需求确定
需求是数据分析的起点,在没有搞清楚需求的情况下,盲目的抓取一大把数据胡乱分析,最终得不出有用的结论。
本次数据分析的目的如下:
- 工作年限与薪资之间的关系
- 不同工作年限薪资水平变化规律
- 北京地区招聘数据分析师岗位公司的分布
- 招聘数据分析师的公司类型与薪资关系
- 数据分析师的岗位职责及要求
- ……
分析网页结构
打开拉勾网站,城市选择北京,输入数据分析师,进入数据分析师岗位招聘页面。
右键单击检查
如图,切换到需要的数据前面。
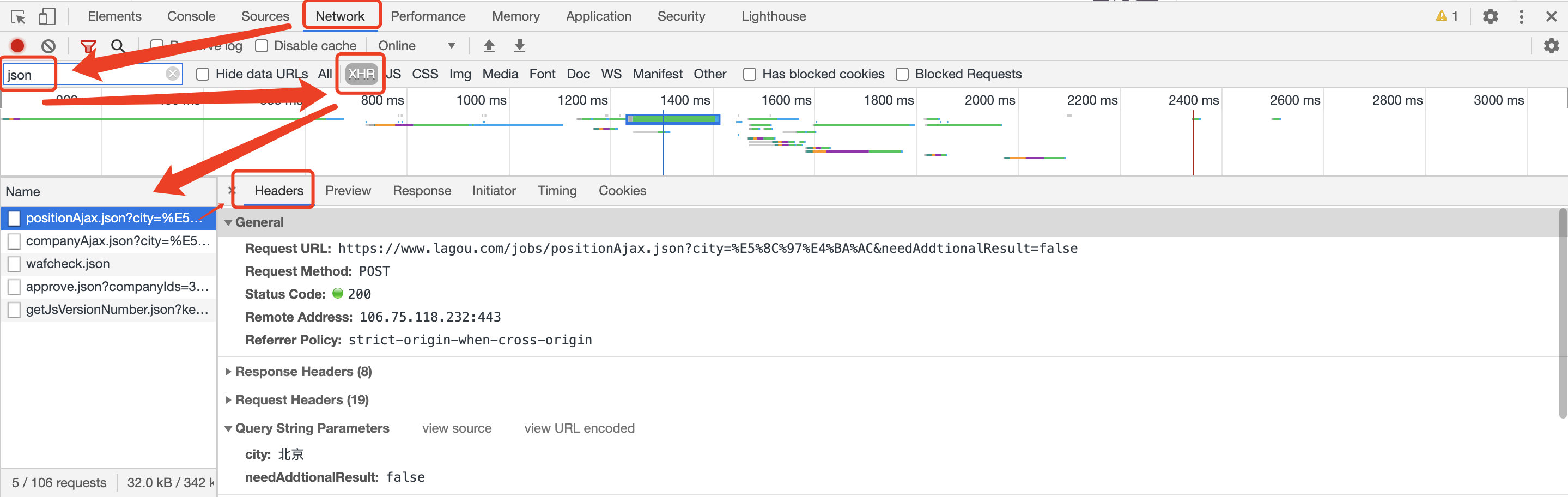
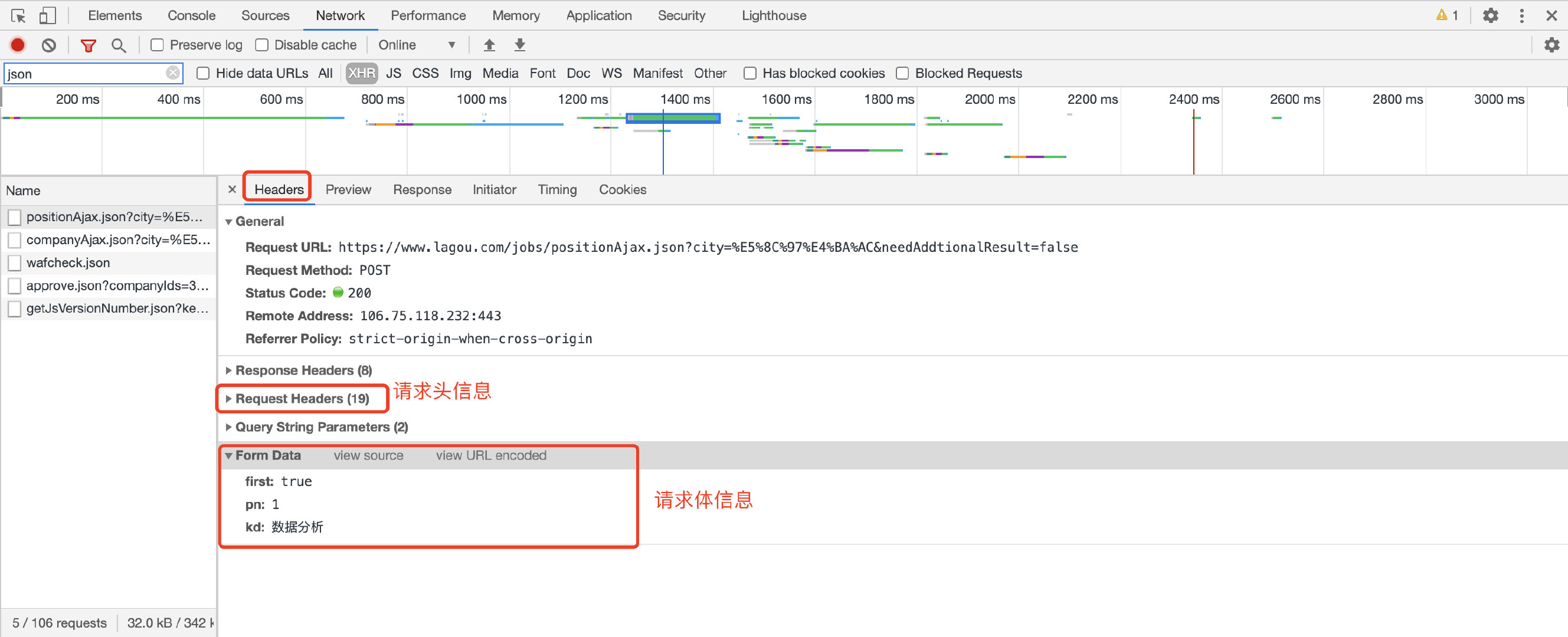
分析网页结构,可以找到请求代URL,表头等数据信息。
代码如下
import requests
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 从制定的url中通过requests请求携带请求头和请求体获取网页中的信息
def get_json(url, num):
url1 = 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput='
headers = {
'origin': 'https://www.lagou.com'
'referer‘:’https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'x-anit-forge-code': '0',
'x-anit-forge-token': 'None',
'x-requested-with': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num,
'kd': '数据分析'}
s = requests.Session()
print('建立session: ', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie: ', cookie, '\n\n')
res =requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.ending = 'utf-8'
page_data = res.json()
print('请求相应结果: ', page_data, '\n\n')
return page_data
print(get_json(url, 1))
代码问题
代码出现了下面的问题,弄了半天都没有解决,有大佬能帮忙看一下么?
