DCGAN介绍
将CNN和GAN结合起来,把监督学习和无监督学习结合起来。具体解释可以参见 深度卷积对抗生成网络(DCGAN)
DCGAN的生成器结构:

图片来源:https://arxiv.org/abs/1511.06434
代码
model.py
import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# Input: N x channels_img x 64 x 64
nn.Conv2d(
channels_img, features_d, kernel_size=4, stride=2, padding=1
), # 32 x 32
nn.LeakyReLU(0.2),
self._block(features_d, features_d*2, 4, 2, 1), # 16 x 16
self._block(features_d*2, features_d*4, 4, 2, 1), # 8 x 8
self._block(features_d*4, features_d*8, 4, 2, 1), # 4 x 4
nn.Conv2d(features_d*8, 1, kernel_size=4, stride=2, padding=0), # 1 x 1
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, z_dim, channels_img, features_g):
super(Generator, self).__init__()
self.gen = nn.Sequential(
# Input: N x z_dim x 1 x 1
self._block(z_dim, features_g*16, 4, 1, 0), # N x f_g*16 x 4 x 4
self._block(features_g*16, features_g*8, 4, 2, 1), # 8x8
self._block(features_g*8, features_g*4, 4, 2, 1), # 16x16
self._block(features_g*4, features_g*2, 4, 2, 1), # 32x32
nn.ConvTranspose2d(
features_g*2, channels_img, kernel_size=4, stride=2, padding=1,
),
nn.Tanh(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.gen(x)
def initialize_weights(model):
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
def test():
N, in_channels, H, W = 8, 3, 64, 64
z_dim = 100
x = torch.randn((N, in_channels, H, W))
disc = Discriminator(in_channels, 8)
initialize_weights(disc)
assert disc(x).shape == (N, 1, 1, 1)
gen = Generator(z_dim, in_channels, 8)
initialize_weights(gen)
z = torch.randn((N, z_dim, 1, 1))
assert gen(z).shape == (N, in_channels, H, W)
print("success")
if __name__ == "__main__":
test()
训练使用的数据集:CelebA dataset (Images Only) 总共1.3GB的图片,使用方法,将其解压到当前目录
图片如下图所示:

train.py
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator, initialize_weights
# Hyperparameters etc.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
LEARNING_RATE = 2e-4 # could also use two lrs, one for gen and one for disc
BATCH_SIZE = 128
IMAGE_SIZE = 64
CHANNELS_IMG = 3 # 1 if MNIST dataset; 3 if celeb dataset
NOISE_DIM = 100
NUM_EPOCHS = 5
FEATURES_DISC = 64
FEATURES_GEN = 64
transforms = transforms.Compose(
[
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
]
)
# If you train on MNIST, remember to set channels_img to 1
# dataset = datasets.MNIST(
# root="dataset/", train=True, transform=transforms, download=True
# )
# comment mnist above and uncomment below if train on CelebA
# If you train on celeb dataset, remember to set channels_img to 3
dataset = datasets.ImageFolder(root="celeb_dataset", transform=transforms)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
criterion = nn.BCELoss()
fixed_noise = torch.randn(32, NOISE_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0
gen.train()
disc.train()
for epoch in range(NUM_EPOCHS):
# Target labels not needed! <3 unsupervised
for batch_idx, (real, _) in enumerate(dataloader):
real = real.to(device)
noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)
fake = gen(noise)
### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1)
loss_disc_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = disc(fake.detach()).reshape(-1)
loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
loss_disc = (loss_disc_real + loss_disc_fake) / 2
disc.zero_grad()
loss_disc.backward()
opt_disc.step()
### Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
output = disc(fake).reshape(-1)
loss_gen = criterion(output, torch.ones_like(output))
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# Print losses occasionally and print to tensorboard
if batch_idx % 100 == 0:
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(dataloader)} \
Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}"
)
with torch.no_grad():
fake = gen(fixed_noise)
# take out (up to) 32 examples
img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)
img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True)
writer_real.add_image("Real", img_grid_real, global_step=step)
writer_fake.add_image("Fake", img_grid_fake, global_step=step)
step += 1
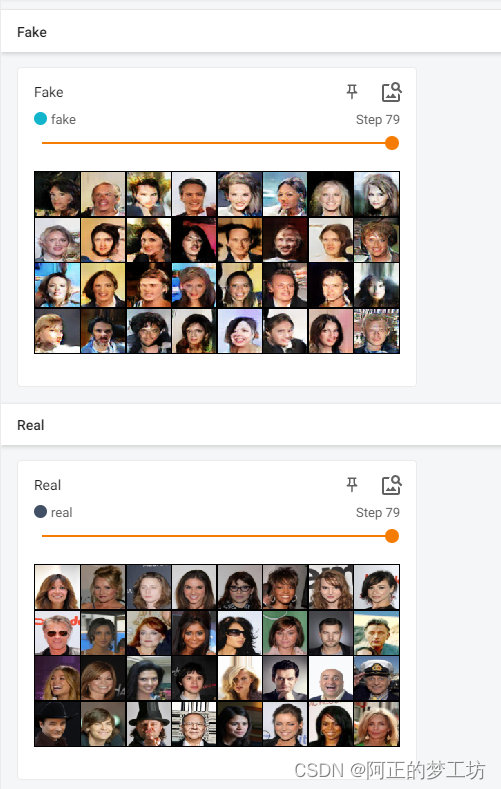
结果
训练5个epoch,部分结果如下:
Epoch [3/5] Batch 1500/1583 Loss D: 0.4996, loss G: 1.1738
Epoch [4/5] Batch 0/1583 Loss D: 0.4268, loss G: 1.6633
Epoch [4/5] Batch 100/1583 Loss D: 0.4841, loss G: 1.7475
Epoch [4/5] Batch 200/1583 Loss D: 0.5094, loss G: 1.2376
Epoch [4/5] Batch 300/1583 Loss D: 0.4376, loss G: 2.1271
Epoch [4/5] Batch 400/1583 Loss D: 0.4173, loss G: 1.4380
Epoch [4/5] Batch 500/1583 Loss D: 0.5213, loss G: 2.1665
Epoch [4/5] Batch 600/1583 Loss D: 0.5036, loss G: 2.1079
Epoch [4/5] Batch 700/1583 Loss D: 0.5158, loss G: 1.0579
Epoch [4/5] Batch 800/1583 Loss D: 0.5426, loss G: 1.9427
Epoch [4/5] Batch 900/1583 Loss D: 0.4721, loss G: 1.2659
Epoch [4/5] Batch 1000/1583 Loss D: 0.5662, loss G: 2.4537
Epoch [4/5] Batch 1100/1583 Loss D: 0.5604, loss G: 0.8978
Epoch [4/5] Batch 1200/1583 Loss D: 0.4085, loss G: 2.0747
Epoch [4/5] Batch 1300/1583 Loss D: 1.1894, loss G: 0.1825
Epoch [4/5] Batch 1400/1583 Loss D: 0.4518, loss G: 2.1509
Epoch [4/5] Batch 1500/1583 Loss D: 0.3814, loss G: 1.9391
使用
tensorboard --logdir=logs
打开tensorboard
参考
[1] DCGAN implementation from scratch
[2] https://arxiv.org/abs/1511.06434