scrapy爬虫的搭建过程(实战篇)
1. 爬虫功能
2. 环境
- 系统:win7
- Scrapy 1.4.0
- mongodb v3.2
- python 3.6.1
3. 代码
3.1. 创建爬虫项目
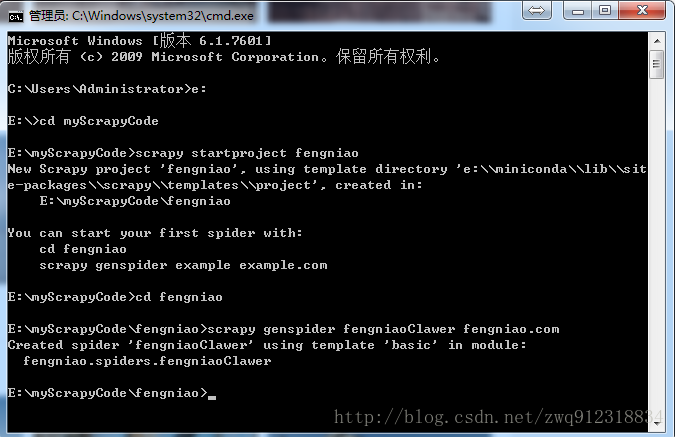
# 第一步,进入需要防止爬虫代码的位置,下图中指定目录为:E:\myScrapyCode
scrapy startproject fengniao #创建一个爬虫项目fengniao
cd fengniao #进入到爬虫项目目录
scrapy genspider fengniaoClawer fengniao.com #创建一个具体的爬虫fengniaoClawer, 并初始化域名
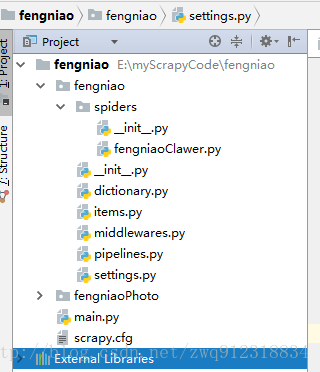
3.2. 代码结构
3.3. 详细代码
# 文件:fengniaoClawer.py
# -*- coding: utf-8 -*-
import scrapy
from fengniao.items import FengniaoItem
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import TimeoutError, TCPTimedOutError, DNSLookupError, ConnectionRefusedError
class FengniaoclawerSpider(scrapy.Spider):
name = 'fengniaoClawer' # 爬虫名字,爬虫启动时需要指定的名字
allowed_domains = ['fengniao.com'] # 允许的域名,非这个域名下的url都会被抛弃掉
manualRetry = 8 # 手动重试的次数,有些网页即使状态码为200,也未必说明内容被拉下来, 拉下来的可能是残缺的一部分
# 爬虫自定义设置,会覆盖 settings.py 文件中的设置
custom_settings = {
'LOG_LEVEL': 'DEBUG', # 定义log等级
'DOWNLOAD_DELAY': 0, # 下载延时
'COOKIES_ENABLED': False, # enabled by default
'DEFAULT_REQUEST_HEADERS': {
# 'Host': 'www.fengniao.com',
'Referer': 'https://www.fengniao.com',
},
# 管道文件,优先级按照由小到大依次进入
'ITEM_PIPELINES': {
'fengniao.pipelines.ImagePipeline':100,
'fengniao.pipelines.FengniaoPipeline': 300,
},
# 关于下载图片部分
'IMAGES_STORE':'fengniaoPhoto', # 没有则新建
'IMAGES_EXPIRES':90, # 图片有效期,已经存在的图片在这个时间段内不会再下载
'IMAGES_MIN_HEIGHT': 100, # 图片最小尺寸(高度),低于这个高度的图片不会下载
'IMAGES_MIN_WIDTH': 100, # 图片最小尺寸(宽度),低于这个宽度的图片不会下载
# 下载中间件,优先级按照由小到大依次进入
'DOWNLOADER_MIDDLEWARES': {
'fengniao.middlewares.ProxiesMiddleware': 400,
'fengniao.middlewares.HeadersMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
'DEPTH_PRIORITY': 1, # BFS,是以starts_url为准,局部BFS,受CONCURRENT_REQUESTS影响
'SCHEDULER_DISK_QUEUE': 'scrapy.squeues.PickleFifoDiskQueue',
'SCHEDULER_MEMORY_QUEUE': 'scrapy.squeues.FifoMemoryQueue',
'REDIRECT_PRIORITY_ADJUST': 2, # Default: +2
'RETRY_PRIORITY_ADJUST': -1, # Default: -1
'RETRY_TIMES': 8, # 重试次数
# Default: 2, can also be specified per-request using max_retry_times attribute of Request.meta
'DOWNLOAD_TIMEOUT': 30,
# This timeout can be set per spider using download_timeout spider attribute and per-request using download_timeout Request.meta key
# 'DUPEFILTER_CLASS': "scrapy_redis.dupefilter.RFPDupeFilter",
# 'SCHEDULER': "scrapy_redis.scheduler.Scheduler",
# 'SCHEDULER_PERSIST': False, # Don't cleanup redis queues, allows to pause/resume crawls.
# 并发度相关。根据网站情况,网速以及代理来设置
'CONCURRENT_REQUESTS': 110, # default 16,Scrapy downloader 并发请求(concurrent requests)的最大值,即一次读入并请求的url数量
# 'CONCURRENT_REQUESTS_PER_DOMAIN':15, #default 8 ,对单个网站进行并发请求的最大值。
'CONCURRENT_REQUESTS_PER_IP': 5, # default 0,如果非0,则忽略CONCURRENT_REQUESTS_PER_DOMAIN 设定, 也就是说并发限制将针对IP,而不是网站
'REACTOR_THREADPOOL_MAXSIZE': 20, # default 10
# 限制爬取深度, 相对于start_url的深度
# 注意,这个深度一定要大于 retry的深度,要不然的话,一旦重试次数达到极致,也就达到了最大深度,爬虫会丢弃这个Request
'DEPTH_LIMIT': 10,
}
# 爬虫发起的第一个请求
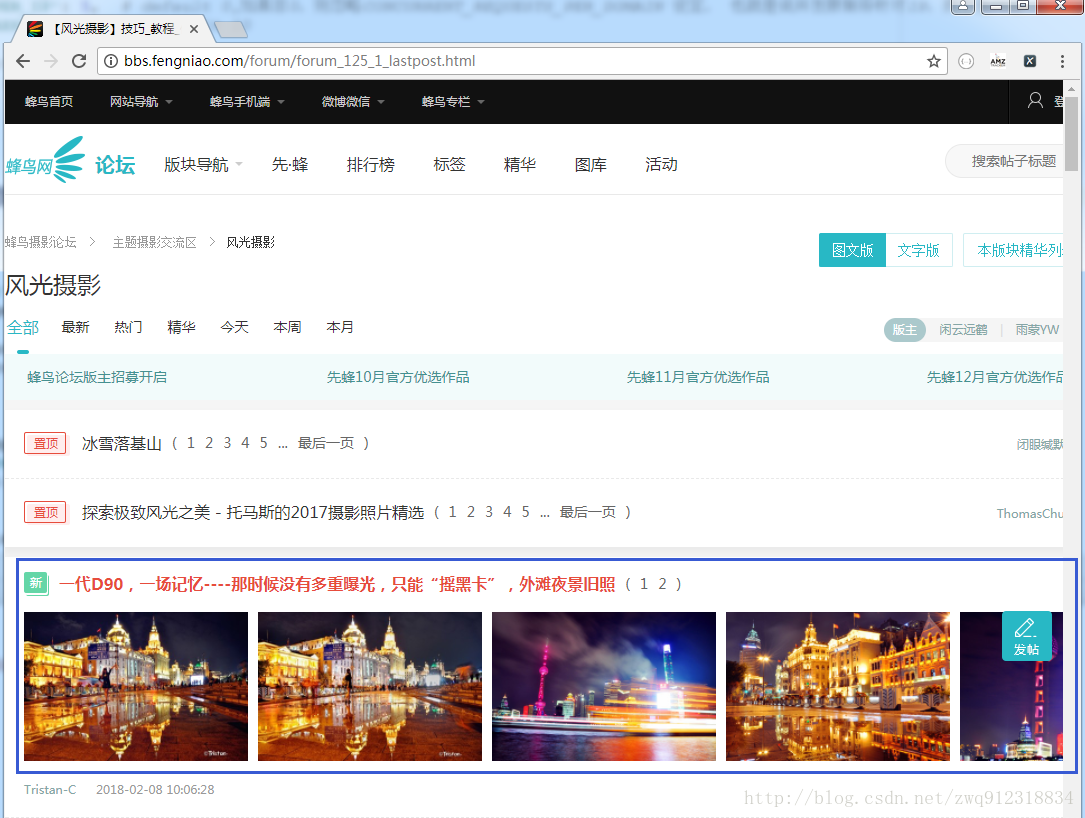
def start_requests(self):
startUrl = 'http://bbs.fengniao.com/forum/forum_125_1_lastpost.html'
pageNum = 0
yield scrapy.Request(
url = startUrl,
meta = {
'dont_redirect': True,
'pageNum': pageNum
},
callback = self.parseArticle, # 指定处理Response的函数
errback = self.error
)
# 跟进处理Response
def parseArticle(self, response):
self.logger.info(f"parseArticle: url = {response.url}, status = {response.status}, meta = {response.meta}")
# print(f"parseArticle: text = {response.text}")
# 拿到所有的文章
articleLst = response.xpath("//ul[@class='txtList']/li")
isGetPage = True if articleLst else False
# 保证完整的网页(至少预期的那部分内容)都被爬取下来了
if isGetPage == True:
# 逐条提取数据
for article in articleLst:
# 根据Items中的定义,来初始化数据
articleItem = FengniaoItem()
articleItem['itemType'] = 'articleInfo'
# 提取文章标题
articleItem['title'] = article.xpath("./h3/a/text()").extract()
# 提取文章链接
articleItem['href'] = article.xpath("./h3/a/@href").extract()
# 提取第一个展示图片的链接
articleItem['picLst'] = article.xpath("./div[@class='picList']//a//@style").extract()
# 提取到数据,转入pipelines.py进行处理
self.logger.info(f"parseArticle: articleItem = {articleItem}")
yield articleItem
# 继续爬取其他链接
# 可以是任何链接,无论是从网页中提取,还是自己构造
for pageNum in range(2, 10):
# 构造这种链接:http://bbs.fengniao.com/forum/forum_125_1_lastpost.html
nextUrl = "http://bbs.fengniao.com/forum/forum_125_" + str(pageNum) + "_lastpost.html"
# 继续爬取网页,构造Request送往调度器
yield scrapy.Request(
url = nextUrl,
meta = {'dont_redirect': True, 'pageNum': pageNum},
callback = self.parseArticle,
errback = self.error,
)
# 有时候,拉下来的网页可能是残缺的,但是状态码是200,scrapy会认为是成功的,这种需要手动重试
elif response.meta['depth'] < self.manualRetry:
request = response.request
request.dont_filter = True
yield request
else:
yield {'url': response.url, 'itemType': 'getPageLost'} # 日志用
# 处理Error信息
def error(self, failure):
if failure.check(HttpError):
response = failure.value.response
if response.meta['depth'] < self.manualRetry:
failure.request.dont_filter = True
yield failure.request
else:
yield {
'url': response.url,
'itemType': 'error',
'errorType': 'HttpError',
'depth': response.meta['depth'],
'priority': response.request.priority,
'status': response.status,
'callback': response.request.callback.__name__
} # 日志用
elif failure.check(TimeoutError, TCPTimedOutError, ConnectionRefusedError, DNSLookupError):
request = failure.request
yield {
'url': request.url,
'itemType': 'error',
'errorType': 'TimeoutError',
'priority': request.priority,
'callback': request.callback.__name__
} # 日志用,只在最后一次超时后才执行
else:
request = failure.request
yield {
'url': request.url,
'itemType': 'error',
'errorType': 'UnknownError',
'priority': request.priority,
'callback': request.callback.__name__
} # 日志用
# 爬取结束时的收尾工作,一般可以是发送邮件
def closed(self, reason):
self.logger.info(f"closed: spider finished, reason = {reason}")
# 文件:items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
# 定义格式化数据
# 其实也可以不定义,因为最终送往mongodb的数据是字典格式就行
# 定义的目的应该是有两方面:
# 1. 方便开发人员清晰的知道要解析哪些字段,避免遗漏
# 2. 避免填充其他的字段,造成数据混乱,因为如果不是这个里面定义的字段,是无法赋值的
class FengniaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
_id = scrapy.Field() # _id 即使是mongodb默认添加,也需要在这里定义
itemType = scrapy.Field()
title = scrapy.Field()
href = scrapy.Field()
picLst = scrapy.Field()
imagePathLst = scrapy.Field()
# 文件:dictionary.py
# 浏览器头信息
useragent = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) ',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE) ',
'Mozilla/2.02E (Win95; U)',
'Mozilla/3.01Gold (Win95; I)',
'Mozilla/4.8 [en] (Windows NT 5.1; U)',
'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)',
'Opera/7.50 (Windows XP; U)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.2; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/6.0)',
'Mozilla/5.0 (compatible; MSIE 10.6; Windows NT 6.1; Trident/5.0; InfoPath.2; SLCC1; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET CLR 2.0.50727) 3gpp-gba UNTRUSTED/1.0',
'Opera/9.25 (Windows NT 6.0; U; en)',
'Opera/9.80 (Windows NT 5.2; U; en) Presto/2.2.15 Version/10.10',
'Opera/9.80 (Windows NT 5.1; U; ru) Presto/2.7.39 Version/11.00',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.7.62 Version/11.01',
]
# 文件:middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
import random
from fengniao.dictionary import useragent
# 添加user-agent信息,模拟浏览器
class HeadersMiddleware:
def process_request(self, request, spider):
# print('Using HeadersMiddleware!')
request.headers['User-Agent'] = random.choice(useragent)
# 添加代理,突破反爬机制
class ProxiesMiddleware:
def process_request(self, request, spider):
# print('Using ProxiesMiddleware!')
if not request.meta.get('proxyFlag'):
# 阿布云代理
request.meta['proxy']='http://FHK87H210JK29JHH:D8HJJ82HP01G13FF@proxy.abuyun.com:9020'
class FengniaoSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
# 文件:pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import re
# 用于将结构化数据,存储进mongodb
class FengniaoPipeline(object):
def __init__(self, mongoUrl, mongoDB):
self.mongo_url = mongoUrl
self.mongo_db = mongoDB
# 从settings中拿到配置信息,这个方法是内置的
@classmethod
def from_crawler(cls, crawler):
return cls(
mongoUrl = crawler.settings.get("MONGO_URI"),
mongoDB = crawler.settings.get("MONGO_DB")
)
# 在爬虫开始时会调用
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
self.db_table = self.db['fengniaoArticle']
# 处理item,只要有item进来就会被调用
def process_item(self, item, spider):
# spider对象自带logger对象
spider.logger.info(f"FengniaoPipeline: item = {item}")
if ("itemType" in item) and (item["itemType"] == "articleInfo"):
try:
insertRes = self.db_table.insert_one(item)
spider.logger.info(f"FengniaoPipeline: insertRes = {insertRes.inserted_id}")
except Exception as e:
spider.logger.info(f"FengniaoPipeline: insertRes(fengniaoArticle) Exception = {e}")
else:
raise DropItem("fengniaoArticle record inserted!")
# 在爬虫结束时会调用
def close_spider(self, spider):
self.client.close()
class ImagePipeline(ImagesPipeline):
# 下载图片
def get_media_requests(self, item, info):
# when they have finished downloading, the results will be sent to the item_completed() method
if 'picLst' in item:
item["imagePathLst"] = [] # 初始化字段,用于存储图片名字
for pic in item['picLst']:
# background-image:url(https://bbs.qn.img-space.com/201802/5/954dda931c45118eec0ed19d8293be83.jpg?imageView2/2/w/400/q/90/ignore-error/1/)
picUrlRe = re.search('background-image:url\((.*?)\?imageView', pic)
if picUrlRe:
# 拿到图片链接
# https://bbs.qn.img-space.com/201802/4/d094e1a73f2334780e36dea8e83256a5.jpg
picUrl = picUrlRe.group(1)
print(f"picUrl = {picUrl}")
# 拿到图片名字
picNameRe = re.search(".*/(.*?)$", picUrl)
if picNameRe:
# d094e1a73f2334780e36dea8e83256a5.jpg
picName = picNameRe.group(1)
print(f"picName = {picName}")
# 进行图片下载
yield scrapy.Request(
url = picUrl,
meta = {'picName': picName}
)
break # 只下载一张图片
# 保存图片
def file_path(self, request, response=None, info=None):
image_guid = request.meta['picName']
# 指定图片名字
return f'{image_guid}'
# 反馈结果
def item_completed(self, results, item, info):
# results = [(True, {'url': 'https://bbs.qn.img-space.com/201802/5/c9ab39ff6d05d8e9dc990cf190c70461.jpg', 'path': 'c9ab39ff6d05d8e9dc990cf190c70461.jpg', 'checksum': '669a6a44cd462192729ebee54c35fe31'})]
print(f"results = {results}")
if results and results[0][0]:
imagePath = results[0][1]['path']
item["imagePathLst"].append(imagePath)
return item
# 文件:settings.py
# -*- coding: utf-8 -*-
import datetime
# Scrapy settings for fengniao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'fengniao'
SPIDER_MODULES = ['fengniao.spiders']
NEWSPIDER_MODULE = 'fengniao.spiders'
# 指定mongodb数据库
MONGO_URI = "localhost:27017"
MONGO_DB = 'fengniao'
# 指定Log文件
Date = datetime.datetime.now().strftime('%Y%m%d')
#LOG_FILE = f"fengniaoLog{Date}.txt"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'fengniao (+http://www.yourdomain.com)'
# Obey robots.txt rules ———— 如果遵守这个约定的话,那大部分网站都爬不动
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'fengniao.middlewares.FengniaoSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'fengniao.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'fengniao.pipelines.FengniaoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 文件:main.py
from scrapy import cmdline
# 续爬参数
# cmdline.execute('scrapy crawl fengniaoClawer -s JOBDIR=crawls/storefengniaoClawer'.split())
cmdline.execute('scrapy crawl fengniaoClawer'.split())
# detail+error-callback=parse=galance=7w
# 文件:scrapy.cfg
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.org/en/latest/deploy.html
[settings]
default = fengniao.settings
[deploy]
#url = http://localhost:6800/
project = fengniao
3.4. 运行结果
数据库

图片下载