不足之处请大家多多指点!
文章目录
链接
论文题目:用图卷积网络进行自监督分类(GCN)(2017ICLR)
论文链接:1609.02907v3.pdf (arxiv.org)
代码链接:tkipf/pygcn: Graph Convolutional Networks in PyTorch (github.com)
代码讲解(非本人):4.1_GCN代码_哔哩哔哩_bilibili
注意:这里给的代码链接是用PyTorch实现的,原始论文中的代码是用Tensorflow实现的,有兴趣的可以自己玩:tkipf/gcn: Implementation of Graph Convolutional Networks in TensorFlow (github.com)
代码详解
1.数据集介绍
Cora数据集主要由机器学习论文组成,共分为七类:
Case_Based
Genetic_Algorithms
Neural_Networks
Probabilistic_Methods
Reinforcement_Learning
Rule_Learning
Theory
其中每篇论文至少引用或被另一篇论文引用一次,共2708篇论文
删去通用词后,得到一个大小为1433的唯一词的词汇表。所有文档中频率小于10的单词都被删除
cora.content:
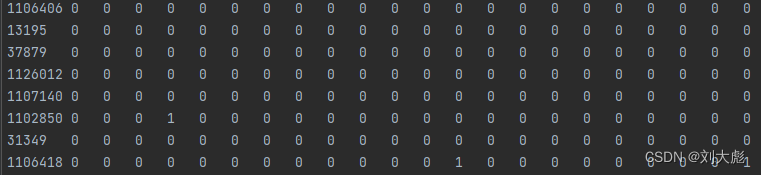
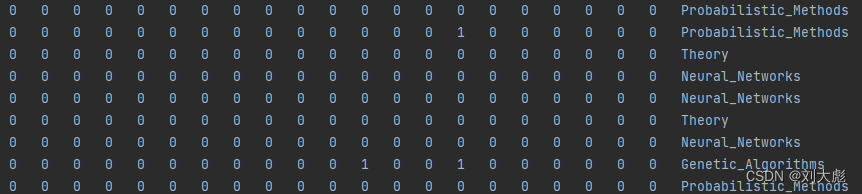
第一列为论文的唯一字符串ID
后面列为对应词汇表的0/1值
最后一列为论文所属类别标签
cora.cites:
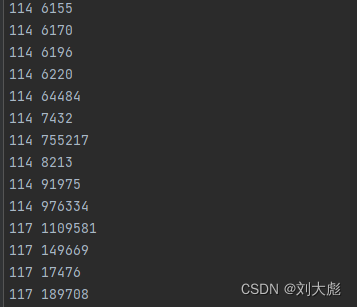
每行两个ID:<被引用论文ID><包含引用的论文>
前面先写,后面引用前面。
2.untils.py模块
代码块可以左右拖动查看全貌
import numpy as np
#调用第三方库numpy,简写为np,一般都是用的这种简写方式
import scipy.sparse as sp
#这是一个处理稀疏矩阵的第三方库,因为图神经网络中邻接矩阵和特征矩阵多为稀疏矩阵
import torch
#调用Pytorch第三方库
#定义一个One-Hot编码器函数,One-Hot编码可以查看CSDN里面我的一篇博客
def encode_onehot(labels):#传入参数是原始的标签集labels,类型为numpy.ndarray,大小为(2708,0),一个向量
classes = set(labels)#去重,只留下七种类别
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in
enumerate(classes)}#构造一个字典,每种类别对应一个One-Hot编码,编码长度为7
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)#把原标签集的类别全部转换为One-Hot编码
return labels_onehot#返回使用One-Hot编码后的结果
#加载数据集函数,该代码只用了Cora一个数据集
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
#idx_features_labels是一个numpy.ndarray类型的数据,大小为(2708,1435),
#2708是数据集中所有论文的数量,1435其实是1433(每篇论文的表示向量长度)+1(论文索引数字)+1(论文所属的类别)
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
#features是所有论文的特征矩阵,是一个稀疏矩阵,大小为(2708,1433),把idx_features_labels前面和后面去掉,剩下的就是特征
labels = encode_onehot(idx_features_labels[:, -1])
#labels是标签矩阵,类型为numpy.ndarray,大小为(2708,7),取idx_features_labels的最后一列,并用One-Hot编码,每一篇论文对应七种类型中的一种
#构造图
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
#取出每个节点的索引,即idx_features_labels的第一列,idx是numpy.ndarray,大小为(2708,),只有一行
idx_map = {j: i for i, j in enumerate(idx)}
#构造一个字典,因为本来的数据集中的论文索引数字不是按顺序从0开始的,而是一些不连续的数字组成的,现在把这些索引重新编排成从0开始依次递增的数字
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
#把cora.cites里面的信息提取出来作为图中边的信息
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
#再用前面定义好的idx_map字典把边的信息全部替换成重新编排好的数字
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
#定义邻接矩阵,这里的邻接矩阵是一个稀疏矩阵,大小为2708×2708,这里之所以用稀疏是因为只需要把有边的地方记为1,矩阵中其余位置都为零,明显看出矩阵中1的数量非常少,用常规的矩阵去存储会浪费内存
#Debug中adj.A可以查看该矩阵
#cora.cites中的链接是有向的,但是我们在处理引文数据集时都作为无向图处理,该公式就是把邻接矩阵改为无向图,也成为一个对称矩阵
# 若对该过程并不熟悉,可自行用一个小矩阵验证一系列操作
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
#对特征矩阵features进行归一化处理,归一化函数在前面定义过,可以按Ctrl键点击normalize查看
features = normalize(features)
#邻接矩阵加单位矩阵A+I,然后再进行归一化处理
adj = normalize(adj + sp.eye(adj.shape[0]))
#定义训练集,验证集,测试集,训练集140个节点(0-139),验证集300个节点(200-499),测试集1000个节点(500-1499)
#这里的编号就是前面排列好的idx_map
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
#将这几个数据类型都统一转换为torch中的张量
features = torch.FloatTensor(np.array(features.todense()))#转换为32位浮点数类型的张量
labels = torch.LongTensor(np.where(labels)[1])#转换为64位浮点数类型的张量
adj = sparse_mx_to_torch_sparse_tensor(adj)#将稀疏矩阵转化为torch中的稀疏张量
#索引数字也全部转换为张量
idx_train = torch.LongTensor(idx_train)#转换为64位浮点数类型的张量
idx_val = torch.LongTensor(idx_val)#转换为64位浮点数类型的张量
idx_test = torch.LongTensor(idx_test)#转换为64位浮点数类型的张量
#加载数据集函数返回邻接矩阵,特征矩阵,标签矩阵,训练集索引,验证集索引,测试集索引,全部都为张量类型
return adj, features, labels, idx_train, idx_val, idx_test
#对矩阵进行归一化处理
def normalize(mx):#矩阵归一化函数
rowsum = np.array(mx.sum(1))#首先对矩阵按行求和,rowsum大小为(2708,1)
r_inv = np.power(rowsum, -1).flatten()#求和后取倒数,r_inv大小为(2708,),flatten()函数将取倒数的结果平铺成一个一维向量
r_inv[np.isinf(r_inv)] = 0.#某行求和的结果可能为0,0取倒数为无穷大,我们将这种数据改为0
r_mat_inv = sp.diags(r_inv)#将r_inv转化为一个大小为(2708×2708)的对角矩阵,该矩阵除了对角线,其余位置都为0,对角线上的值就是r_inv的值
mx = r_mat_inv.dot(mx)#用对角矩阵与原矩阵相乘,即可得出矩阵归一化后的结果
return mx#函数返回归一化后的矩阵
#若对该过程并不熟悉,可自行用一个小矩阵验证一系列操作
#计算正确率
def accuracy(output, labels):#传入输出矩阵output和标签矩阵labels
preds = output.max(1)[1].type_as(labels)#取output中每个节点所在行的最大值为该节点的类别
correct = preds.eq(labels).double()#判断预测值和标签值是否一致,一致为1,不一致为0
correct = correct.sum()#累加得出所有预测正确的节点数量
return correct / len(labels)#预测正确的数量除以所有的节点数
#将一个稀疏矩阵转换为一个Tensor张量
def sparse_mx_to_torch_sparse_tensor(sparse_mx):#传入该稀疏矩阵,大小为(2708×2708)
sparse_mx = sparse_mx.tocoo().astype(np.float32)#将稠密矩阵转换为稀疏矩阵,并将数据类型都转换为32位浮点数
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
#取出矩阵中不为零元素所在的位置,组成一个(2×13264)的张量
values = torch.from_numpy(sparse_mx.data)#将稀疏矩阵里面的元素数据转换为张量
shape = torch.Size(sparse_mx.shape)#与原稀疏矩阵形状一致,都为(2708×2708)
return torch.sparse.FloatTensor(indices, values, shape)
#返回Tensor张量类型,三个参数:shape是矩阵的大小(2708,2708),indices是在转换后的矩阵中不为零的元素的位置,大小为(2×13264)
#说明该矩阵中共有13264个元素不为零,他们所处的位置就是两个长度为13264的向量相同位置的元素组成的坐标,values是indices中坐标对应位置的值,是一个一维的,长度为13264的向量
3.__init__.py模块
4.layers.py模块
5.train.py模块
6.models.py模块
后续我已经把全部的代码注释了一遍,可以帮助一些初学者更好的理解代码,发布在本人的GitHub:
未完,待更新。