记录笔记原则:
1.用简单易懂的语言叙述自己的理解,避免照搬原文
2.用实例说明,避免空洞
3.多做总结和横向对比,避免片面
面向对象三个基本概念
抽象;继承;动态绑定;
继承使我们简化了类的定义;
动态绑定使我们简化了接口的实现,使得所有继承层次的类可以使用同一个函数接口;
动态绑定的两个条件
通过基类的引用(或指针)调用虚函数,才发生动态绑定;
非虚函数的调用在编译阶段确定,虚函数的调用在运行阶段动态确定;
一旦函数在基类中声明为虚函数,它就一直为虚函数了,派生类中不需再次声明为virtual了;
派生类对象由两部分组成:派生类本身的成员+基类的子对象
强制调用基类的虚函数
Base *p = &derived;
p->Base::hello();
访问控制
class Base
{
public:
int a;
protected:
int b;
private:
int c;
void funcA();
};
class PublicDerived: public Base
{
public:
void funcB();
};
class ProtectedDerived: protected Base
{
public:
void funcB();
};
class PrivateDerived: private Base
{
public:
void funcB();
};
派生类成员不能访问基类的private成员;
对继承的成员访问由基类中的访问控制和派生标号共同控制;
派生标号只是控制用户代码对基类成员的访问,派生类成员函数对基类成员的访问控制不受影响;
下面是公有派生、保护派生、私有派生下,基类成员函数、派生类成员函数、用户代码对基类成员的可访问情况:
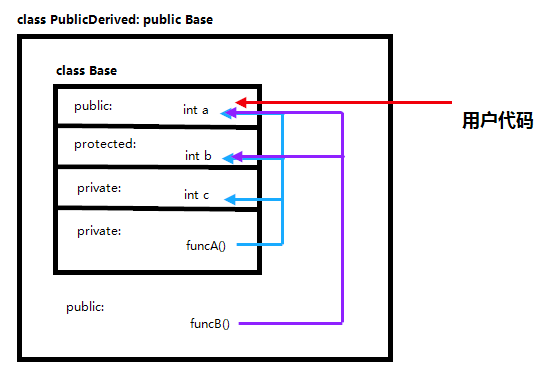
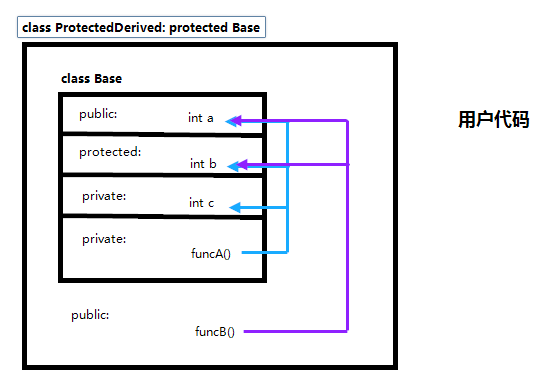

公有派生,用户代码可访问基类的public成员;保护派生,基类中的公有成员和保护成员变成派生类中的保护成员,用户代码不能访问基类的任何成员;私有派生,基类中的公有成员和保护成员变成私有成员,用户代码不能访问基类成员;
派生类构造函数和复制控制函数
派生类构造函数初始化列表顺序:首先初始化基类,然后根据声明次序初始化派生类自身的成员;
派生类合成的析构函数不负责撤销基类对象成员,由编译器自动调用基类的析构函数;
虚析构函数
基类的析构函数必须为虚函数;
Base *p = new Derived();
delete p;
如果析构函数不是虚函数,delete将只调用基类的析构函数;
屏蔽与虚函数
同名函数,即使函数参数不同,基类成员也会被屏蔽,因为编译器一旦找到名字,就不继续找了,找到名字后再做参数检查;
struct Base
{
int func();
};
struct Derived: public Base
{
int func(int);
};
Derived d;
d.func(10); // ok,调用派生类函数
d.func(); // error,参数不匹配
d.Base::func(); // ok,强制调用基类函数
更复杂一点的例子
struct Base {
virtual int fcn();
};
struct D1: public Base {
int fcn(int);
};
struct D2: public D1 {
int fcn(int);
int fcn();
};
Base *p1 = new Base();
Base *p2 = new D1();
Base *p3 = new D2();
p1->fcn(); // ok, 调用基类函数
p2->fcn(); // ok, 调用基类函数
p3->fcn(); // ok, 调用D2类函数
上面三个调用都是动态绑定,p2的实际对象时D1,D1类没有重定义虚函数版本,所以将调用基类的虚函数版本;
编译器确定函数调用步骤
1.确定调用者的指针、引用、对象的静态类型(编译可知的直接类型);
2.在该类中查找函数,找不到在基类中继续找,如此回溯;
3.一旦找到名字,就不继续找了,并进行类型检查,这时如果发现参数不匹配就出错了;
4.如果发现该函数是虚函数,并且通过指针(引用)调用,则编译器生成代码在运行阶段动态绑定函数版本,否则,编译器直接调用该函数;
纯虚函数
意义:不想让用户创建对象,只是规范接口;
形式
virtual void hello() = 0;
含有纯虚函数的类是抽象基类;
派生类必须重定义接口;