2021年华中杯数学建模
A题 马赛克瓷砖选色问题
原题再现:
马赛克瓷砖是一种尺寸较小(常见规格为边长不超过 5cm)的正方形瓷砖,便于在非平整的表面铺设,并且容易拼接组合出各种文字或图案。但是受工艺和成本的限制,瓷砖的颜色只能是有限的几种。用户在拼接图案时,首先要根据原图中的颜色,选出颜色相近的瓷砖,才能进行拼接。
某马赛克瓷砖生产厂只能生产 22 种颜色(见附件 1)的马赛克瓷砖。该厂要开发一个软件,能够根据原始图片的颜色,自动找出颜色最接近的瓷砖,以减少客户人工选色的工作量。该厂希望你们团队提供确定原始颜色与瓷砖颜色对应关系的算法。假设原始图像为24 位真彩色格式,即 R、G、B 三个颜色分量均为 8 位,共有(2^8)的3次方=16777216种颜色,对于任何一种指定的颜色,算法输出颜色最相近的瓷砖的颜色编号。
请完成以下任务。
1)附件 2 是图像 1 中的 216 种颜色,附件 3 是图像 2 中的 200 种颜色,请找出与每种颜色最接近的瓷砖颜色,将选出的瓷砖颜色的编号按照附件 4 的要求输出至结果文件。
2)如果该厂技术革新,计划研发新颜色的瓷砖。那么,不考虑研发难度,只考虑到拼接图像的表现力,应该优先增加哪些颜色的瓷砖?当同时增加 1 种颜色、同时增加 2 种颜色、……、同时增加 10 种颜色时,分别给出对应颜色的 RGB 编码值。
3)如果研发一种新颜色瓷砖的成本是相同的,与颜色本身无关,那么,综合考虑成本和表现效果,你们建议新增哪几种颜色,说明理由并给出对应的 RGB 编码值。
附 数据说明
附件 1:现有瓷砖颜色

附件 2:图像 1 颜色列表
附件 3:图像 2 颜色列表
附件 4:选色结果文件格式
1. 附件 2 的选色结果保存在 result1.txt 中。附件 3 的选色结果保存在 result2.txt 中。
2. 只写瓷砖颜色编号(附件 1 中“编号”列),不要写 RGB 值。
整体求解过程概述(摘要)
近年来,随着大众审美观念的改变、品位格调的提高,无论是在公共场合还是私密空间的装修设计中,马赛克瓷砖拼接图像的设计与广泛应用已经成为了一种时尚潮流与装修设计市场中的发展趋势。而随着马赛克瓷砖热度的与日俱增,对瓷砖生产厂家也提出了更高的产业要求——如何快速高效地为设计图像匹配颜色相近的瓷砖;在研发新颜色时,如何设计生产策略,使得投入生产后能够做到低成本,高回报等等问题。本文为帮助瓷砖生产厂家解决上述问题,建立了“颜色匹配模型”与“‘新颜色研发’问题的优化模型”,研究了瓷砖的选色问题,并提供了新的颜色研发方案。
针对问题一,我们首先引入了色差这一概念来表示不同颜色之间的相似度,并且将颜色对象坐标化,利用欧式距离公式,求得两点之间的距离值,并将此值赋予色差,通过计算得到色差值的大小来表示不同颜色之间的相似程度。并且,我们首先选择了 RGB 空间、HSV 空间和 Lab 空间三种颜色空间,对三种不同颜色空间的特性进行了阐释,并且三种空间中均建立了各自的颜色匹配模型。之后,我们对三种空间以及各自所建立的模型进行评估比较,最终选定使用 Lab 空间模型以及根据该模型建立的颜色匹配模型,并在求解过程中进行简化运算,最终求得与附件 2、3 中 216 种颜色和 200 种颜色最接近的颜色,以及 RGB 编码值。
针对问题二,由于只考虑表现力效果,我们首先对附件 2、3 中的 216 种颜色与 200 种颜色和已有的 22 种进行了统计与可视化处理,得出它们的颜色空间分布图,以此为基础选定需求侧与供给侧的分析入手角度,确定了表现力评估标准——“在添加颜色后,新的颜色集在空间中的分布更加均匀”。根据上述条件,建立起以新增颜色的种类和数量为决策变量,图像表现力为目标函数的单一目标优化模型。之后再根据迭代思想,利用贪心算法,求得不同新增颜色目标个数所对应的最优解。
针对问题三,在本题中,除却考虑拼接图像的表现外,研发成本也成为了在优化问题中的一个重要考虑对象。针对表现力问题,我们考虑了新聚类中心在空间中的分布,并且利用了 FCM 思想,给定了表现力函数;而成本问题,由于研发任意一中新颜色的成本相同,且与颜色本身无关,因此我们把研发成本与颜色数量认定为线性关系,并建立其成本函数。据以上所述,我们建立起以增加数目为变化的决策变量,以表现力函数和成本函数共同为目标函数的多目标优化模型,并利用了非支配排序算法与模拟退火算法,对模型进行求解。
关键词:颜色空间;色差;单目标优化;均匀分布;贪心算法;多目标优化;非支配排序算法;模拟退火算法
问题分析:
问题一:根据已给出的三组 RGB 颜色编码建立数学模型,来反应不同颜色之间的相似度。目前,有关不同颜色之间差别主要通过色差这一概念来表示,但是由于颜色空间的多样性以及其各自存在的局限性,在不同空间下,不同方式所得出的色差能够反应颜色差别的程度截然不同。因此本题难点在于需要建立匹配模型,模型不仅能直观准确地反映出不同颜色的相似度,同时模型本身的局限性对结果造成的影响较小。针对此问题,拟在 RGB 空间、HSV 空间、LAB 空间以及欧式空间距离的基础上建立数学模型。
问题二:在问题一中,给出了图像一、二各自包含的所有颜色,分别有 216 种与200 种,同时也能看到现有的瓷砖颜色只有 22 种,所以可以知道在装修设计中所需要的的颜色种类要比我们瓷砖的颜色种类多,所以需要开发新颜色,更便于寻找匹配颜色,增加图形表现力。本题中,我们只考虑拼接图像的表现力,所以从本质上讲,问题二是将拼接图像的表现力作为优化目标的优化问题。因此我们将瓷砖颜色作为决策变量,拼接图像的表现力作为优化目标,从需求侧与供给侧两方面入手选定合理评价标准,建立优化模型。并利用贪心算法,求出增加新颜色的目标个数不同时,根据评价标准所得到的最优解
问题三:本题将瓷砖的研发成本与拼接图像的表现力作为棕合考虑的对象,也就是本题与第二问相比,由一个单目标优化问题转变为了多目标寻优问题。因为每种新颜色瓷砖的研发成本是相同的,与颜色本身无关,那么可根据新增的瓷砖颜色数来对研发成本进行表示。再从需求侧与供给侧两方面入手选定合理的表现力评价标准,以新增颜色个数为决策变量,研发成本函数与表现力函数作为目标函数,建立多目标寻优模型。并对模型进行求解,得到最优解。
模型的建立与求解:
RGB 空间下的色差度量模型的建立与评估
RGB 颜色空间是以 R(Red:红)、G(Green:绿)、B(Blue:蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色,俗称三基色模式。从图像处理而言,RGB 是最为重要和常见的颜色模型,它建立在笛卡尔坐标系中,用一个单位长度的立方体来表示颜色黑蓝绿青红紫黄白 8 种常见颜色分别位居立方体的 8 个顶点,通常将黑色置于三维直角坐标系的原点,红绿蓝分别置于 3 根坐标轴土,整个立方体放在第 1 卦限内。如下图所示。
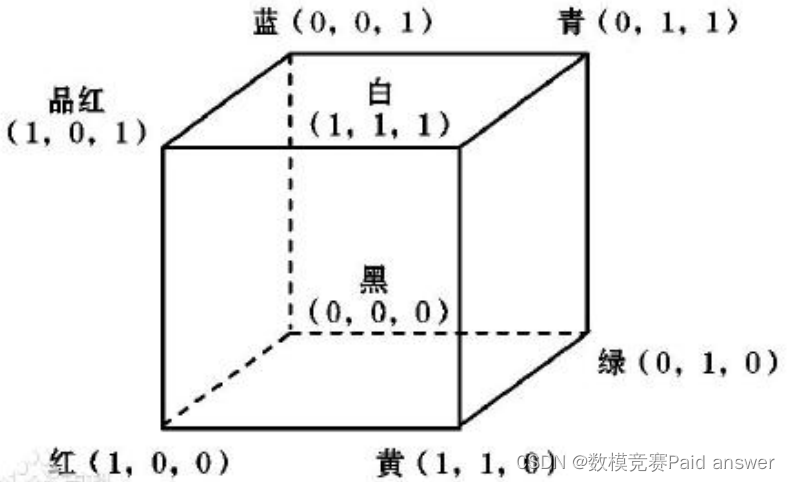

我们通过分析 (1) 式,可以显然得出,直接通过两点之间的空间距离来表示色差值的情况下,该种方法直接默认了 RGB 颜色空间为一个均匀颜色空间(均匀空间为 RGB 色差公式成立的前提条件),即每个颜色的等色差颜色,应在 RGB颜色空间中成一个球面;且不同位置的等色差颜色对应该表现出相同的差异。我们通过观察上图可知,RGB 颜色空间并不满足上述条件,也就是说用 RGB比较颜色之间的相似度时,往往一个基本颜色通道的一点改变,会导致最后融合在一起的颜色发生巨大变化,而如果三个通道的同时改变,却只会使最后的明暗发生变化,色调并不会产生巨大变化.,对最终结果造成较大的影响,算法存在较大的漏洞,我们不予选择。
要知道,我们对于颜色的判断以及辨别不同颜色之间的差别,是通过人眼视觉系统对对象特征的抓取,然后转化成为神经冲动经神经元将冲动传输至大脑,再在大脑中完成电传递到化学传递的转别,最后形成意识的过程。而对对象特征的抓取则是由于人眼对不同特征的反应程度不同,也就是说人眼对不同特征,不同表象具有不同的敏感度,对不同颜色更是如此。因此,可提出采取加权的方式来解决 RGB 颜色空间不够均匀的问题。而加权的思想则来源于根据人眼对红、绿、蓝三原色敏感程度的不同来定义权值,调整基础的 RGB 空间,部分补偿其非均匀性。

本题中我们的目标是通过新研发颜色的增加,使得最后的拼接图像的表现力要提高,也就是说关键在于向现有的瓷砖颜色体系中增加目标个新颜色后,使得可利用的瓷砖颜色整体的颜色分布最优化,而寻找合适的评价标准则成为了解决问题的基础。
要知道,在日常的工业生产中,需求侧与供给侧是进行生产问题优化时,考虑的两个重要角度。问题一中,给出了两个不同图像各自包含的颜色,可视为需求侧;并且已知现有瓷砖的颜色,可视为供给侧。我们从这两个角度考虑,建立了“新增颜色后,已知颜色尽量均匀分布整个空间”的标准,之后再利用贪心算法,求得不同新增颜色目标个数所对应的最优解。
在工业生产中,遇到生产策略的设计以及生产产品的种类、数量优化,以及产品价格、销售方式的选定时,我们通常将从两个角度来分析不同方案对最终决策的影响,这两个重要角度便是需求侧的利用量与供给侧的生产量。需求侧代表着当下的市场需求,市场风向与潮流趋势等,而供给侧则代表着生产厂家的生产能力、创新能力、以及宣发销售能力等。结合本题来说,需求侧的数据可以体现当下市场对于某种颜色的使用程度,消费者对于不同拼接图像风格的喜爱程度,以及行业中流行趋势;而供给侧的数据则可以体现目前所拥有的瓷砖颜色是否能够满足市场需求,是否符合行业潮流等问题。因此,在本题中,需求侧与供给侧的选定直接影响了优化模型的评价标准的选择合理性,进而间接影响了最终最优解的准确性。
问题一中,给出了两个不同图像各自包含的每种颜色,以及每种颜色所对应的 RGB 值,我们可以对图像一、二中各自包含的数据分别进行统计,通过统计数据来分析判断,哪种颜色在当下市场更受欢迎,哪一个 RGB 段的颜色出现需求高,是否可以生产在需求高的 RGB 段中的已有颜色的匹配色等问题;同时,我们也对现有 22 种颜色进行统计分析判断,观察 22 种已有颜色在颜色空间中的分布是否均匀,是否有哪一颜色段种出现缺失,是否某一已知颜色存在于不符合当下市场潮流趋势的颜色段中等问题;根据以上所述,我们最终选定,需求侧角度从“统计分析图像一、二的颜色数据,观察哪一段 RGB 段的颜色出现需求高”入手,而供给侧角度则确定为“统计分析已有 22 种颜色,观察颜色与空间中的分配现象”。

通过观察以上两图,我们可以发现,虽然在对两组数据,在二维上进行了统计与可视化处理,可我们仍无法通过直接对比观察,得出“哪一段 RGB 颜色段的需求更高”、“图像中的颜色分布是均匀分布还是无规律分布”等问题,同时由于个体间的文化差异、审美观念、个性品位的不同,也无法说明两个图像之间表现力的高低强弱。因此,我们认为上述建立的二维统计模型并不适合解决本题。在问题一中,我们所提到的三个空间模型,RGB 模型、HSV 模型与 Lab 模型全部是三维空间中的模型,那么我们可以利用三组已知数据,它们各自在 RGB空间中的三维统计模型,并对数据进行可视化处理,从而观察每组数据的空间颜色分布图。
根据以上思想,利用 R 语言,我们建立了图像一、二以及现有 22 种颜色的三维统计模型,如下图所示
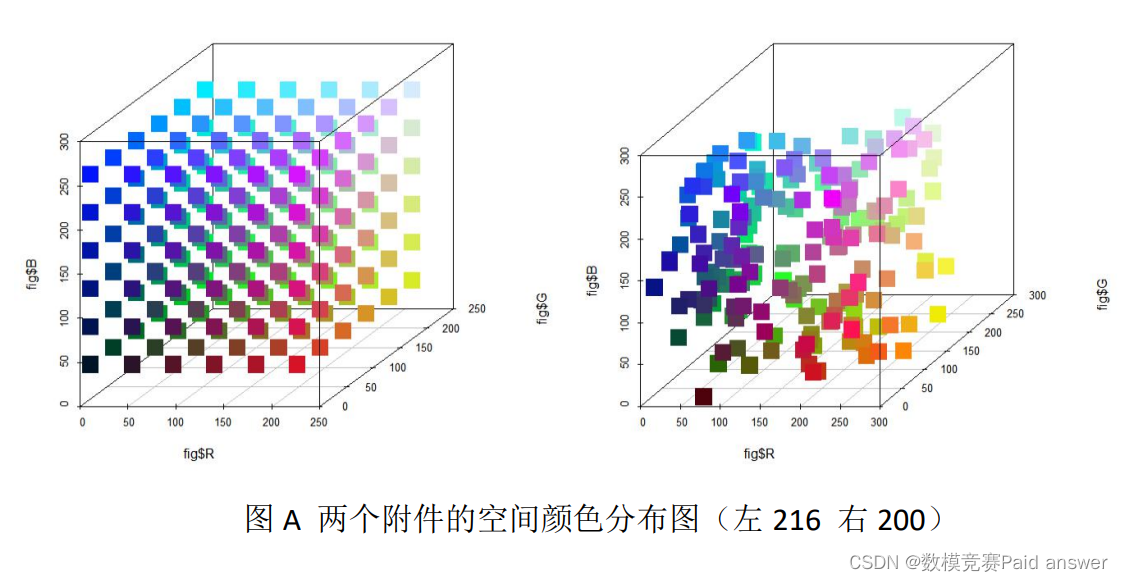
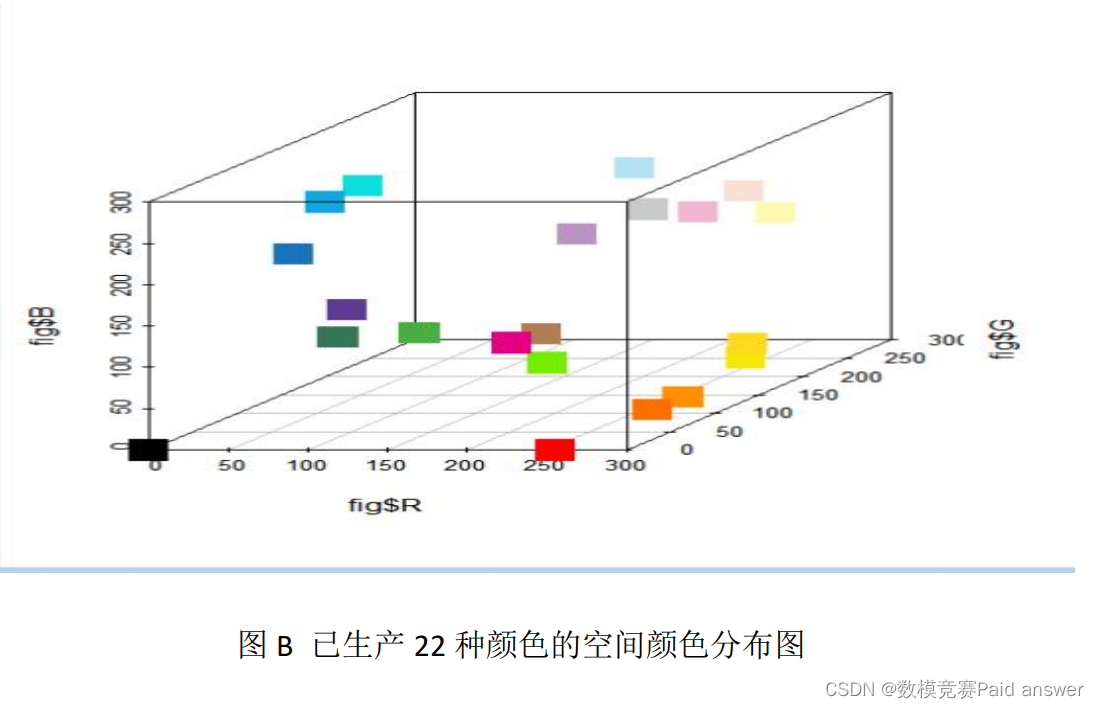
根据我们已经建立的模型,结合题目要求,可以将问题转化为“向原有的数据中添加新数据,使得形成的新数据集在进行可视化处 理之后,使得数据在数据空间中均匀分布,空间覆盖率最大。”那么,要想在原有的数据中添加数据,需要先统计研究原有数据的分布情况,根据统计得到的分布情况,分析得出数据分布特点,之后选择在某一分布区间或某几个分布区间中添加一个或几个数据,使得添加之后的数据分布更加均匀即可。
我们的目标是向 22 个已有数据中添加数据使得数据分布更均匀,那么我们便利用 R 语言,对 22 个 RGB 数据进行统计,绘制出 22 个 RGB 数据的统计条形图,如下图所示
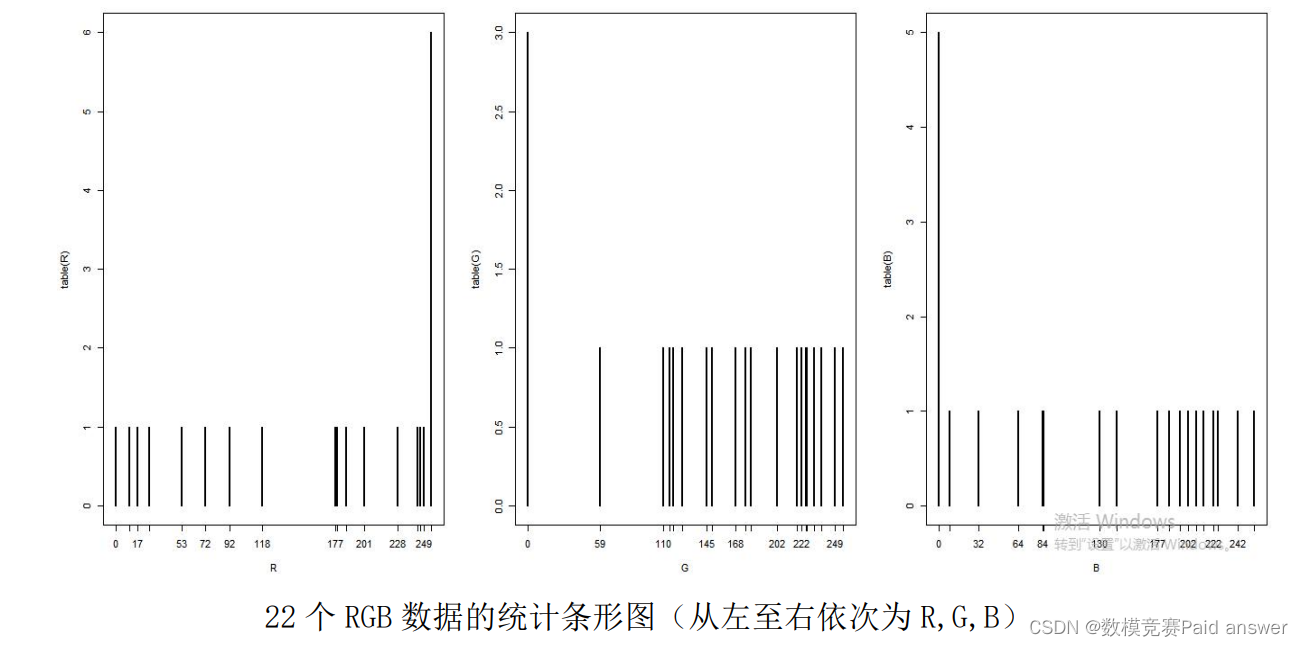
从上述条形统计图我们可以看出 R,G,B 并不是均匀分布在整个空间中的,那么当我们想要向原有数据中加入数据,使得新数据能够尽量均匀分布,那么优先便是填补 RGB 条形统计图中间隔最大的位置。而填补位置的确定,根据均匀分布的原则,我们选择填补的分布区间的中点作为填补位置,在该位置进行填补。本题的要求是分别输出从添加一种新颜色到添加十种新颜色的十种不同情况下应该优先添加颜色的 RGB 码,但是,我们考虑到如果将十种情况依次进行的话,除去第一次外,之后每一次都要重复前一次已经执行过的工作,并且重复执行的工作量会随次数的增多而越来越大,同时每一次的工作中都包含了大量的比较、筛选与清理工作,那么势必会消耗大量的时间,在数据空间庞大的情况下,工作效率会降低。
因此,我们选择了贪心算法来对问题进行求解。贪心算法的特点是一步一步地进行,常以的前情况为基础根据某个优化测度作最优选择,而不考虑各种可能的整体情况,它省去了为找最优解要穷尽所有可能而必须耗费的大量时间。它采用自顶向下,以迭代的办法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题,通过每一步贪心选择,可得到问题的一个最优解。
论文缩略图:

程序代码:
#HSV 的三维锥形图像代码
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
from math import sin, cos, pi
#进行
# r,g,b [0,255]
# h 0 - 360
# s 0 - 100
# v 0 - 100
def rgb2hsv(r, g, b):
r_, g_, b_ = r / 255, g / 255, b / 255
c_max = max(r_, g_, b_)
c_min = min(r_, g_, b_)
dela = c_max - c_min
if dela == 0:
h = 0
elif c_max == r_ and g_ >= b_:
h = 60 * ((g_ - b_) / dela + 0)
elif c_max == r_ and g_ < b_:
h = 60 * ((g_ - b_) / dela + 2)
elif c_max == g_:
h = 60 * ((b_ - r_) / dela + 2)
else:
h = 60 * ((r_ - g_) / dela + 4)
s = 0 if c_max == 0 else dela / c_max
v = c_max
return h, s * 100, v * 100
# h 0,255 s,v 0,1
def hsv2rgb(h, s, v):
c = v * s
x = c * (1 - abs((h / 60) % 2 - 1))
m = v - c
if 0 <= h < 60:
r_, g_, b_ = c, x, 0
elif 60 <= h <= 120:
r_, g_, b_ = x, c, 0
elif 120 <= h <= 180:
r_, g_, b_ = 0, c, x
elif 180 <= h <= 240:
r_, g_, b_ = 0, x, c
elif 240 <= h <= 300:
r_, g_, b_ = x, 0, c
elif 300 <= h <= 360:
r_, g_, b_ = c, 0, x
return (r_ + m) * 255, (g_ + m) * 255, (b_ + m) * 255
fig = plt.figure() # 定义新的三维坐标轴
ax = Axes3D(fig)
size = 30
points = np.linspace(0, 255, size).astype(np.int32)
for h in np.linspace(0, 360, size):
for s in np.linspace(0, 100, size):
for v in np.linspace(0, 100, size):
if v < s:
continue
x_ = s * cos(h * pi / 180)
y_ = s * sin(h * pi / 180)
# z_ = -(v ** 2 - s ** 2) ** 0.5
z_ = v
x, y, z = hsv2rgb(h, s / 100, v / 100)
ax.plot([x_], [y_], [z_], "ro", color=(x / 255, y / 255, z / 255, 1))
print('---')
ax.set_zlabel('r')
ax.set_ylabel('g')
ax.set_xlabel('b')
plt.show()
from ast import literal_eval
import math
#低成本近似的色差计算函数
def ColourDistance(rgb_1, rgb_2):
R_1, G_1, B_1 = rgb_1
R_2, G_2, B_2 = rgb_2
rmean = (R_1 + R_2) / 2
R = R_1 - R_2
G = G_1 - G_2
B = B_1 - B_2
return math.sqrt((2 + rmean / 256) * (R ** 2) + 4 * (G ** 2) + (2 + (255 - rmean)
/ 256) * (B ** 2))
#图像二的求解代码
x1=[]
y1=[]
with open('附件 3:图像 2 颜色列表.txt','r',encoding='utf-8') as text1:
next(text1)
for line in text1:
set=line.strip().split(',',1)
x1.append(float(set[0]))
y1.append(set[1])
res1=list(map(literal_eval,y1))
num1=len(res1)
rgb=[(0,0,0),(255,255,255),(255,0,0),(246,232,9),(72,176,64),(27,115,186),(53,118,84)
,(244,181,208),(255,145,0),(177,125,85),(92,59,144),(11,222,222),(228,0,130),(255,2
18,32),(118,238,0),(17,168,226),(255,110,0),(201,202,202),(255,249,177),(179,226,2
42),(249,225,214),(186,149,195)]
diff1=[]
for i in range(0,num1):
for j in range(0,22):
diff1=str(ColourDistance(res1[i], rgb[j]))
print(diff1)
#将输出结果输出为文件 result_2.txt
with open('result_2.txt','r',encoding='utf-8') as text_3:
difference1=text_3.read()
difference1_1=difference1.splitlines()
d1=[float(s) for s in difference1_1]
a1=[]
b1=[]
for k in range(0,200):
a1=min(d1[0+22*k],d1[1+22*k],d1[2+22*k],d1[3+22*k],d1[4+22*k],d1[5+22*k],d1
[6+22*k],d1[7+22*k],d1[8+22*k],d1[9+22*k],d1[10+22*k],d1[11+22*k],d1[12+22*
k],d1[13+22*k],d1[14+22*k],d1[15+22*k],d1[16+22*k],d1[17+22*k],d1[18+22*k],d
1[19+22*k],d1[20+22*k],d1[21+22*k])
c1=d1.index(a1)
c1=c1+1
print(c1)
#将输出结果输出为文件图像二.txt
with open('图像二.txt','r',encoding='utf-8') as text_4:
load1=text_4.read()
load1_1=load1.splitlines()
e1=[int(s) for s in load1_1]
e1_1=[n1 % 22 for n1 in e1]
#coding=utf-8
txtName_1 = "result2.txt"
f1=open(txtName_1,"a+",encoding="utf-8")
for i_i in range(0,201):
if i_i == 0:
new_context1 = "序号,瓷砖颜色编号" + '\n' f1.write(new_context1)
elif 0 < i_i < 217 :
new_context1 = str(i_i) + ',' + str(e1_1[i_i-1]) + '\n' f1.write(new_context1)
else:
new_context1 ='\n' f1.write(new_context1)
f1.close()
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可