赖问题。通过模仿人脑可以进行遗忘的功能,在每一个LSTM模块中加入了遗忘门,对信息进行处理,具体如下:

遗忘门
通过全部的LSTM网络图片可以观察到,每一个单元的输入不仅仅只是X_t,还包括前一个单元的输出状态H_t-1,下面我们对单个的LSTM单元进行分析
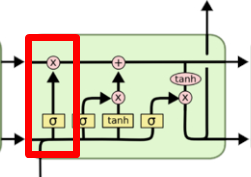
输入的数据X_t和上一时刻状态H_t-1一起传入当前时刻的LSTM单元,通过第一个SIGMOD函数,即所谓的遗忘门,因为SIGMOD函数输出值如下图所示在0-1之间,所以相当于给信息赋权,决定哪些信息会被遗忘。

输入门
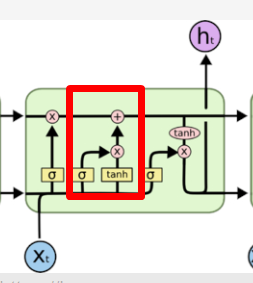
这一道门决定哪些信息会被真正地输入到记忆中(就好像人脑一样,记不下所有的输入信息)。其中,由于SIGMOD函数输出为0-1的特性,它可以决定输入多少比列的信息(加权)
tanh函数决定着输入什么信息(对信息进行加工处理)

输出门
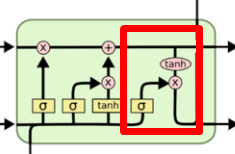
输出当前状态和隐藏状态
如何使用(基于pytorch)
上述理论看似需要很多数学运算,但实际上我们使用Python编写LSTM时算法时,不需要自己编写这些,只需要调用库文件里的封装好的API就行。这里我们使用pytorch库进行编写
我们先进行简单的运用,生成一组数据表示要处理的文本,对它运用LSTM
import torch
# 1 设置参数
batch_size = 10 # 设置每一组取词数量
seq_len = 20 # 设置每一次取多少组
embedding_dim = 30 # 将文件用多少维的数据表示
hidden_size = 22 # 每一层隐藏层有多少LSTM单元
num_layer = 2 # 有多少层隐藏层
voc_doc = 200 # 要训练的文本中有多少不一样的词
# 2 导入文本对象
text = torch.randint(low=0, high=100, size=(seq_len, batch_size))
# 3 实例化API
'''
torch.nn.Embedding(voc_doc, embedding_dim)
一个将文本转化成数字数据的API
'''
embedding = torch.nn.Embedding(voc_doc, embedding_dim)
embed = embedding(text)
lstm = torch.nn.LSTM(embedding_dim, hidden_size, num_layer)
# 4 开整
out, (h_n, c_n) = lstm(embed)
注意:
- 在第12行代码中,如果batch_size和seq_len位置调换,在实例化LSTM时必须添加一个参数batch_first=True,如下
text = torch.randint(low=0, high=100, size=(batch_size, seq_len))
lstm = torch.nn.LSTM(embedding_dim, hidden_size, num_layer, batch_first=True)
具体原因请查阅torch.nn.LSTM函数文档
- 实例化LSTM对象之后,不仅需要传入数据,还需要前一次的h_0(前一次的隐藏状态)和c_0(前一次memory),即:lstm(input,(h_0,c_0)),如果不进行设置,则LSTM的默认输出为output, (h_n, c_n)
可以在上述代码中添加以下代码查看输出结果
print(out)
print("*"*100)
print(h_n)
print("*"*100)
print(c_n)