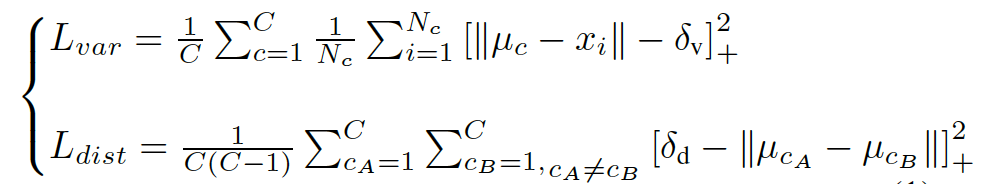2021-11-15 21:43:06.595835: I tensorflow/stream_executor/cuda/cuda_driver.cc:789] failed to allocate 2.20G (2363280384 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
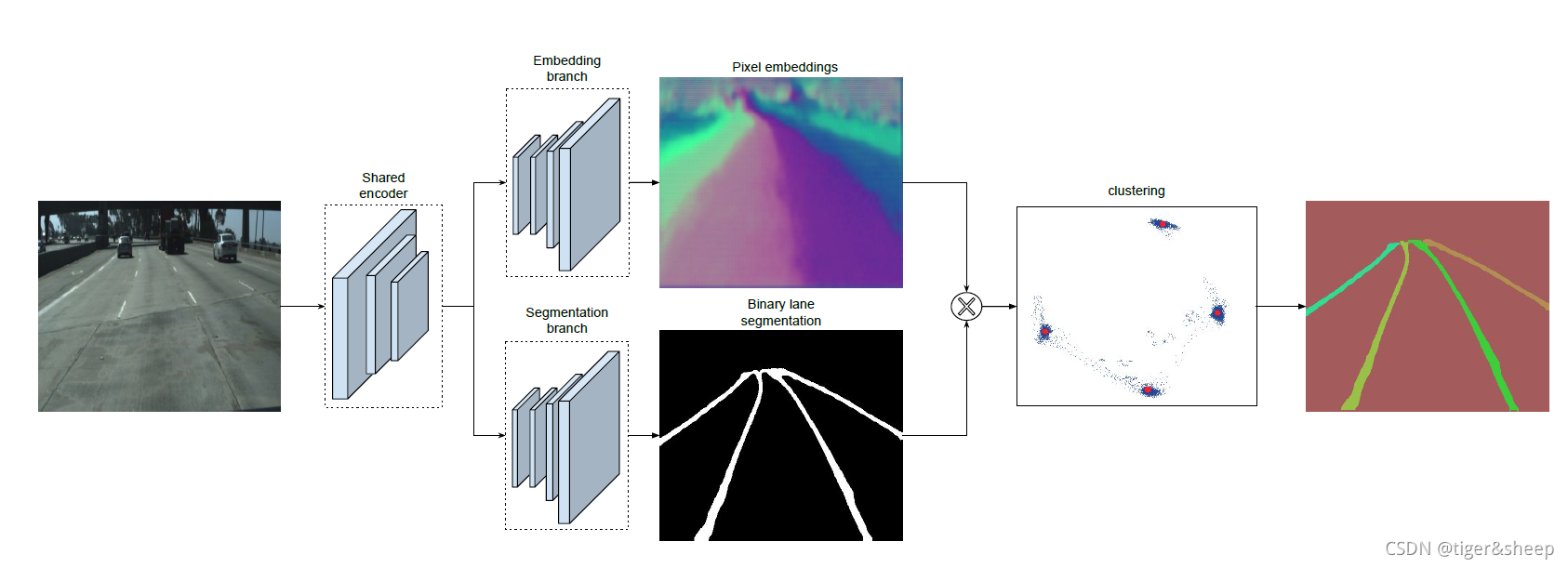
通过叠加嵌入分支和分割分支,在使用神经网络提取出车道线像素的同时,还能够对每个车道线实现聚类(即像素属于哪一根车道线)。为了训练这样的聚类嵌入网络,聚类损失函数(嵌入网络)包含两部分,方差项 L v a r L_{var}Lvar 和距离项 L d i s t L_{dist}Ldist ,其中 L v a r L_{var}Lvar 将每个嵌入的向量往某条车道线聚类中心(均值)方向拉,这种“拉力”激活的前提是嵌入向量到平均嵌入向量的距离过远,大于阈值 δ v \delta_vδv ; L d i s t L_{dist}Ldist 使两个类别的车道线越远越好,激活这个“推力”的前提是两条车道线聚类中心的距离过近,近于阈值 δ d \delta_dδd 。最后总的损失函数L的公式如下:
其中 C CC 表示聚类的数量(也就是车道线的数量),N c N_cNc 表示聚类 c cc 中的元素数量,x i x_ixi 表示一个像素嵌入向量, μ c \mu_{c}μc 表示聚类 c cc 的均值向量,[ x ] + = m a x ( 0 , x ) [x]_{+} = max(0, x)[x]+=max(0,x),最后的损失函数为 L = L v a r + L d i s t L = L_{var} + L_{dist}L=Lvar+Ldist 。该损失函数在实际实现(TensorFlow)中代码如下:
2. H-Net网络架构
1. generate_tusimple_dataset.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 18-5-18 下午7:31
# @Author : MaybeShewill-CV
# @Site : https://github.com/MaybeShewill-CV/lanenet-lane-detection
# @File : generate_tusimple_dataset.py
# @IDE: PyCharm Community Edition
"""
generate tusimple training dataset
"""
import argparse
import glob
import json
import os
import os.path as ops
import shutil
import sys
sys.path.append(os.getcwd())
import cv2
import numpy as np
def init_args():
"""
:return:
"""
parser = argparse.ArgumentParser()
parser.add_argument('--src_dir', type=str, help='The origin path of unzipped tusimple dataset')
return parser.parse_args()
def process_json_file(json_file_path, src_dir, ori_dst_dir, binary_dst_dir, instance_dst_dir):
"""
:param json_file_path:
:param src_dir: origin clip file path
:param ori_dst_dir:
:param binary_dst_dir:
:param instance_dst_dir:
:return:
"""
assert ops.exists(json_file_path), '{:s} not exist'.format(json_file_path)
image_nums = len(os.listdir(ori_dst_dir))
with open(json_file_path, 'r') as file:
for line_index, line in enumerate(file):
info_dict = json.loads(line)
image_dir = ops.split(info_dict['raw_file'])[0]
image_dir_split = image_dir.split('/')[1:]
image_dir_split.append(ops.split(info_dict['raw_file'])[1])
image_name = '_'.join(image_dir_split)
image_path = ops.join(src_dir, info_dict['raw_file'])
assert ops.exists(image_path), '{:s} not exist'.format(image_path)
h_samples = info_dict['h_samples']
lanes = info_dict['lanes']
image_name_new = '{:s}.png'.format('{:d}'.format(line_index + image_nums).zfill(4))
src_image = cv2.imread(image_path, cv2.IMREAD_COLOR)
dst_binary_image = np.zeros([src_image.shape[0], src_image.shape[1]], np.uint8)
dst_instance_image = np.zeros([src_image.shape[0], src_image.shape[1]], np.uint8)
for lane_index, lane in enumerate(lanes):
assert len(h_samples) == len(lane)
lane_x = []
lane_y = []
for index in range(len(lane)):
if lane[index] == -2:
continue
else:
ptx = lane[index]
pty = h_samples[index]
lane_x.append(ptx)
lane_y.append(pty)
if not lane_x:
continue
lane_pts = np.vstack((lane_x, lane_y)).transpose()
lane_pts = np.array([lane_pts], np.int64)
cv2.polylines(dst_binary_image, lane_pts, isClosed=False,
color=255, thickness=5)
cv2.polylines(dst_instance_image, lane_pts, isClosed=False,
color=lane_index * 50 + 20, thickness=5)
dst_binary_image_path = ops.join(binary_dst_dir, image_name_new)
dst_instance_image_path = ops.join(instance_dst_dir, image_name_new)
dst_rgb_image_path = ops.join(ori_dst_dir, image_name_new)
cv2.imwrite(dst_binary_image_path, dst_binary_image)
cv2.imwrite(dst_instance_image_path, dst_instance_image)
cv2.imwrite(dst_rgb_image_path, src_image)
print('Process {:s} success'.format(image_name))
def gen_train_sample(src_dir, b_gt_image_dir, i_gt_image_dir, image_dir):
"""
generate sample index file
:param src_dir:
:param b_gt_image_dir:
:param i_gt_image_dir:
:param image_dir:
:return:
"""
with open('{:s}/training/train.txt'.format(src_dir), 'w') as file:
for image_name in os.listdir(b_gt_image_dir):
if not image_name.endswith('.png'):
continue
binary_gt_image_path = ops.join(b_gt_image_dir, image_name)
instance_gt_image_path = ops.join(i_gt_image_dir, image_name)
image_path = ops.join(image_dir, image_name)
assert ops.exists(image_path), '{:s} not exist'.format(image_path)
assert ops.exists(instance_gt_image_path), '{:s} not exist'.format(instance_gt_image_path)
b_gt_image = cv2.imread(binary_gt_image_path, cv2.IMREAD_COLOR)
i_gt_image = cv2.imread(instance_gt_image_path, cv2.IMREAD_COLOR)
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
if b_gt_image is None or image is None or i_gt_image is None:
print('图像对: {:s}损坏'.format(image_name))
continue
else:
info = '{:s} {:s} {:s}'.format(image_path, binary_gt_image_path, instance_gt_image_path)
file.write(info + '\n')
return
def process_tusimple_dataset(src_dir):
"""
:param src_dir:
:return:
"""
traing_folder_path = ops.join(src_dir, 'training')
testing_folder_path = ops.join(src_dir, 'testing')
os.makedirs(traing_folder_path, exist_ok=True)
os.makedirs(testing_folder_path, exist_ok=True)
for json_label_path in glob.glob('{:s}/label*.json'.format(src_dir)):
json_label_name = ops.split(json_label_path)[1]
shutil.copyfile(json_label_path, ops.join(traing_folder_path, json_label_name))
for json_label_path in glob.glob('{:s}/test*.json'.format(src_dir)):
json_label_name = ops.split(json_label_path)[1]
shutil.copyfile(json_label_path, ops.join(testing_folder_path, json_label_name))
gt_image_dir = ops.join(traing_folder_path, 'gt_image')
gt_binary_dir = ops.join(traing_folder_path, 'gt_binary_image')
gt_instance_dir = ops.join(traing_folder_path, 'gt_instance_image')
os.makedirs(gt_image_dir, exist_ok=True)
os.makedirs(gt_binary_dir, exist_ok=True)
os.makedirs(gt_instance_dir, exist_ok=True)
for json_label_path in glob.glob('{:s}/*.json'.format(traing_folder_path)):
process_json_file(json_label_path, src_dir, gt_image_dir, gt_binary_dir, gt_instance_dir)
gen_train_sample(src_dir, gt_binary_dir, gt_instance_dir, gt_image_dir)
return
if __name__ == '__main__':
args = init_args()
process_tusimple_dataset(args.src_dir)