概念

根据你的“邻居”判断你的类别
流程

KNN api 初步使用
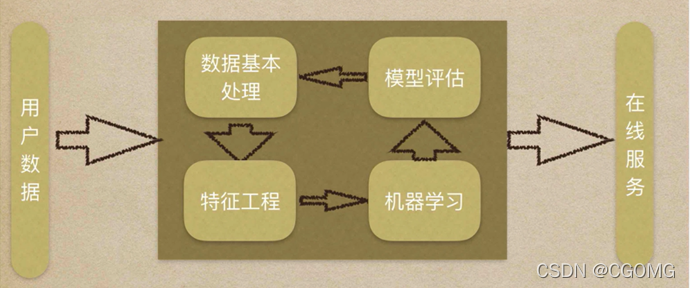
机器学习流程
Scikit-learn工具

安装
pip3 install scikit-learn==0.19.1
注:需要Numpy,Scipy等库的支持
Python (>= 3.5),
NumPy (>= 1.11.0),
SciPy (>= 0.17.0),
joblib (>= 0.11).
检验安装
import sklearn
Scikit-learn包含内容

K-近邻算法API
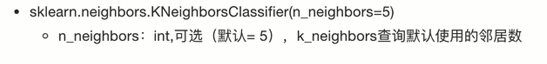
测试
from sklearn.neighbors import KNeighborsClassifier
# 构造数据
x = [[1], [5], [10], [20]]
y = [2, 2, 6, 6]
# 训练模型
# 实例化估计器对象
estimator = KNeighborsClassifier(n_neighbors=1)
# 调用fit方法 进行训练
estimator.fit(x, y)
# 数据预测
ret = estimator.predict([[2]])
print(ret)
ret = estimator.predict([[30]])
print(ret)

K值的选择



k近邻搜索算法

KD树
why

what

how
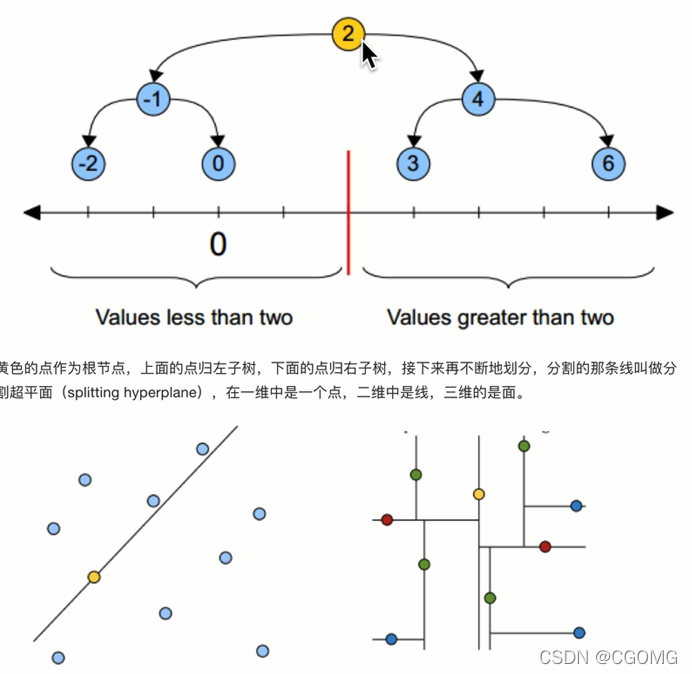
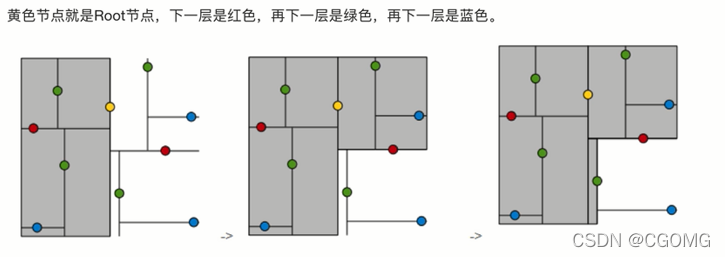
树的建立
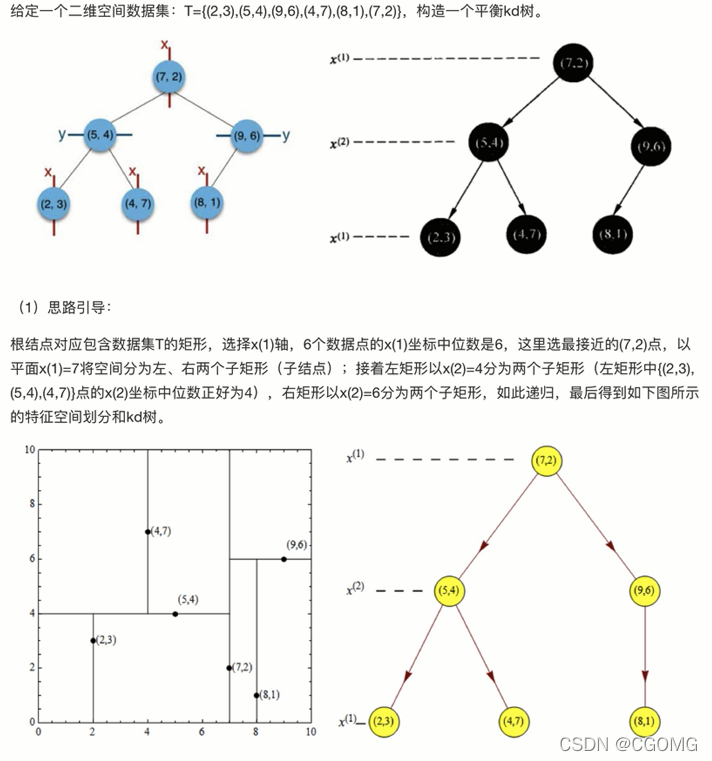
- 多个维度,选择最分散的一个维度排序、取中位数进行第一次划分(这里选择x轴)
- 根据第一次选择的维度的中位数进行左右划分(2、4、5 | 8、9),将对应的另一维度数值进行排序、取中位数划分
- 重复上两步,直到无法划分

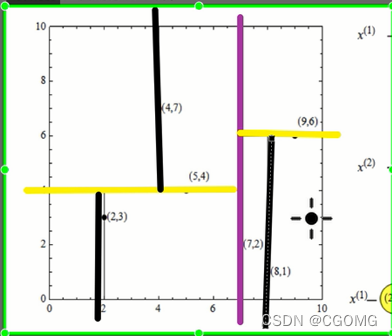
最近领域搜索

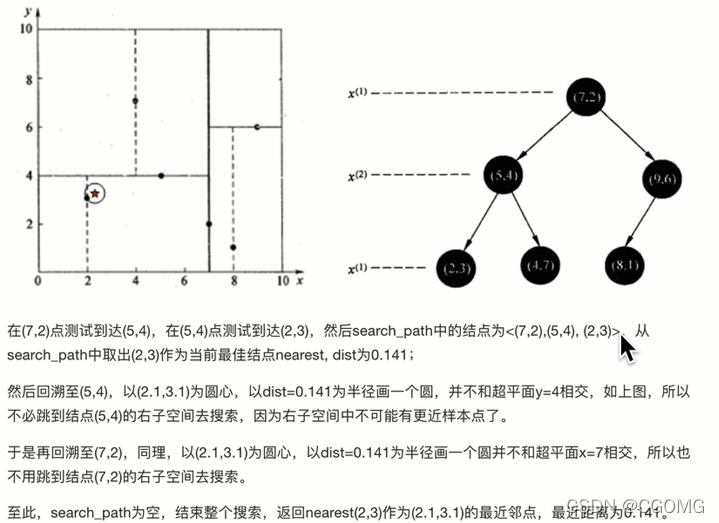
例:查(2.1,3.1)
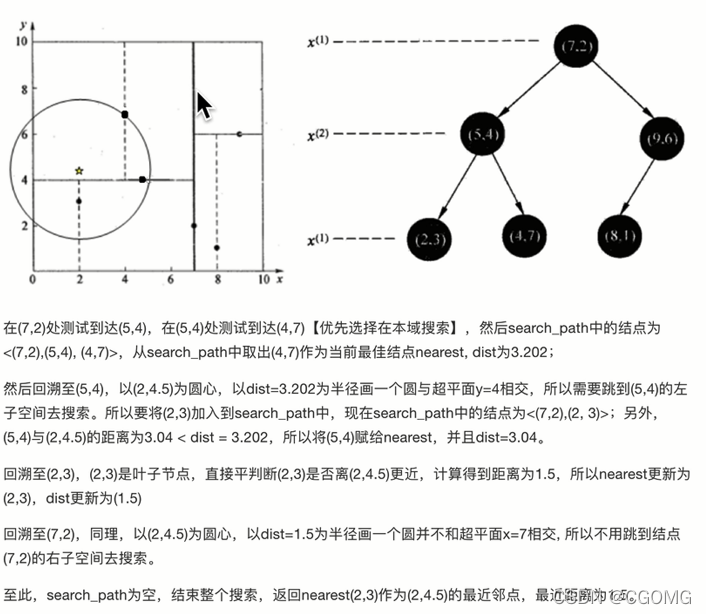
例:查(2,4.5)
KD树总结

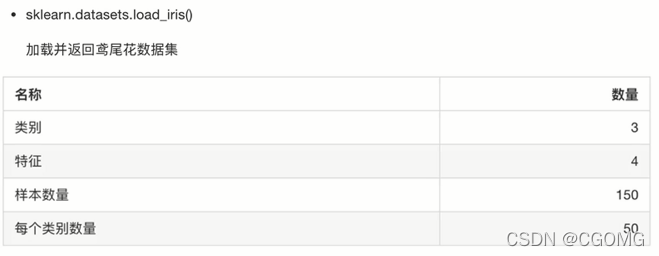
scikit-learn 数据集

sklearn小数据集
sklearn大数据集

sklearn 数据集返回值介绍

from sklearn.datasets import load_iris,fetch_20newsgroups
# 小数据集获取
iris = load_iris()
# print(iris)
# 大数据集获取
# news = fetch_20newsgroups()
# print(news)
# 数据集属性描述
print("数据集特征值是:\n", iris.data)
print("数据集目标值是:\n", iris["target"])
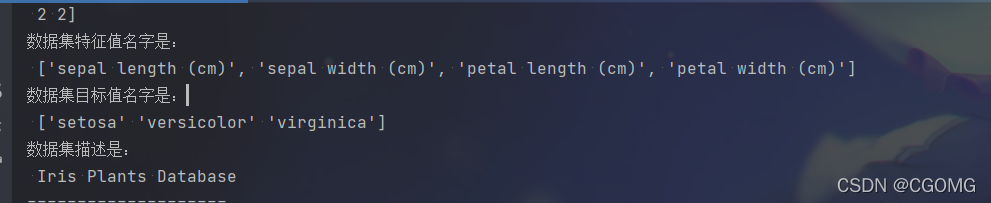
print("数据集特征值名字是:\n", iris.feature_names)
print("数据集目标值名字是:\n", iris.target_names)
print("数据集描述是:\n", iris.DESCR)
数据可视化

from sklearn.datasets import load_iris, fetch_20newsgroups
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from pylab import mpl
# 设置显示中文字体
mpl.rcParams['font.sans-serif'] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams['axes.unicode_minus'] = False
# 小数据集获取
iris = load_iris()
# 数据可视化
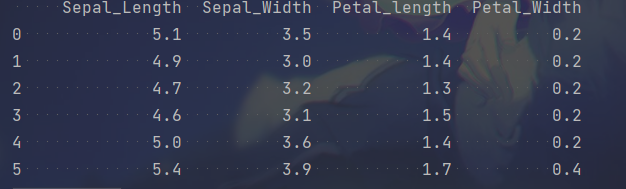
iris_d = pd.DataFrame(data=iris.data, columns=["Sepal_Length", "Sepal_Width", "Petal_length", "Petal_Width"])
print(iris_d)
iris_d["target"] = iris.target
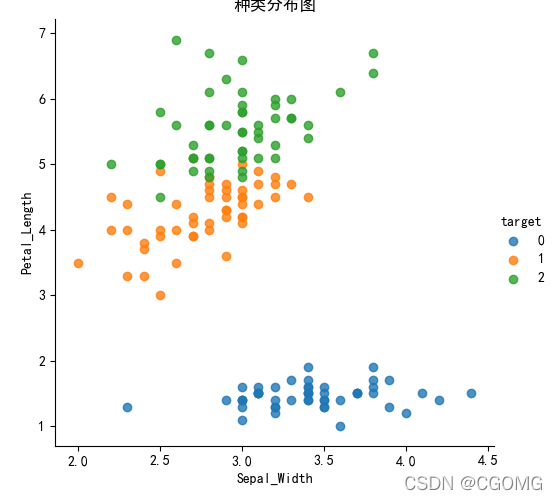
def iris_plot(data, col1, col2):
sns.lmplot(x=col1, y=col2, data=data,hue="target",fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title("种类分布图")
plt.show()
iris_plot(iris_d, "Sepal_Width", "Petal_Length")
数据集划分

from sklearn.datasets import load_iris, fetch_20newsgroups
from sklearn.model_selection import train_test_split
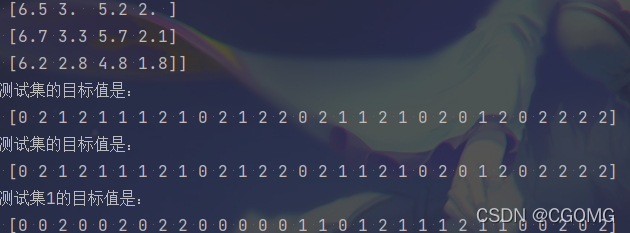
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22, test_size=0.2)
print("训练集的特征值是:\n", x_train)
print("训练集的目标值是:\n", y_train)
print("测试集的特征值是:\n", x_test)
print("测试集的目标值是:\n", y_test)
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=2, test_size=0.2)
print("测试集的目标值是:\n", y_test)
print("测试集1的目标值是:\n", y_test1)
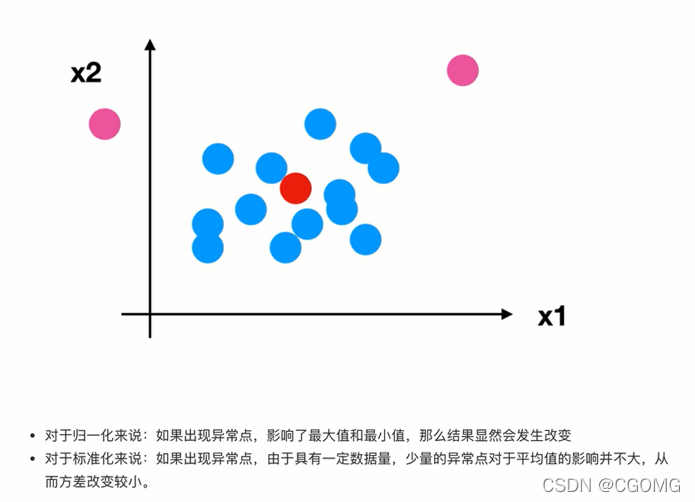
特征预处理
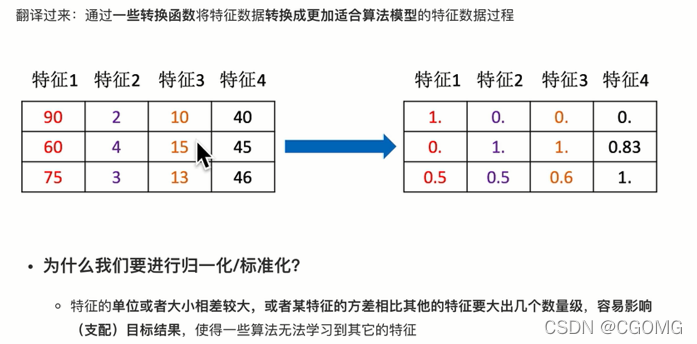
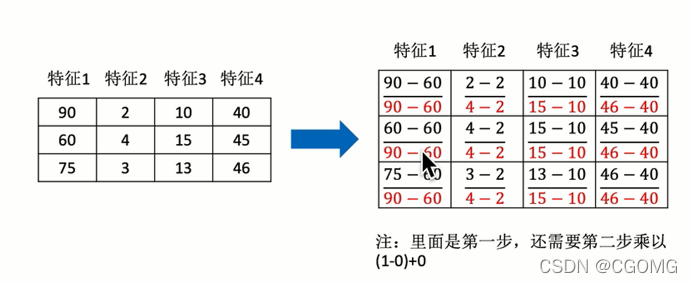
归一化

公式

api

标准化

公式
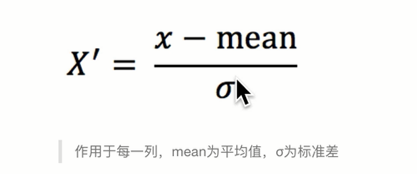
api

预处理总结

案例:鸢尾花种类预测
数据集介绍

# @Author : CG
# @File : 03-鸢尾花种类预测.py
# @Time : 2022/2/8 17:19
# @contact: gchencode@126.com
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理 不同的random_state将导致训练集和测试集的不同,进而导致最终准确率不同
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# 3.特征工程
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#fit(): 用来计算mean(均值)和std(标准差),以便后面进行数据的标准化
#transform(): 根据fit()函数计算的mean和std对数据进行标准化
#fit_transform(): 是fit()函数和transform()函数的组合,先进行fit,之后再进行transform(标准化)
# fit_transform方法是fit和transform的结合,
# fit_transform(X_train) 意思是找出X_train的平均值和标准差,并应用在X_train上。
# 这时对于X_test,我们就可以直接使用transform方法。
# 因为此时StandardScaler已经保存了X_train的平均值和标准差。
#因为我们必须保证,测试集在进行标准化的时候,使用的是统一的缩放参数,即为均值和标准差。所以先使用fit_transform()在训练集上,再使用transform()在测试集上。
# 4.机器学习(模型训练)knn
# 实例化估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 预测值结果输出
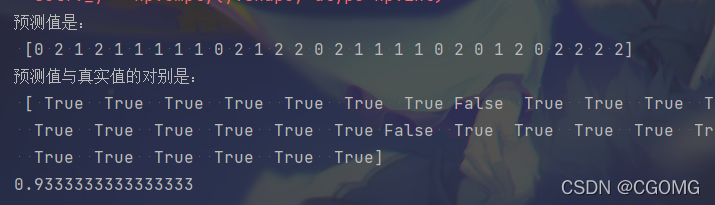
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值与真实值的对别是:\n", y_pre == y_test)
# 准确率计算
score = estimator.score(x_test, y_test)
print(score)
KNN算法总结
优点

缺点

交叉验证,网格搜索
什么是交叉验证



什么是网格搜索
交叉验证,网格搜索(模型选择与调优)API

# @Author : CG
# @File : 03-鸢尾花种类预测.py
# @Time : 2022/2/8 17:19
# @contact: gchencode@126.com
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# 3.特征工程
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#fit(): 用来计算mean(均值)和std(标准差),以便后面进行数据的标准化
#transform(): 根据fit()函数计算的mean和std对数据进行标准化
#fit_transform(): 是fit()函数和transform()函数的组合,先进行fit,之后再进行transform(标准化)
# fit_transform方法是fit和transform的结合,
# fit_transform(X_train) 意思是找出X_train的平均值和标准差,并应用在X_train上。
# 这时对于X_test,我们就可以直接使用transform方法。
# 因为此时StandardScaler已经保存了X_train的平均值和标准差。
#因为我们必须保证,测试集在进行标准化的时候,使用的是统一的缩放参数,即为均值和标准差。所以先使用fit_transform()在训练集上,再使用transform()在测试集上。
# 4.机器学习(模型训练)knn
# 实例化估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 模型调优 - 交叉验证,网格搜索
param_grid = {"n_neighbors": [1, 3, 5, 7]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 预测值结果输出
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值与真实值的对别是:\n", y_pre == y_test)
# 准确率计算
score = estimator.score(x_test, y_test)
print(score)
# 交叉验证、网格搜索结果
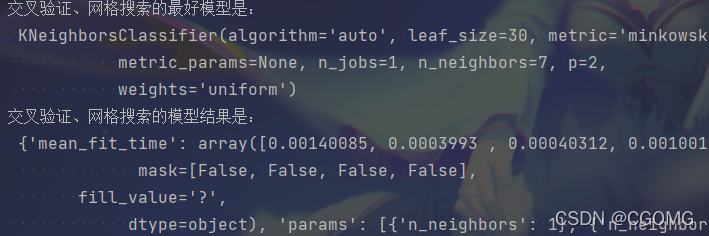
print("交叉验证、网格搜索的最好结果是:\n", estimator.best_score_)
print("交叉验证、网格搜索的最好模型是:\n", estimator.best_estimator_)
print("交叉验证、网格搜索的模型结果是:\n", estimator.cv_results_)
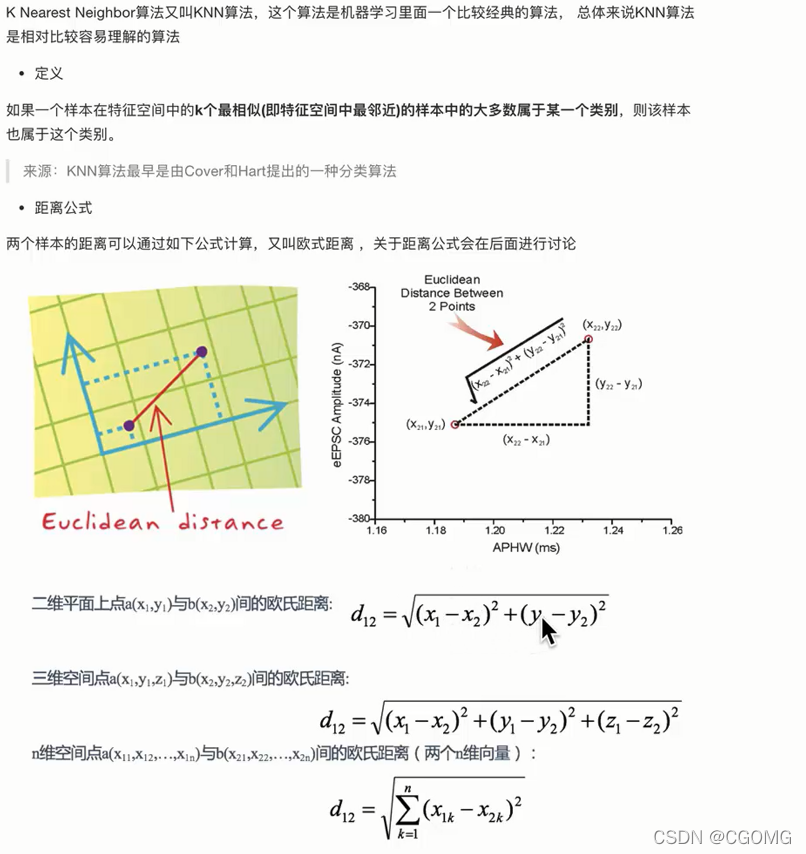
常见距离公式
欧式距离

曼哈顿距离

切比雪夫距离

闵可夫斯基距离

常见距离小结

其他距离公式
标准化欧式距离

余弦距离

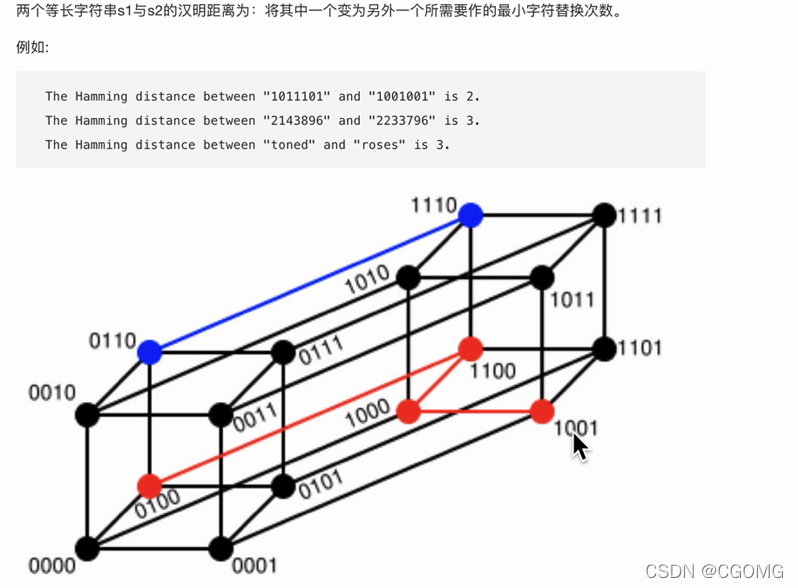
汉明距离

杰卡德距离

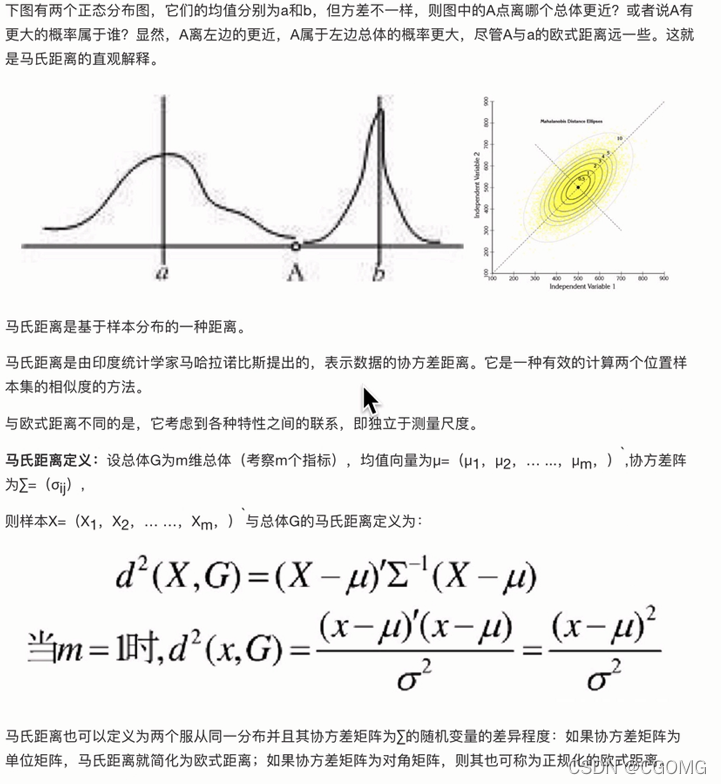
马氏距离